In this blog, let us see what locators are and how that help in providing end-to-end automation using Selenium WebDriver.
What are these locators and why do we need them?
Anything that is present on the web page is a WebElement be it an edit box, button, dropdown, link, etc. As a part of automation, Selenium performs actions such as clicking and typing on the WebElements which basically represents Page HTML Elements. Locators are a way to identify an HTML element on the web page.
Suppose you want to enter sign-in details on a webpage, so if we want selenium to perform this operation, selenium has to come and enter the email in the email edit box, but how does Selenium WebDriver know that it has to enter the email in this particular edit box, somebody has to tell the address where this edit box is present on this entire HTML page. So, that’s where locators come into the picture. Locators will tell you where the HTML component is located. Similarly, if you want to click on any button, then there will be one locator which will help us to uniquely identify the button on the webpage. Then selenium performs different actions like clicking, typing, etc. on those web elements.
In Automation, there are some important parameters for scripting, and if they end up being incorrect, then it may lead to script failure. A good scripting base requires elements to be located appropriately. For this, Selenium WebDriver uses any of the following locators to identify the element on the page and perform the required action.
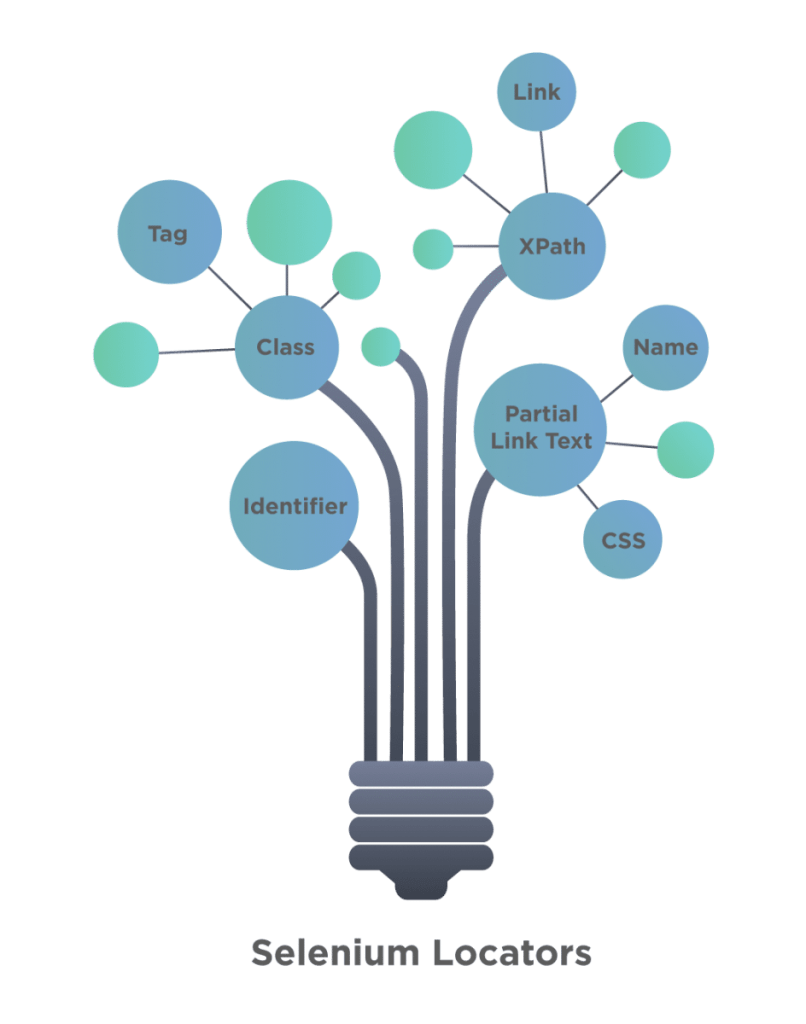
- ID
- Name
- Tag Name
- Class Name
- CSS Selector
- Link Text
- Partial Link Text
- XPath
We can choose any one of these locators to identify the HTML element on the webpage. It’s not mandatory that every element on the page have all these locators, suppose for a button, there could be an ID locator or CSS. We have to uniquely identify which locator is unique and can be easily accessible, we have to find that locator and write the same in selenium code.
