
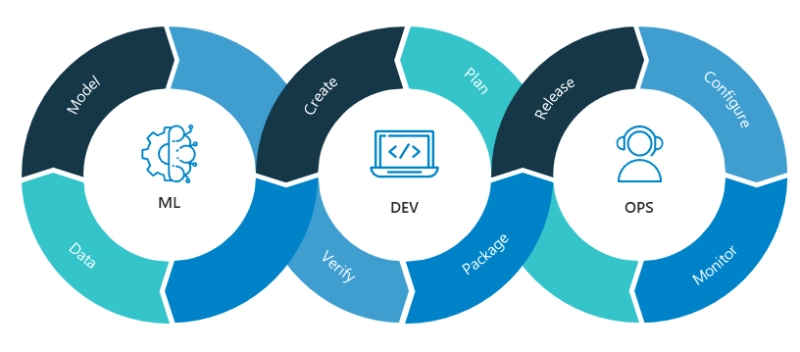
What is MLOPS?
MLOps, or Machine Learning Operations, refers to the practices and tools used to enable the automated deployment, monitoring, and management of machine learning models in production. With the increasing use of machine learning in businesses, MLOps has become a crucial aspect of building and managing ML applications.
Why we need MLOPS?
There are several reasons why we need MLOps:
1. Scalability: MLOps provides a way to scale machine learning workflows to support large-scale production deployments. With MLOps, you can automate the process of building, testing, and deploying models, enabling you to quickly and efficiently deploy new models as needed.
2. Efficiency: MLOps helps improve the efficiency of machine learning workflows by streamlining processes and automating repetitive tasks. This allows data scientists to spend more time on the creative aspects of model building, rather than on routine tasks.
3. Consistency: By using MLOps, you can ensure that machine learning models are consistently produced and deployed in a standardized and reproducible manner. This helps reduce errors and improve the reliability of the models.
4. Collaboration: MLOps encourages collaboration between data scientists, developers, and operations teams, enabling them to work together on the same codebase and to share best practices and knowledge.
5. Security: MLOps includes security and compliance considerations throughout the machine learning workflow, ensuring that models are secure and comply with relevant regulations and standards.
6. Governance: MLOps helps you manage machine learning models throughout their entire lifecycle, including tracking and auditing changes, ensuring that they are transparent and explainable, and maintaining version control.
Overall, MLOps is essential for deploying and managing machine learning models in a reliable, efficient, and scalable manner.It enables organizations to accelerate the development and deployment of machine learning models, while ensuring that they are consistent, secure, and compliant with relevant regulations and standards.
Popular Tools for MLOps on Cloud Platforms:
Kubeflow: Kubeflow is an open-source platform that provides tools for building, deploying, and managing machine learning workflows on Kubernetes. It supports popular ML frameworks like TensorFlow and PyTorch.
Amazon SageMaker: Amazon SageMaker is a fully managed service that provides tools for building, training, and deploying machine learning models. It supports popular ML frameworks like TensorFlow, PyTorch, and Apache MXNet.
Google Cloud AI Platform: Google Cloud AI Platform provides a comprehensive set of tools for building, training, and deploying machine learning models. It supports popular ML frameworks like TensorFlow and scikit-learn.
Microsoft Azure Machine Learning: Microsoft Azure Machine Learning provides tools for building, training, and deploying machine learning models. It supports popular ML frameworks like TensorFlow, PyTorch, and scikit-learn.
