

Traditional ETLs :
Earlier days of ETL (Extract -> Transform -> Load ) were only used for several applications, Such as :
- Data Warehousing: copy main application data to data warehouses, storing transactions/ records added way back in past, etc.
- Data migration: bulk copy of data from one database to another or moving from on-premise to cloud, etc.
- Data loading: loading a huge amount of data to the database (product go live ), etc.
Traditional ETL scripts are used to migrate the data from one/many sources to one/many targets
Problems with Traditional ETLs:
- High Velocity and Growing Data: Enterprises today are facing high velocity and growing volumes of data that traditionally coded ETLs are not able to handle, they lack Scalability.
- Diverse Data Format and Data Sources: There are different types of data sources ( most popular cloud data sources ) and different data formats available in enterprises today which traditionally coded ETLs require a lot of changes while moving to a new data source.
- Corruption of data: If you feed traditional ETLs with Structured, Semi-structured, Unstructured data at the same time, ETL will fail.
- Faults handling and Performance issues: The traditional ETLs works on the approach of all or none, basically corrupted data or files breaks the entire ETL, So there’s a need to checkpointing/Bookmark the data processed till encountered the corrupted data so that after removal of corrupted data ETL can resume from the checkpoint.
- Unifying Batch and streaming data sources: Traditional ETLs lacks in processing streaming data sources which is now a big business requirement, ETLs should be able to unify batch processing and streaming data.
- Connectors /Extensions to connect to latest data sources: There should be a way to connect to modern sources like google big query quickly without many changes in the code.
- User-Defined functions, Visualization and ML libraries: Visualization after the cleaning of data is need of the hour, ETLs should be able to execute user-defined functions and use them as the same process as the inbuild functions provided. Modern ETL tools provide ML libraries that were not there in the traditional ETLs.
Modern ETL Architecture:
The above requirements changed the traditional ETL architecture which comprised of three major blocks: Core ETL functions, Enterprise readiness, and Processing engine to below extended architecture today:

- Core ETL Functions: core ETL functions are the operations that provide connectors are source and sink, modern ETLs need to connect to cloud sources like (Amazon S3, Amazon RDS, JDBC data sources, files, etc. It is also equipped with functions that act as transformations that help in joining the data from various data sources, executing SQL queries on the data as data frames, perform reduce functions, will be able to create custom transformation code in java/scala/python, etc. Modern-day ETLs also have ML functions working as transformations. Modern ETL tools also use Data Catalog (Metadata about databases) to connect to data sources and data sink. This component also has the information of where the staging data resides.
- Processing Engine: processing engine is the backbone of ETL. It is also responsible for executing the configurations of ETL, configurations can be related to the processing of data in a sequential or parallel manner, in-memory, cache and IO operation of disk-based on certain logic, In memory allocation and optimization parameters, file processing information, distribution, and partitioning of data.
- Enterprise Readiness: Enterprise readiness block refers to key functionality needed by any tool to get adapted in any enterprise for example security, alerting, monitoring, etc.
Modern ETL requirements:
- Data profiling, blending, and cleansing.
- Integration and Orchestration (ex: AWS Glue job with AWS Step functions )
- Data Science and Analysis.
- Unified batch and real-time processing.
- User-defined function / transformations and reusability.
- Ability to integrate with latest technologies/ data source/ data sink.
Why Apache Spark:
Apache Spark is a unified analytics engine for large-scale data processing. It is able to process big data at a tremendous speed and very proficient in ETL tasks. Apache spark has the following advantages :
- Open-source
- Highly Scalable
- Unified API
- Multi-language support : java/python/r/scala
- connectors for numerous sources and targets to read and write
- Machine learning support
Spark has connectors to connect to various data sources shown below :