How to locate Web Elements in the Document object model?
Firstly, open the web application, then right-click on it and select ‘Inspect’, developer’s tool window will open.
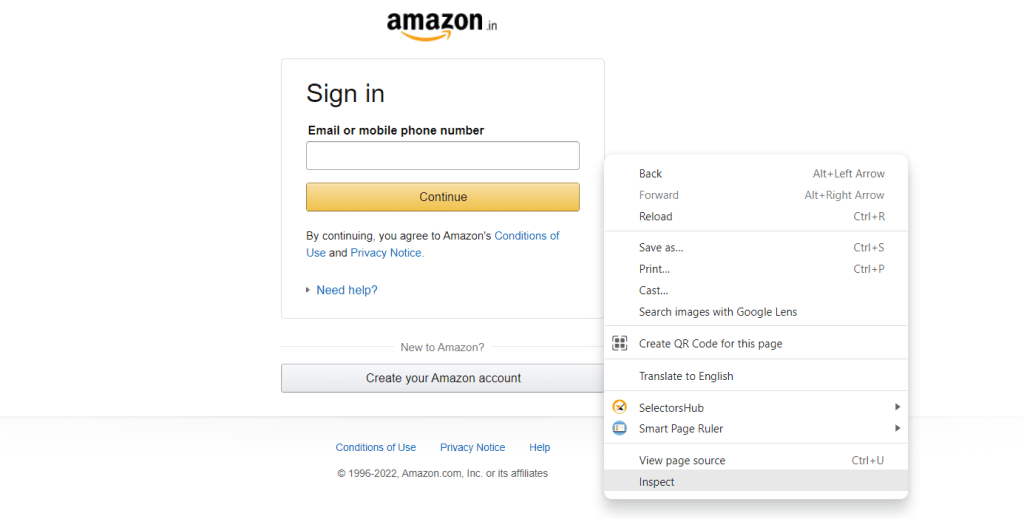
Then either click on the ‘select element’ icon or press ‘Ctrl+Shift+C’ and navigate to the element you wish to locate. Once you click on the element, DOM would be highlighted for that web element.
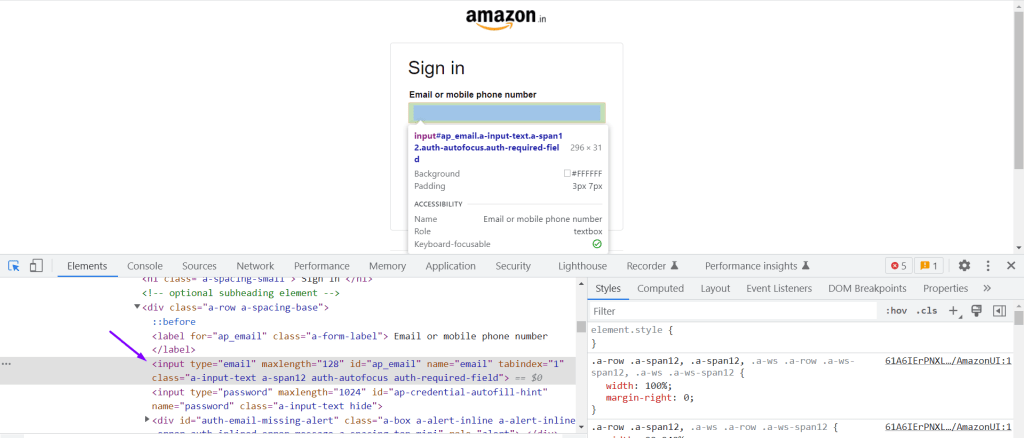
From the highlighted row, we will use different attributes to locate that web element.
For every HTML element, you will have some code information like this:
<input type=”email” maxlength=”128″ id=”ap_email” name=”email” tabindex=”1″ class=”a-input-text a-span12 auth-autofocus auth-required-field”>
Tag name – input
Attributes – type, maxlength, name, tabindex, class
Values associated with the attributes – quoted in double quotes with the attribute names
By looking at this HTML code, we can say there are 6 attributes present for that edit box which are type, maxlength, id, name, tabindex, and class. And tag name for the web element is input. With this information, we will construct the locator.