Stepwise procedure to perform MLOPS on above platforms –
MLOps on Kubeflow:
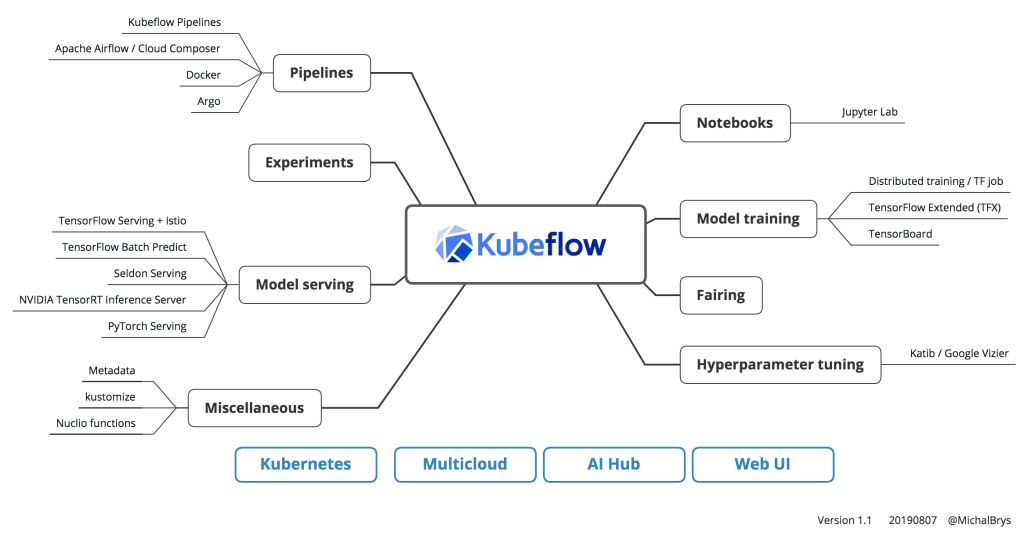
1. Set up a Kubernetes cluster: The first step is to set up a Kubernetes cluster on your preferred cloud platform, such as AWS, GCP, or Azure.
2. Install Kubeflow: Once the Kubernetes cluster is set up, you need to install Kubeflow, which is an open-source platform for deploying and managing machine learning workflows on Kubernetes. You can install Kubeflow using the command-line interface (CLI) or the Kubeflow UI.
3. Prepare the data: Before you can train your model, you need to prepare your data. This involves gathering and cleaning the data, as well as splitting it into training, validation, and test sets.
4.Develop the model: Once the data is prepared, you need to develop your machine learning model. This involves selecting an appropriate algorithm and tuning its hyperparameters.
5. Train the model: After the model is developed, you need to train it on the training data. You can do this using Kubeflow Pipelines, which is a component of Kubeflow that provides a way to create, run, and manage machine learning workflows.
6. Deploy the model: Once the model is evaluated and ready to deploy, you need to deploy it on Kubeflow. You can do this using Kubeflow Serving, which is a component of Kubeflow that provides a way to deploy and serve machine learning models as REST APIs.
7. Monitor and manage the model: After the model is deployed, you need to monitor its performance and make any necessary updates. This involves setting up monitoring tools like Kubeflow Metadata and Kubeflow Tensor Board.
8. Continuous integration and continuous delivery (CI/CD): The final step is to set up a CI/CD pipeline for your model. This involves automating the process of building, testing, and deploying the model using tools like Kubeflow Fairing and Kubeflow Argo.
MLOps on AWS
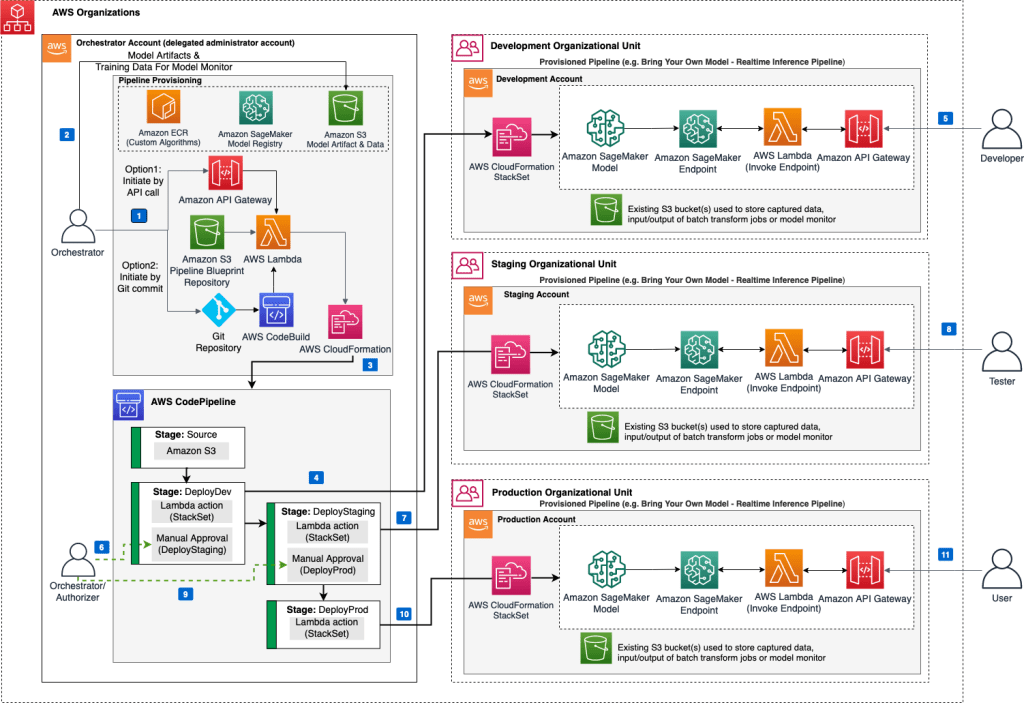
1. Pre-process and Prepare the Data with Aws Data Wrangler: Once the data is collected, pre-process and prepare it for use in training and testing the ML model. This may involve cleaning, filtering, transforming, and aggregating the data.
