We live in a connected world, and understanding most domains requires processing rich sets of connections to understand what’s really happening. Often, we find that the connections between items are as important as the items themselves.
While existing relational databases can store these relationships, they navigate them with expensive JOIN operations or cross-lookups, often tied to a rigid schema. It turns out that “relational” databases handle relationships poorly. In a graph database, there are no JOINs or lookups. Relationships are stored natively alongside the data elements (the nodes) in a much more flexible format. Everything about the system is optimized for traversing through data quickly; millions of connections per second, per core.
What is a Graph Database?
A graph database stores nodes and relationships instead of tables, or documents. Data is stored just like you might sketch ideas on a whiteboard. Your data is stored without restricting it to a pre-defined model, allowing a very flexible way of thinking about and using it.
Graph databases address big challenges many of us tackle daily. Modern data problems often involve many-to-many relationships with heterogeneous data that sets up needs to:
Navigate deep hierarchies,
Find hidden connections between distant items, and
Discover inter-relationships between items.
Whether it’s a social network, payment networks, or road network you’ll find that everything is an interconnected graph of relationships. And when we want to ask questions about the real world, many questions are about the relationships rather than about the individual data elements
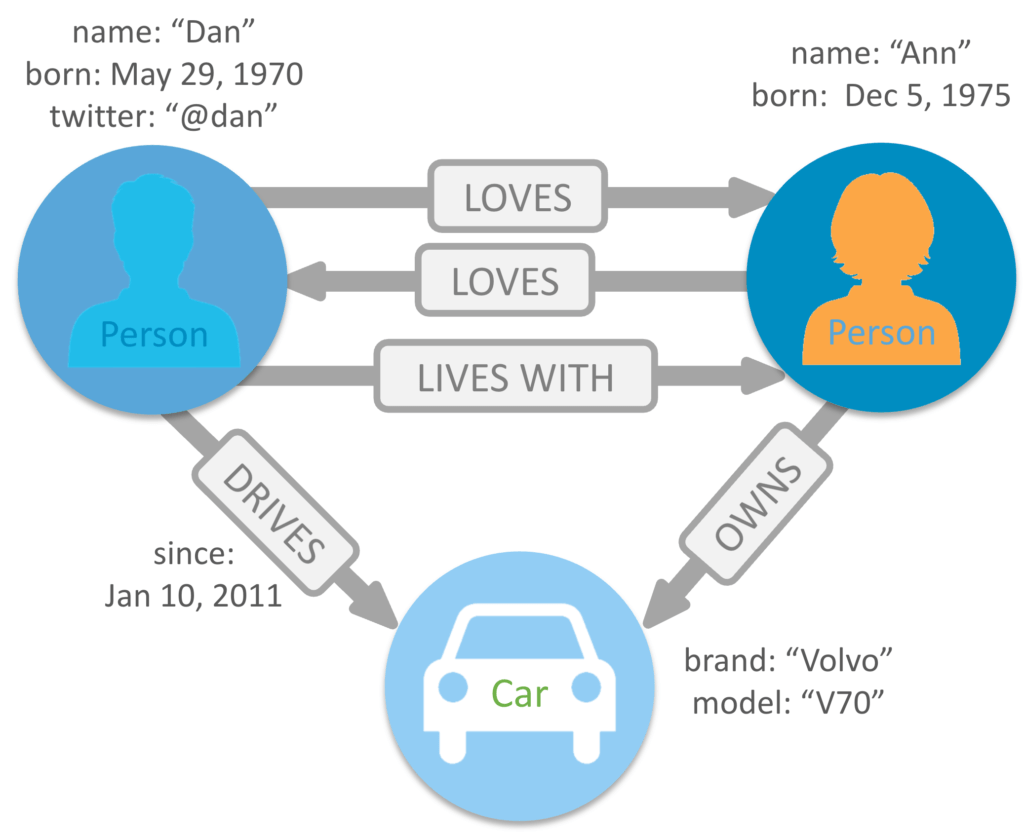
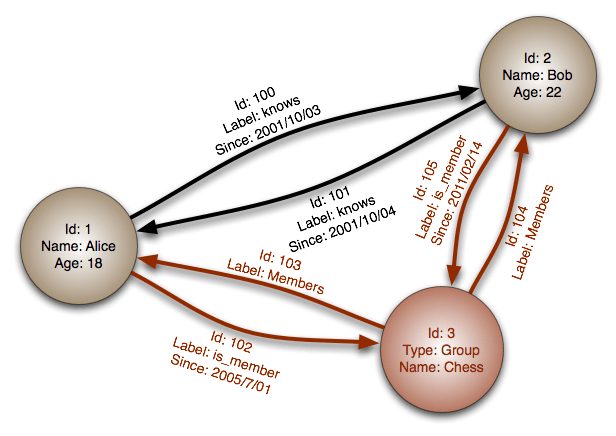
The Property Graph Model
Graph databases portray the data as it is viewed conceptually. This is accomplished by transferring the data into nodes and its relationships into edges.
