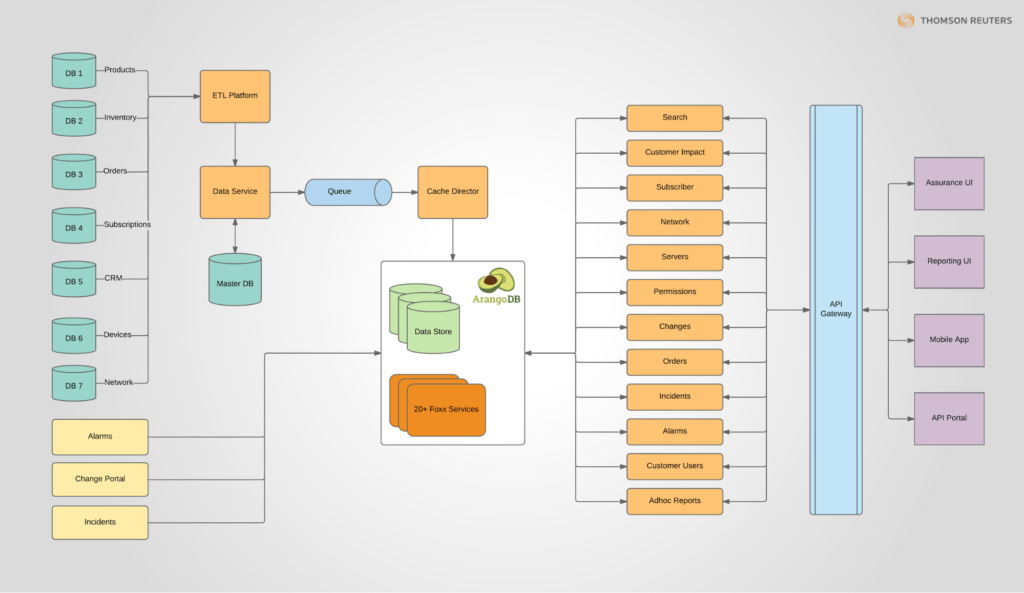
Unlike many NoSQL databases, ArangoDB is a native multi-model database. You can store your data as key/value pairs, graphs or documents and access any or all of your data using a single declarative query language. You can combine different models in one query. And, due to its native multi-model approach, you can build high performance applications and scale horizontally with all three data models.
ArangoDB as a Graph Database:
The graph capabilities of ArangoDB are similar to a property graph database but add more flexibility in terms of data modeling as vertices and edges are both full JSON documents.
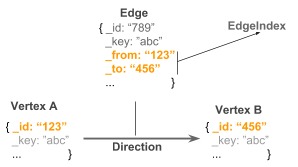
For each document, a unique _id attribute is stored automatically. To build a relation (i.e., an edge) between two documents (i.e., vertices), both _id attributes are stored in a special edge document known as _from and _to attributes, forming a directed connection between two arbitrary vertices. Edges are then stored in a special edge collection.
ArangoDB enables efficient and scalable graph query performance by using a special hash index on _from and _to attributes (i.e., an edge index). This allows for constant lookup times. Using an edge index, ArangoDB can process graph queries very efficiently.
Graph databases usually store edges connected to vertices directly at the vertex object. In ArangoDB this is handled differently (if you want to take a technical dive into ArangoDB’s approach, see this article about index-free adjacency vs. hybrid indexes).
Vertices and edges are both full JSON documents and can hold arbitrary data. By this approach combined with the edge index, ArangoDB is one of the few graph databases capable of horizontal scaling. Each edge and vertex can contain complex data in the form of nested properties, and all graph functions are deeply integrated into the ArangoDB Query Language, (AQL).
Arangodb Features:-
ArangoDB provides a broad spectrum of graph database features:
- Graph traversals
- Shortest path(s)
- Pattern matching
- Graph Viewer
- Integrations to Keylines & Cytoscape
- Horizontal Scaling with Graph Data and Queries
- Distributed graph processing via Pregel
ArangoDB supports document, graph, and key/value data models. Due to this natively integrated support, users can also take the result of a JOIN operation, geospatial query, text search or any other access pattern as a starting point for further graph analysis and vice versa – all in one query, if needed. This is an advantage of a native multi-model database like ArangoDB.