2. Create an Amazon SageMaker Notebook Instance: After preparing the data, create an Amazon SageMaker notebook instance to develop and test the ML model. You can choose from various instance types and sizes based on your needs.
3. Develop and Train the Model: Use the notebook instance to develop and train the ML model. Amazon SageMaker supports popular ML frameworks like TensorFlow, PyTorch, and scikit-learn. Use the built-in algorithms or bring your own custom algorithms to train the model on the prepared data.
4. Deploy the Model: After training the model, deploy it to a production environment. Use Amazon SageMaker’s built-in deployment options or customize your deployment to meet your specific requirements.
5. Monitor and Manage the Model: Once the model is deployed, monitor its performance and make necessary adjustments to optimize its performance. Amazon SageMaker provides built-in monitoring tools to help you monitor model performance, detect errors, and troubleshoot issues.
6. Update the Model: As new data becomes available, update the ML model to improve its accuracy and effectiveness. You can retrain the model using the new data and deploy the updated version to the production environment.
7. Scale and Manage the Infrastructure: Finally, scale and manage the infrastructure to support the ML model. Amazon SageMaker provides various options for managing the infrastructure, including auto-scaling, automated backups, and disaster recovery.
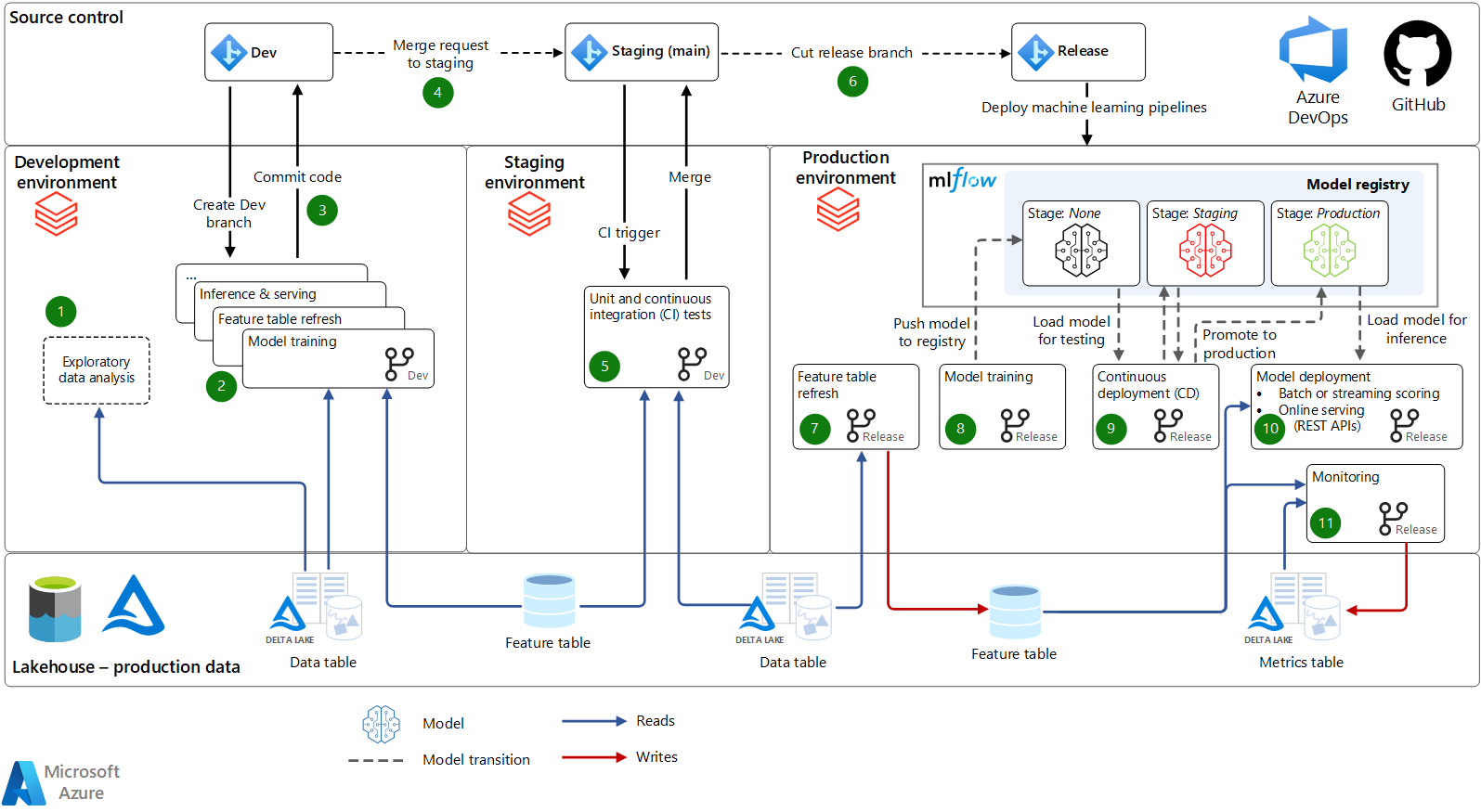
MLOPS on Microsoft Azure:
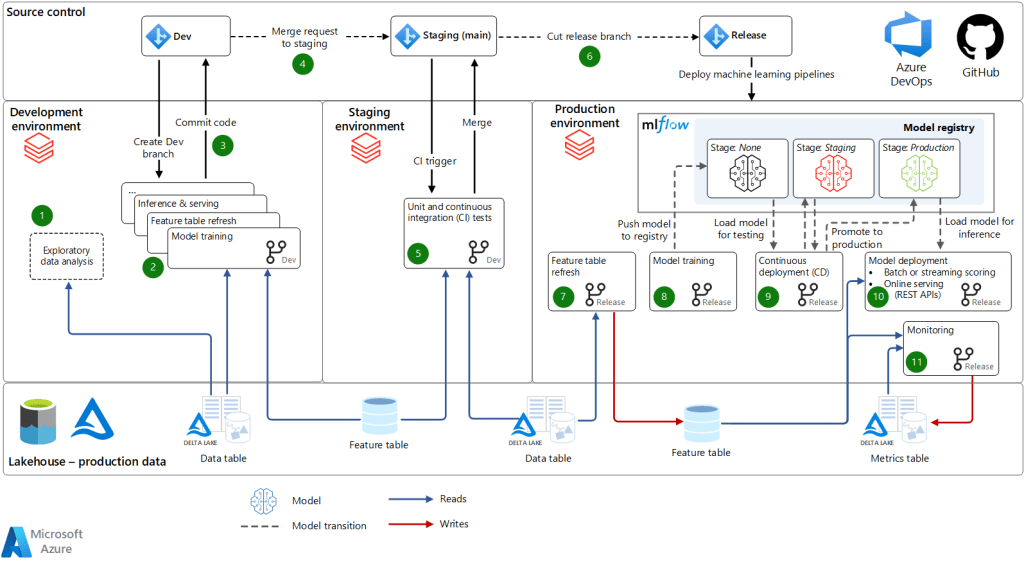
1. Workspace Creation : Create an Azure Machine Learning workspace. This is the central location where you will store and manage all your machine learning artifacts, such as data sets, models, and experiments.