1) ID
ID is the simplest locator to locate web elements. IDs are unique for all web elements.
Suppose you need to enter your email address into the Email field, for that you need to inspect that particular text-box web element.
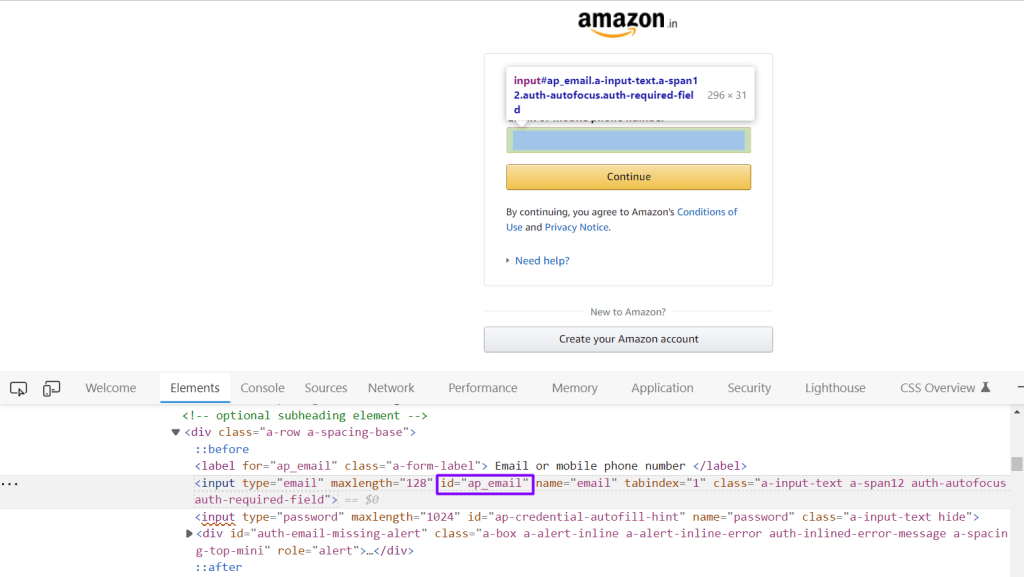
Now, using this HTML information, we should be able to extract the locators.
<input type=”email” maxlength=”128″ id=”ap_email” name=”email” tabindex=”1″ class=”a-input-text a-span12 auth-autofocus auth-required-field”>
As selenium supports an ID locator, so here we have one ID, in HTML terms, we call it an attribute, in selenium, we call it a locator. Using that ID, we can uniquely identify the edit box.
Let’s see how can we use this to the input email address in that edit box.
Selenium: driver.findElement(By.Id(“ap_email”)).sendKeys(“[email protected]”);
But here’s a point to remember, if there is an alphanumeric or numeric value present in the ID, then there are possibilities that it can change on page refresh, so make sure to re-check the ID before using it.
2) Name
Another attribute that can be used to identify a web element is ‘Name’, in a similar way like we used ID to identify the web element.
But, unlike ID, which is unique for a web page, the name locator may or may not have a unique value, so in such case, if there is more than one web element, using the name locator will select the first element on the page having the same locator name.

Suppose, you don’t find ID directly given in the HTML code, then we will try to find some other locator options to identify the web element uniquely.
<input type=”email” maxlength=”128″ id=”ap_email” name=”email” tabindex=”1″ class=”a-input-text a-span12 auth-autofocus auth-required-field”>
Here, we have a locator ‘name’. So, we can use it directly in our selenium code.
Selenium: driver.findElement(By.name(“email”)).sendKeys(“[email protected]”);
3) Tag Name
As the name specifies, use the tag name directly to locate the web elements. Tag names like div, input, table, h1, etc.
Basically, the tag name locator is mostly used to locate all the anchor tags available on a web page.