A graph database is a database that is based on graph theory. It consists of a set of objects, which can be a node or an edge.
Nodes represent entities or instances such as people, businesses, accounts, or any other item to be tracked. They are roughly the equivalent of a record, relation, or row in a relational database, or a document in a document-store database.
Edges, also termed graphs or relationships, are the lines that connect nodes to other nodes; representing the relationship between them. Meaningful patterns emerge when examining the connections and interconnections of nodes, properties and edges. The edges can either be directed or undirected. In an undirected graph, an edge connecting two nodes has a single meaning. In a directed graph, the edges connecting two different nodes have different meanings, depending on their direction. Edges are the key concept in graph databases, representing an abstraction that is not directly implemented in a relational model or a document-store model.
Properties are information associated to nodes. For example, if Wikipedia were one of the nodes, it might be tied to properties such as website, reference material, or words that starts with the letter w, depending on which aspects of Wikipedia are germane to a given database.
Why graph database is different from relational databases
he data models for relational versus graph are very different. The straightforward graph structure results in much simpler and more expressive data models than those produced using traditional relational or other NoSQL databases.
If you are used to modeling with relational databases, remember the ease and beauty of a well-designed, normalized entity-relationship diagram – a simple, easy-to-understand model you can quickly whiteboard with your colleagues and domain experts. A graph is exactly that – a clear model of the domain, focused on the use cases you want to efficiently support.
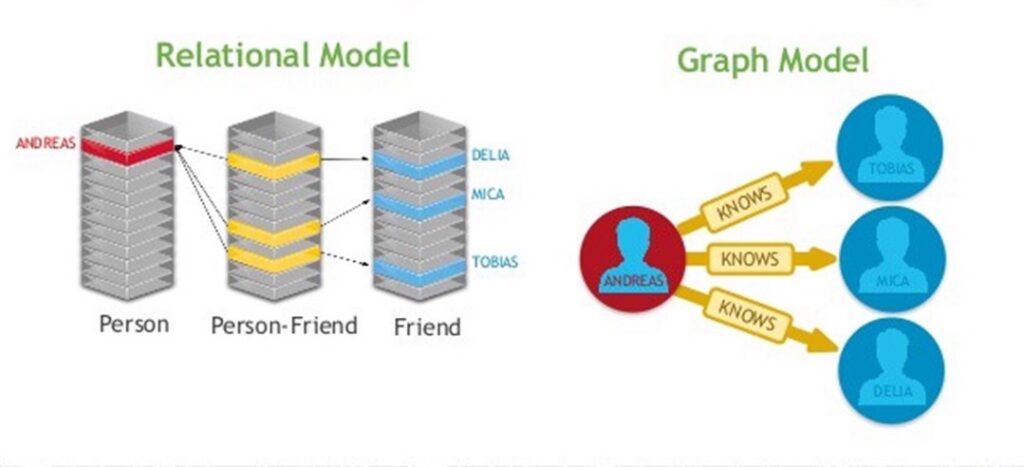
Let’s compare the two data models to show how the structure differs between relational and graph.
