
Topic modeling is recognizing the words from topics present in documents or corpus of domain relevant data. This is useful because extracting the words from a document takes more time and is much more complex than extracting them from topics present in the document. It also useful for analyze online reviews, products’ descriptions, or text entered in search bars, understanding key topics will always come in handy.
In short, this technique helps you:
1. Mining relevant information at scale
2. Getting real-time analysis
3. Building a consistent understanding of data
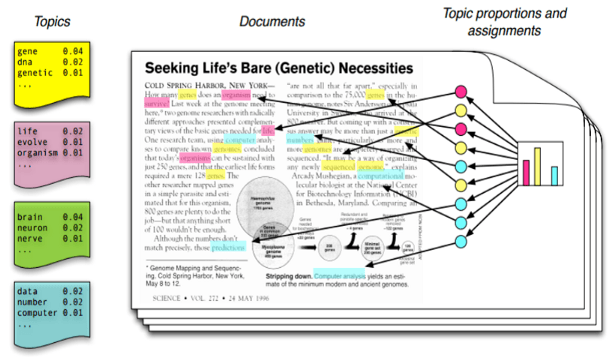
For example, there are 100 documents and 50 words in each document. So to process this it requires 50*100 = 5000 threads. So when you divide the document containing certain topics then if there are 5 topics present in it, the processing is just 5*50 words = 250 threads.

Above image is the showing the visualization of LDA Intuition, how data takes input and how the output would be like.
Visualization can be done using various methods present in different libraries so the visualization graph might differ then the insight it gives is the same. It tells about the mixture of topics and their distribution in the data or different documents.
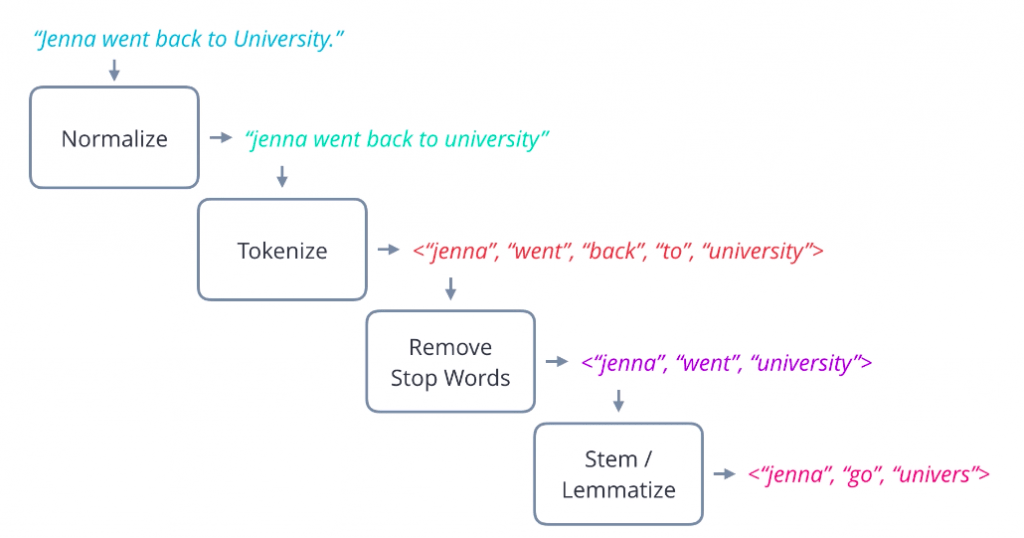
Data Pre-processing in text data before applying any models
Significance of text preprocessing in the performance of models. Data preprocessing is an essential step in building a Machine Learning model and depending on how well the data has been preprocessed.
Techniques
1. Tokenization
2. Lower casing
3. Stop words removal
4. Stemming
5. Lemmatization
What is LDA?
latent means hidden or concealed, Latent Dirichlet Allocation (LDA) is a popular topic modeling technique to extract topics from a given corpus. The term latent conveys something that exists but is not yet developed. In other words.
Process
The LDA makes two key assumptions:
1. Documents are a mixture of topics
2. Topics are a mixture of tokens (or words)
these topics using the probability distribution generate the words. In statistical language
Use Cases & Applications
1. In sales and marketing to customer domain, topic modeling and topic classification can help eliminate manual and repetitive tasks, as well as speed up processes in a simple and cost-effective way. For spend hours routing support tickets, customer feedback and the like by tagging and sorting data, which machine learning algorithms can do automatically, and in real-time.
2. It may be used to rapidly find out what the document or book is about via text summary.
3. It can be used in exam scoring to eliminate prejudice against candidates. It also helps students acquire their findings promptly and saves a lot of time.
4. It can recognize search terms and provide product recommendations to clients.
References
https://www.jmlr.org/papers/volume3/blei03a/blei03a.pdf


{kind=link}