Syntax of locating all links on a web page, as links are created using anchor <a> tag:
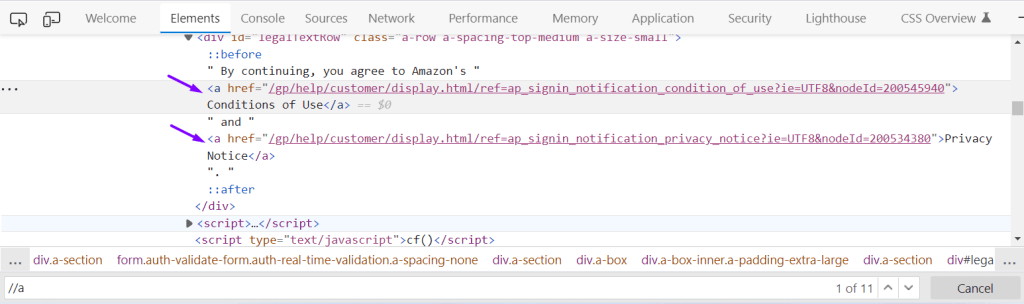
Selenium: driver.find elements(By.tagName(“a”));
4) Class Name
The class name is used to locate the web elements using the class attribute.
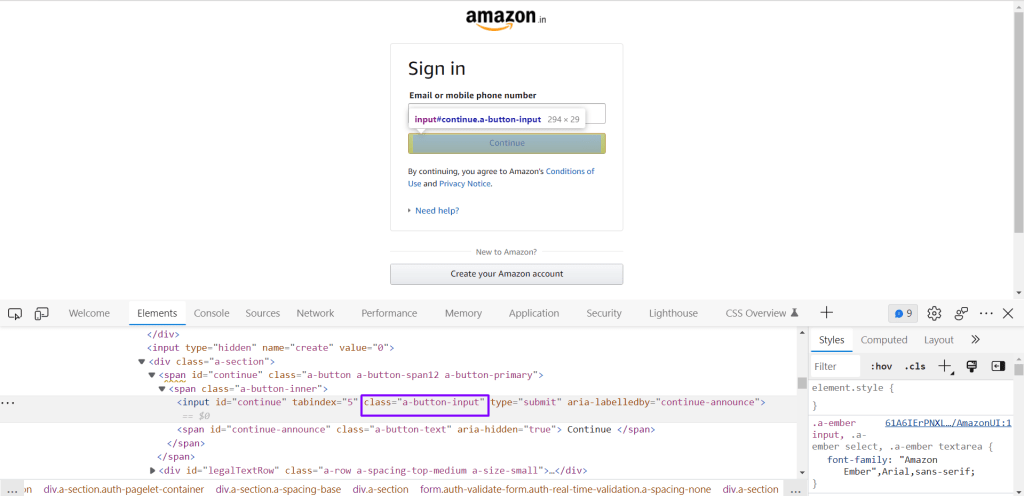
<input id=”continue” tabindex=”5″ class=”a-button-input” type=”submit” aria-labelledby=”continue-announce”>
We can use the class name directly here to perform the click action on the button:
Selenium: driver.findElement(By.classname(“a-button-input”)).click();
But there is a restriction here, compound class names are not permitted to use directly. The compound class names are the ones that have spaces in between. We cannot use a compound class name directly using this attribute, in such case we should either use some other unique attribute or we can create XPath out of it using that compound class name. Let’s see what compound class names look like:

5) CSS Selector
CSS selector is the fastest locator to locate web elements in the DOM. Unlike, ID, Name, and Class name where direct one-on-one mappings were there to directly use them to locate web elements, this is a type of locator that you need to construct from the given HTML code.
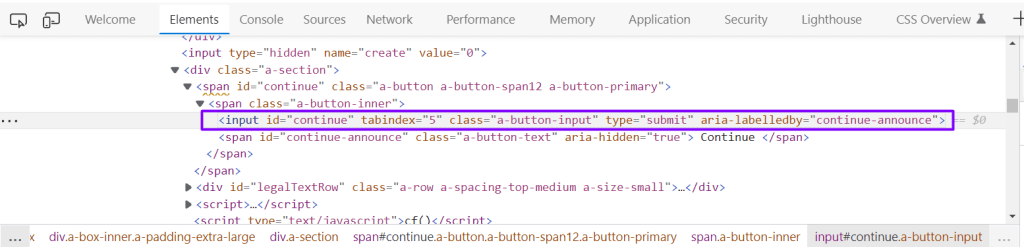
HTML: <input id=”continue” tabindex=”5″ class=”a-button-input” type=”submit” aria-labelledby=”continue-announce”>
If you have a class name, Syntax for creating CSS selector: Tagname.classname
CSS Selector: input.a-button-input
Selenium: driver.findElement(By.cssSelector(“input.a-button-input “));
We can also use a class name directly followed by a dot, but the condition is that the classname should be unique in DOM.
