
In this blog post, we will understand how we can leverage Delta Lake and create a generalized Data Analytics Architecture on Azure.
Delta lake in brief
Delta Lake is an open-source storage layer that brings reliability to data lakes. Delta Lake provides ACID transactions, scalable metadata handling, and unifies streaming and batch data processing. Delta Lake runs on top of your existing data lake and is fully compatible with Apache Spark APIs. Delta Lake on Azure Databricks allows you to configure Delta Lake based on your workload patterns.
Leverage Delta Lake with Azure
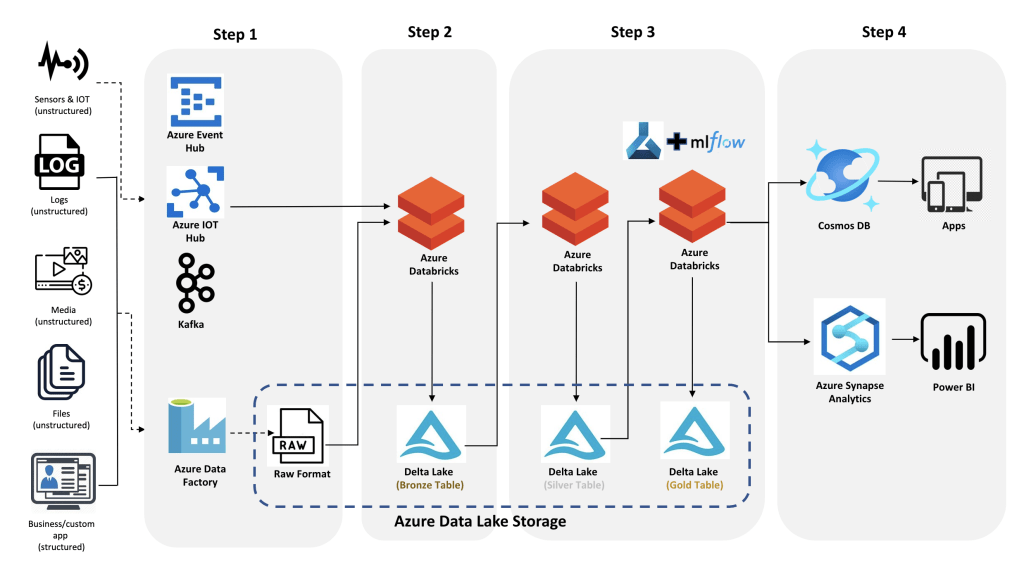
Similar to any ETL pipeline, the journey starts with a wide variety of data – structured and unstructured.
Step 1
The very first step is to bring that data to the Azure Data Lake Storage (ADLS).
- For real-time, we might be using either Kafka, Azure Event Hub, or Azure IoT Hub.
- Azure Data Factory will be used to ingest the data in bulk to the ADLS storage
Step 2
- In the 2nd step, both batch and streaming data will be combined and saved as a Delta Format using Azure Databricks.
- This will be the exact replica of the raw data without business logic.
Step 3
- The data will be cleaned, transformed, and enriched using Azure Databricks.
- If it is required, we can have a Gold table, as per our architecture, to store curated data.
- Azure ML, along with, ML Flow will be used to develop, train, and score ML models
Step 4
The final step after data preparation would be, is to send that data downstream to
- Cosmos DB for real-time apps.
- Azure Synapse for BI and reporting.



4 comments
Reading your article has greatly helped me, and I agree with you. But I still have some questions. Can you help me? I will pay attention to your answer. thank you.
At the beginning, I was still puzzled. Since I read your article, I have been very impressed. It has provided a lot of innovative ideas for my thesis related to gate.io. Thank u. But I still have some doubts, can you help me? Thanks.
I am a website designer. Recently, I am designing a website template about gate.io. The boss’s requirements are very strange, which makes me very difficult. I have consulted many websites, and later I discovered your blog, which is the style I hope to need. thank you very much. Would you allow me to use your blog style as a reference? thank you!