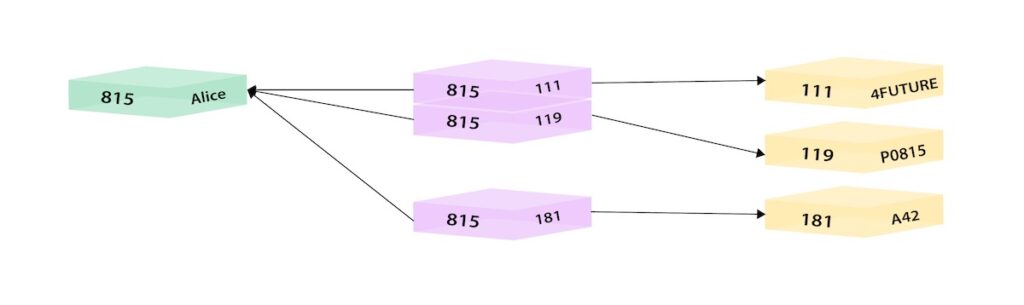
Relational – Person and Department tables
In the above relational example, we search the Person table on the left (potentially millions of rows) to find the user Alice and her person ID of 815. Then, we search the Person-Department table (orange middle table) to locate all the rows that reference Alice’s person ID (815). Once we retrieve the 3 relevant rows, we go to the Department table on the right to search for the actual values of the department IDs (111, 119, 181). Now we know that Alice is part of the 4Future, P0815, and A42 departments.
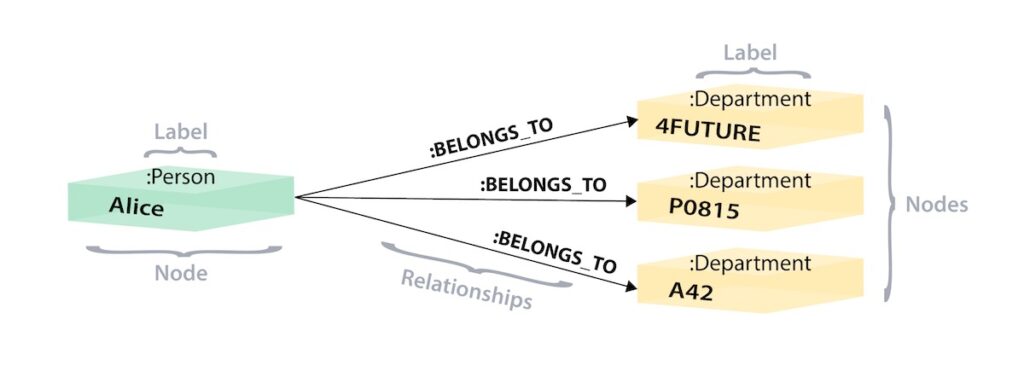
Graph – Alice and 3 Departments as nodes
In the above graph version, we have a single node for Alice with a label of Person. Alice belongs to 3 different departments, so we create a node for each one and with a label of Department. To find out which departments Alice belongs to, we would search the graph for Alice’s node, then traverse all of the BELONGS_TO relationships from Alice to find the Department nodes she is connected to. That’s all we need – a single hop with no lookups involved.
To further illustrate, imagine a relational model with two tables: a people table (which has a person_id and person_name column) and a friend table (with friend_id and person_id, which is a foreign key from the people table). In this case, searching for all of Jack’s friends would result in the following SQL query.
SELECT p2.person_name
FROM people p1
JOIN friend ON (p1.person_id = friend.person_id)
JOIN people p2 ON (p2.person_id = friend.friend_id)
WHERE p1.person_name = 'Jack';
The same query may be translated into –Cypher, a graph database querylanguage
MATCH (p1:person {name: 'Jack'})-[:FRIEND_WITH]-(p2:person)
RETURN p2.name
SPARQL, an RDF graph database query language standardized by W3C and used in multiple RDF Triple and Quad stores
Long form
SELECT ?name
WHERE { ?s afoaf:Person .
?s foaf:name "Jack" .
?s foaf:knows ?o .
?o foaf:name ?name .
}
Short form
SELECT ?name
WHERE { ?s foaf:name "Jack" ;
foaf:knows ?o .?o foaf:name ?name . }
SPASQL, a hybrid database query language, that extends SQL with SPARQL
SELECT people.name
FROM (
SPARQL PREFIXfoaf: <http://xmlns.com/foaf/0.1/>
SELECT ?name
WHERE { ?s foaf:name "Jack" ;
foaf:knows ?o .
?o foaf:name ?name .
}
) AS people ;
The above examples are a simple illustration of a basic relationship query. They condense the idea of relational models’ query complexity that increases with the total amount of data. In comparison, a graph database query is easily able to sort through the relationship graph to present the results.