CSS Selector: .a-button-input
Selenium: driver.findElement(By.cssSelector(“.a-button-input “));
Even if you have compound class names in such cases use the same syntax just replace the space with a dot.
HTML: <input type=”email” maxlength=”128″ id=”ap_email” name=”email” tabindex=”1″ class=”a-input-text a-span12 auth-autofocus auth-required-field”>
CSS Selector: input.a-input-text.a-span12.auth-autofocus.auth-required-field
If you have Id, Syntax for creating CSS selector: Tagname#id
CSS Selector: input#continue
Selenium: driver.findElement(By.cssSelector(“input#continue”));
Similarly, we can also use an Id directly followed by a dot, if that Id should be unique in DOM.
CSS Selector: #continue
Selenium: driver.findElement(By.cssSelector(“#continue”));
What if that HTML does not have a class name or Id, then how will you write a CSS selector? So, for that we have some generic CSS:
Syntax: tagname[attribute=’value’]
For example, the HTML code is as follows:
<input type=”text” placeholder=”Username” value=” “>
CSS Selector: input[placeholder=’Username’]
driver.findElement(By.cssSelector(“input[placeholder=’Username’]”));
In order to validate, if the CSS locator you constructed is unique or gives multiple results, you can check from browser developer tools.
Also, there are good plugins available like SelectorsHub and Chropath which will help you to validate if the CSS selector you wrote is unique or giving multiple results.
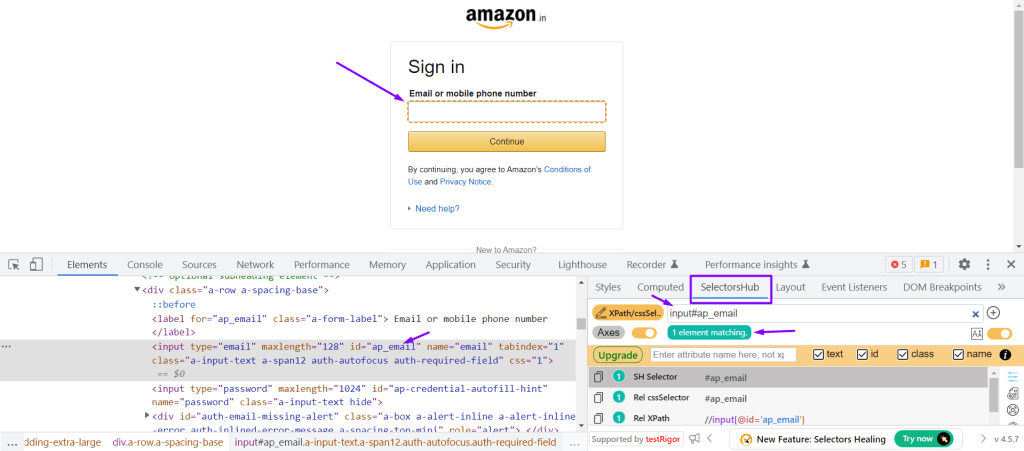
SelectorsHub: Add this plugin and restart your browser and you will start to see the option of SelectorsHub in your developer’s tool window.
Click on the SelectorsHub tab, type any CSS selector value and click enter, it will simply display the count of matching elements for that CSS.
6) Link Text
If there are links present on the web page, then we can directly locate them by using the link texts, but if the specified link text locator returns duplicate results, then it will return the first matching web element. This strategy can only be used for the elements that have anchor <a> tag.