2. Development pipeline Creation : Define your machine learning pipeline using Azure Machine Learning Designer or Azure Machine Learning SDK. Your pipeline should include all the steps necessary to train, validate, and deploy your model, such as data preparation, model training, and evaluation.
3. Deployment Pipeline Creation : Create a release pipeline in Azure DevOps that deploys your machine learning pipeline to the Azure Machine Learning workspace. The release pipeline should include all the necessary steps to build, package, and deploy your machine learning model to production.
4. CICD Pipeline Setup – Set up continuous integration and continuous deployment (CI/CD) using Azure DevOps. This will automate the process of building, testing, and deploying your machine learning model to production whenever there are changes in your code or data.
5 . Monitoring – Monitor your model in production using Azure Machine Learning Designer or Azure Machine Learning SDK. This will help you detect issues and track the performance of your model over time. Iterate and improve your model as necessary based on the feedback you receive from monitoring and other sources.
MLOPS on GCP :

1. Data Preparation : Organize your data and make sure it is in a format that can be easily used by machine learning algorithms. Perform data cleaning, transformation, and normalization as needed. Split your data into training, validation, and testing sets.
2. Framework Selection : Choose a machine learning framework or library such as TensorFlow, PyTorch, or scikit-learn to develop your model. Train your model on your training data using your chosen machine learning framework or library. Optimize your model by experimenting with different hyperparameters and tuning them for better performance.
3. Deployment : Deploy your trained model to Google Vertex AI by creating a model resource and uploading your saved model artifacts.
4. Testing : Use the deployed model to make predictions on your test data. Evaluate the performance of your model using metrics such as accuracy, precision, recall, and F1 score. Identify areas where your model is performing poorly and make improvements by tweaking your model, changing your hyperparameters, or gathering more training data.
5. Monitoring : Monitor your model’s performance over time using monitoring tools provided by Google Vertex AI. Set up alerts to notify you when your model’s performance drops below a certain threshold. Use the feedback from monitoring and testing to update and improve your model regularly. Re-deploy your updated model to Google Vertex AI.
5. Automation : Use automation tools such as Google Cloud Build, Google Cloud Composer, and Kubeflow to automate your MLOps workflow. Build a CI/CD pipeline that automates the process of training, testing, deploying, and updating your machine learning models. Continuously monitor your pipeline and make improvements to it as needed.
Future of MLOPS:
The future of MLOps is incredibly bright, as the demand for machine learning models continues to grow across various industries. MLOps is evolving rapidly, and we can expect to see many exciting developments in the near future. Here are some of the trends and directions we can expect for MLOps in the coming years:
1. Increased Automation: As more businesses adopt machine learning, the need for automation in MLOps will increase. This will lead to more tools that automate various aspects of the MLOps workflow, from data preparation to model deployment.
2. Model Explainability and Interpretability: With the increasing adoption of machine learning models, there is a growing need for transparency and accountability. This has led to a focus on model explainability and interpretability, which will continue to be a crucial area of development for MLOps in the future.
3. Cloud-Based MLOps: Cloud platforms will continue to be the preferred choice for MLOps, as they offer scalability, cost-effectiveness, and flexibility. We can expect to see more tools and services for MLOps in the cloud, as well as greater integration with popular cloud platforms like AWS, Google Cloud, and Microsoft Azure.
4. DevOps and MLOps Integration: The integration of MLOps with DevOps will become more prevalent, as businesses look to streamline their software development and deployment processes. This will lead to the development of new tools and methodologies that merge the best practices of DevOps and MLOps.
5. Reinforcement Learning: Reinforcement learning is an area of machine learning that involves training models to make decisions based on feedback from their environment. This has many potential applications, such as robotics, gaming, and autonomous vehicles. We can expect to see more development in this area and more MLOps tools for reinforcement learning.
Overall, the future of MLOps is bright, and we can expect to see continued growth and development in this field.
As machine learning becomes more prevalent across various industries, MLOps will continue to play a critical role in building and deploying high-quality machine learning models.


{kind=link}
{kind=link}