There are also results that indicate simple, condensed, and declarative queries of the graph databases do not necessarily provide good performance in comparison to the relational databases. While graph databases offer an intuitive representation of data, relational databases offer better results when set operations are needed
Types of Graph database available in Market
The following is a list of graph databases:
name
description
AllegroGraph
Resource Description Framework (RDF) and graph database.
Amazon Neptune
Amazon Neptune is a fully managed graph database by Amazon.com. It is used as a web service, and is part of Amazon Web Services. Supports popular graph models property graph and W3C’s RDF, and their respective query languages Apache TinkerPop, Gremlin, SPARQL, and openCypher.
AnzoGraphDB
AnzoGraph DB is a massively parallel native graph GOLAP (Graph Online Analytics Processing) style database built to support SPARQL and Cypher Query Language to analyze trillions of relationships. AnzoGraph DB is designed for interactive analysis of large sets of semantic triple data, but also supports labeled properties under proposed W3C standards.
Apache AGE
PostgreSQL extension that provides graph database functionality. The objective of Apache AGE is to enable PostgreSQL users to use openCypher-based graph queries in unison with existing relational tables.
ArangoDB
NoSQL native graph database system developed by ArangoDB Inc, supporting three data models (key/value, documents, graphs), with one database core and a unified query language called AQL (ArangoDB Query Language). Provides scalability and high availability via datacenter-to-datacenter replication, auto-sharding, automatic failover, and other capabilities.
ArcadeDB
Multi-model database supporting graphs, key / value, documents and time-series.
DataStax Enterprise Graph
Distributed, real-time, scalable database; supports Tinkerpop, and integrates with Cassandra
Dgraph
Open source, distributed graph database with a GraphQL based query language.[30][31]
InfiniteGraph
A distributed, cloud-enabled and massively scalable graph database for complex, real-time queries and operations. Its Vertex and Edge objects have unique 64-bit object identifiers that considerably speed up graph navigation and pathfinding operations. It supports batch or streaming updates to the graph alongside concurrent, parallel queries. InfiniteGraph’s ‘DO’ query language enables both value based queries, as well as complex graph queries. InfiniteGraph is goes beyond graph databases to also support complex object queries.
JanusGraph
Open source, scalable, distributed across a multi-machine cluster graph database under The Linux Foundation; supports various storage backends (Apache Cassandra, Apache HBase, Google Cloud Bigtable, Oracle BerkeleyDB);[33] supports global graph data analytics, reporting, and extract, transform, load (ETL) through integration with big data platforms (Apache Spark, Apache Giraph, Apache Hadoop); supports geo, numeric range, and full-text search via external index storages (Elasticsearch, Apache Solr, Apache Lucene).
MarkLogic
Multi-model NoSQL database that stores documents (JSON and XML) and semantic graph data (RDF triples); also has a built-in search engine.
Microsoft SQL Server 2017
Offers graph database abilities to model many-to-many relationships. The graph relationships are integrated into Transact-SQL, and use SQL Server as the foundational database management system.
Nebula Graph
A scalable open-source distributed graph database for storing and handling billions of vertices and trillions of edges with milliseconds of latency. It is designed based on a shared-nothing distributed architecture for linear scalability.
Neo4j
Open-source, supports ACID, has high-availability clustering for enterprise deployments, and comes with a web-based administration that includes full transaction support and visual node-link graph explorer; accessible from most programming languages using its built-in REST web API interface, and a proprietary Bolt protocol with official drivers.
Ontotext GraphDB
Highly efficient and robust graph database with RDF and SPARQL support, also available as a high-availability cluster.
OpenLink Virtuoso
Multi-model (Hybrid) relational database management system (RDBMS) that supports both SQL and SPARQL for declarative (Data Definition and Data Manipulation) operations on data modelled as SQL tables and/or RDF Graphs. Also supports indexing of RDF-Turtle, RDF-N-Triples, RDF-XML, JSON-LD, and mapping and generation of relations (SQL tables or RDF graphs) from numerous document types including CSV, XML, and JSON. May be deployed as a local or embedded instance (as used in the NEPOMUK Semantic Desktop), a one-instance network server, or a shared-nothing elastic-cluster multiple-instance networked server
Oracle Property Graph; part of Oracle Database
Property Graph; consisting of a set of objects or vertices, and a set of arrows or edges connecting the objects. Vertices and edges can have multiple properties, which are represented as key–value pairs. Includes PGQL, an SQL-like graph query language and an in-memory analytic engine (PGX) nearly 60 prebuilt parallel graph algorithms. Includes REST APIs and graph visualization.