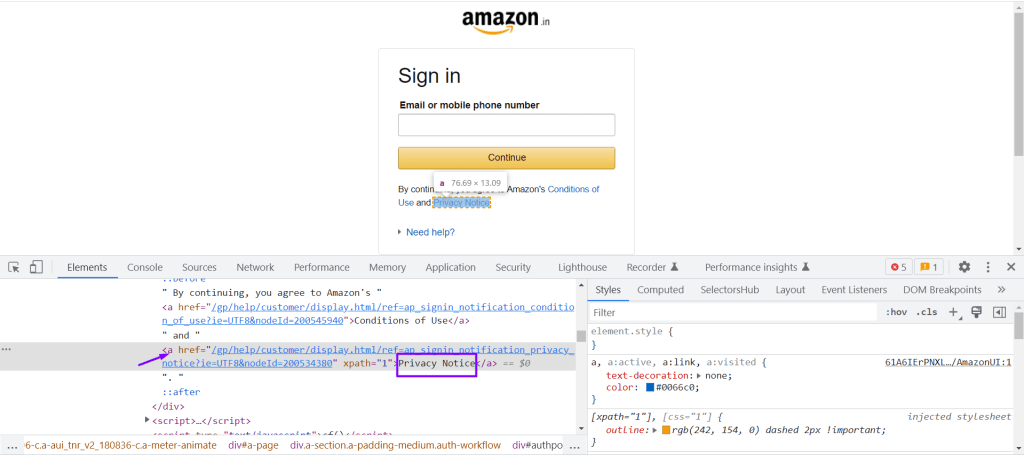
DOM Structure:
<a href=”/gp/help/customer/display.html/ref=ap_signin_notification_privacy_notice?ie=UTF8&nodeId=200534380″ xpath=”1″>Privacy Notice</a>
WebElement was located using the linkText locator in Selenium: driver.findElement(By.linkText(“Privacy Notice”));
7) Partial Link Text
Partial Link Text works very similarly to Link Text used only for locating web elements having anchor tags. But Partial text is used if the text of the link is too long to mention in the locator, or sometimes, the intent of using partial link text is to get all the elements of the web page to have a common partial link text, then we use the Partial Link Text locator.
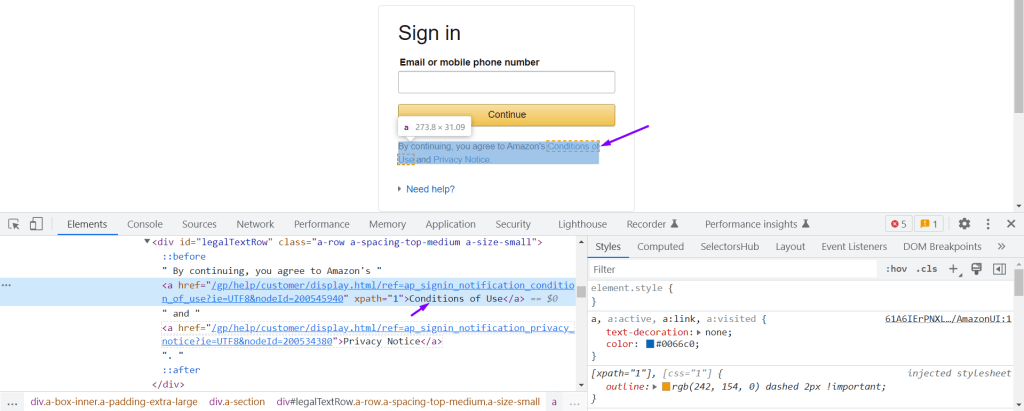
DOM Structure:
<a href=”/gp/help/customer/display.html/ref=ap_signin_notification_condition_of_use?ie=UTF8&nodeId=200545940″ xpath=”1″>Conditions of Use</a>
WebElement was located using the PartialLinkText locator in Selenium:
driver.findElement(By.partialLinkText (“Conditions”));
8) XPath
XPath helps in locating web elements on the page using XML expressions.
XPath is of 2 types:
– Absolute XPath: XPath of the web element starting from the very first root node is absolute XPath. It starts with a single forward slash.
Example: /html/body/div/input[1]
– Relative XPath: The absolute XPath is very lengthy, in order to reduce the length and in order to make your XPath more reliable, we should prefer using relative XPath because a minor change in the DOM structure can affect your XPath and your scripts will start to fail. It starts with a double-forward slash.