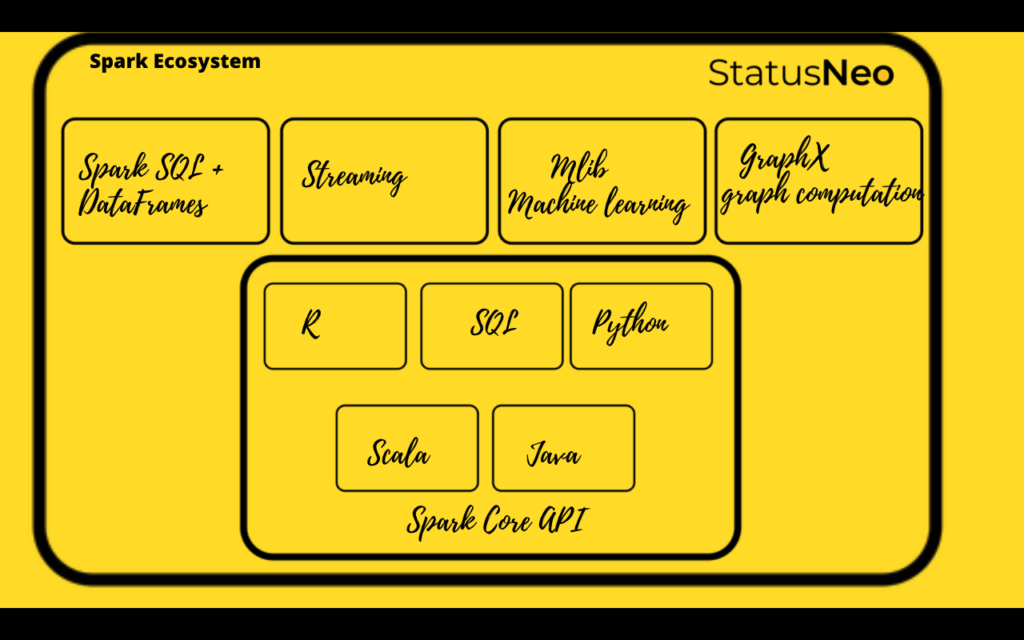
Spark Ecosystem comprises of:
Structured Data: Spark SQL
Many data scientists, analysts, and general business intelligence users rely on interactive SQL queries for exploring data. Spark SQL is a Spark module for structured data processing. It provides a programming abstraction called DataFrames and can also act as distributed SQL query engine. It enables unmodified Hadoop Hive queries to run up to 100x faster on existing deployments and data. It also provides powerful integration with the rest of the Spark ecosystem (e.g., integrating SQL query processing with machine learning).
Streaming Analytics: Spark Streaming
Many applications need the ability to process and analyze not only batch data but also streams of new data in real-time. Running on top of Spark, Spark Streaming enables powerful interactive and analytical applications across both streaming and historical data, while inheriting Spark’s ease of use and fault tolerance characteristics. It readily integrates with a wide variety of popular data sources, including HDFS, Flume, Kafka, and Twitter.
Machine Learning: MLib
Machine learning has quickly emerged as a critical piece in mining Big Data for actionable insights. Built on top of Spark, MLlib is a scalable machine learning library that delivers both high-quality algorithms (e.g., multiple iterations to increase accuracy) and blazing speed (up to 100x faster than MapReduce). The library is usable in Java, Scala, and Python as part of Spark applications to include it in complete workflows.
Graph Computation: GraphX
GraphX is a graph computation engine built on top of Spark that enables users to interactively build, transform and reason about graph-structured data at scale. It comes complete with a library of common algorithms.
General Execution: Spark Core
Spark Core is the underlying general execution engine for the Spark platform that all other functionality is built on top of. It provides in-memory computing capabilities to deliver speed, a generalized execution model to support a wide variety of applications, and Java, Scala, and Python APIs for ease of development.
Apache spark is very proficient in ETL tasks and has a lot of people contributing to it, It is able to justify the Modern ETL architecture required. Many of the cloud service providers are creating their products where they are using apache spark as a service.
Reference: spark definition and spark Ecosystem (https://spark.apache.org/)

Shrikant Gourh
Senior Consultant at StatusNeo