A graph can be visualized and manipulated directly within the ArangoDB WebUI. The WebUI provides many configurations for displaying edges and vertices. Here is a view of the IMDB dataset with its search depth set to 4, results limited to 300, the edge visualization type has been set to curved, and with custom vertex and edge labels. This gives a quick view of genres, movies in those genres, and actors who played in those movies.
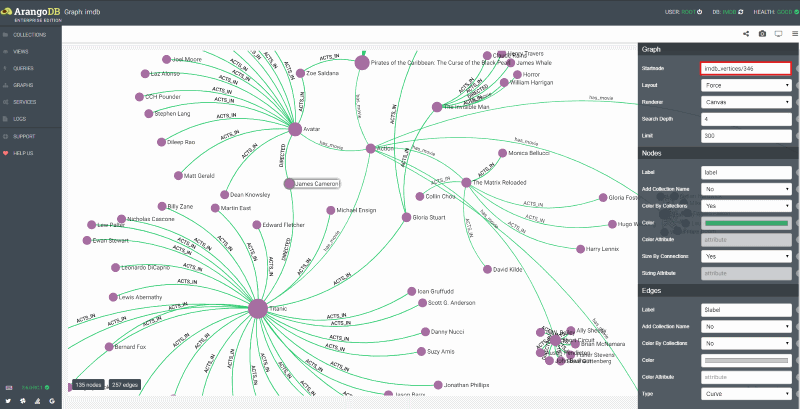
A nice feature of the Graph Viewer is the ability to select a node and set it as your start node. Here we chose James Cameron as the start node and now can see the movies he was involved in and then, depending on the depth set, further relationships from there. So, for this example, we see that he directed both Avatar and Titanic, which in this dataset are both classified as Action movies, and we can also other Action movies.
What is ArangoDB Query language (AQL):-
AQL (ArangoDB Query Language) is the SQL-like query language[26] used in ArangoDB. It supports CRUD operations for both documents (nodes) and edges, but it is not a data definition language (DDL). AQL does support geospatial queries.
AQL is JSON-oriented as illustrated by the following queries:
// Return every document in a collection
FOR doc IN collection
RETURN doc
// Count the number of documents in a collection
FOR doc IN collection
COLLECT WITH COUNT INTO length
RETURN length
// Add a new document into our collection
INSERT { _key: "john", name: "John", age: 45 } INTO collection
// Update document with key of “john” to have age 46.
UPDATE { _key: "john", age: 46 } IN collection
// Add an attribute numberOfLogins for all users with status active:
FOR u IN users
FILTER u.active == true
UPDATE u WITH { numberOfLogins: 0 } IN users

Use Case – ArangoDB
- Operationalizing Knowledge Graphs With Multi-Model
- Enterprise Knowledge Graphs (EKGs) have been on the rise and are incredibly valuable tools for harmonizing internal and external data relevant to an organization into a common semantic model. Enterprises benefit from improved operational efficiency and competitive advantages for their business units. Yet, taking a “graph-only” approach to EKGs often leads to the difficult challenges

- Adaptive Fraud Detection & Analytics With ArangoDB
- Today’s criminals are constantly coming up with new techniques to hide their activities by forming fraud networks with stolen or synthetic identities.
- In many cases, attacks are launched from multiple vectors and can only be discovered by connecting diverse data sources to uncover difficult-to-detect patterns. Multi-model graph technology is perfect to solve this challenge.
- Single View Of Everything – Scalable & Adaptive
- Acquiring and interpreting detailed information about customers, markets and other aspects of an organizations business is of paramount importance.
- Yet, relevant data becomes more and more unstructured and has to be analyzed in context in the light of changing aspects. ArangoDB lets you store and process all relevant information while making it very easy to connect the right dots with latest multi-model graph technology.