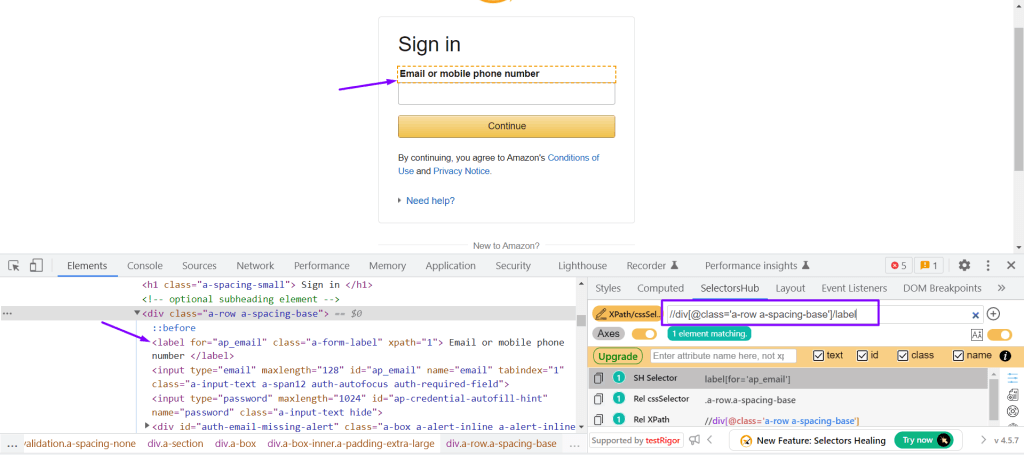
The basic syntax for creating XPath is:
//tagname[@attribute=’value’]
//: Select the current node.
Tagname: Tagname of the particular node.
@: Select attribute.
Attribute: Attribute the name of the node.
Value: Value of the attribute.
Example: //div[@class=’a-row a-spacing-base’]/label
WebElement was located using the XPath locator in Selenium:
Selenium: driver.findElement(By.xpath(“//div[@class=’a-row a-spacing-base’]/label”));
If there is more than one matching result in the DOM of a particular XPath, in such case we can use indexing to locate exact web element and perform an appropriate action.
Example: //div[@class=’a-row a-spacing-base’]/label[2]
XPath supports different functions for locating web elements:
– text()

DOM: <a href=”/gp/help/customer/display.html/ref=ap_signin_notification_privacy_notice?ie=UTF8&nodeId=200534380″ xpath=”1″>Privacy Notice</a>
Example: //a[text()=’Privacy Notice’]
Selenium: driver.findElement(By.xpath(//a[text()=’Privacy Notice’];
– contains()
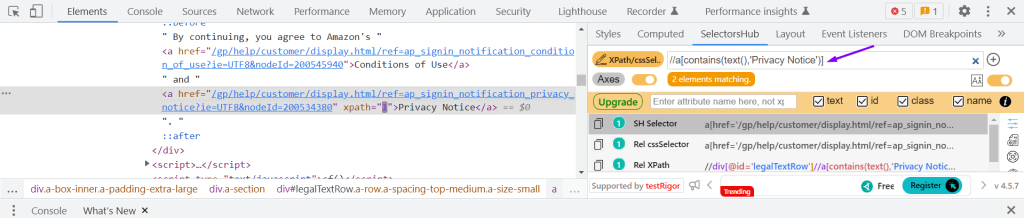
Example: (//a[contains(text(),’Privacy Notice’)])[1]
Selenium: driver.findElement(By.xpath(//a[contains(text(),’Privacy Notice’)])[1]);
Conclusion:
- Every object/web element may not have an ID, class name, or name. In such cases, XPath and CSS are preferred.
- Alphanumeric ID may vary on every refresh, check before using it to locate.
- Confirm the link object with “a” tag.
- Classes should not have spaces- compound classes are not accepted.
- If there are multiple matching results – selenium will identify the first one as it scans from the top left.
- To validate XPath, CSS in the browser console: use:
For XPath: $x(“writeYourXpathHere“)
For CSS: $(“writeYourCssHere“) - Relative XPath does not depend on the parent node.
- Among absolute and relative XPath, Relative XPath is preferable all the time.
- CSS is around 10 times faster than XPath.
- Class under a class only be identified using CSS only.
Featured Image Credit- https://www.pexels.com/@utkarsh-shukla-204757820/