Oracle RDF Graph; part of OracleDatabase
RDF Graph capabilities as features in multi-model Oracle Database: RDF Graph: comprehensive W3C RDF graph management in Oracle Database with native reasoning and triple-level label security. ACID, high-availability, enterprise scale. Includes visualization, RDF4J, and native end Sparql end point.
OrientDB
Second-generation distributed graph database with the flexibility of documents in one product (i.e., it is both a graph database and a document NoSQL database); licensed under open-source Apache 2 license; and has full ACID support; it has a multi-master replication and sharding; supports schema-less, -full, and -mixed modes; has security profiling based on user and roles; supports a query language similar to SQL. It has HTTP REST and JSON API.
RDFox
A high-performance scalable in-memory RDF triple store and semantic reasoning engine. It supports shared memory parallel reasoning for RDF, RDFS, OWL 2 RL, and Datalog. It is cross-platform software written in C++ that comes with a Java wrapper allowing for easy integration with any Java-based solution. Supported on Windows, MacOS and Linux.
RedisGraph
In-memory, queryable Property Graph database which uses sparse matrices to represent the adjacency matrix in graphs and linear algebra to query the graph.
High-performance scalable database management system from Sparsity Technologies; main trait is its query performance for retrieving and exploring large networks; has bindings for Java, C++, C#, Python, and Objective-C; version 5 is the first graph mobile database.
Sqrrl Enterprise
Distributed, real-time graph database featuring cell-level security and mass-scalability
Stardog
Enterprise knowledge graph platform supporting RDF and labeled property graphs; natively supports SPARQL, Semantic Web Rule Language (SWRL), SHACL, GraphSQL, SQL, Java, JavaScript, Python, .NET, Clojure, Spring, and Groovy
Teradata Aster
Massive parallel processing (MPP) database incorporating patented engines supporting native SQL, MapReduce, and graph data storage and manipulation; provides a set of analytic function libraries and data visualization
TerminusDB
Document-oriented knowledge graph; the power of an enterprise knowledge graph with the simplicity of documents.
TIBCO Graph Database
High Performance Property Graph Database with the following features: Attribute Namespace aware with NodeTypes, and EdgeTypes for categorization. Index support. Full Acid support with SQL-92 data type support. Role based ACLs, with encryption.Apache Gremlin based query language – supporting both Gremlin Java API and a syntactic form of the Gremlin functional language and using linear algebra to query the graph.Stored Procedures and Trigger support Python – Builtin Graph Algorithms for Node Metrics, Partitioning/Grouping, Paths, and many more.Built-in Clustering for Horizontal Scalability and Redundancy. Supports Multi-tenant databases.Seamless integration with TIBCO Spotfire Analytics to visualize data in network and traditional charts.Open source Client API in Java, Go, Python, REST.
TigerGraph
Massive parallel processing (MPP) native graph database management system
TypeDB
TypeDB is a strongly-typed database with a rich and logical type system. TypeDB empowers you to tackle complex problems, and TypeQL is its query language. TypeDB allows you to model your domain based on logical and object-oriented principles. Composed of entity, relationship, and attribute types, as well as type hierarchies, roles, and rules, TypeDB allows you to think higher-level, as opposed to join-tables, columns, documents, vertices, edges, and properties.
Ultipa
Hybrid transactional/analytical processing (HTAP), built from a patent-pending, HDPC, high-density parallel graph computing.
Types of graph query-programming languages
AQL (ArangoDB Query Language): a SQL-like query language used in ArangoDB for both documents and graphs
Cypher Query Language (Cypher): a graph query declarative language for Neo4j that enables ad hoc and programmatic (SQL-like) access to the graph.
GQL: proposed ISO standard graph query language
GSQL: a SQL-like Turing complete graph query language designed and offered by TigerGraph
GraphQL: an open-source data query and manipulation language for APIs. Dgraph implements modified GraphQL language called DQL (formerly GraphQL+-)
Gremlin: a graph programming language that is a part of Apache TinkerPop open-source project
SPARQL: a query language for RDF databases that can retrieve and manipulate data stored in RDF format