
Introduction
In this blog, we are going to cover-
- Big Data and its importance
- Introduction to Hadoop
- Introduction to Apache PIG
- PIG Architecture
- Pig Script Hands-on
What is Big Data and why is it so important?
Internet accessibility is increasing day by day, at the current scenario there are more than 3.7 billion users of the Internet.
Google search is getting used more than 3.5 billion times a day, that is around 40,000 searches in a second.
On the whole internet, there are more than 6 billion searches a day.
Let us study the Domo’s report on Data, and figure out how much data is generated on social media per minute–
- 575k Tweet on Twitter
- 240k photos share on Facebook
- 65k photos share on Instagram
- 44M live views on Facebook
- 694k hours stream on YouTube
- 452k hours stream on Netflix
- 100k users connect on Microsoft Teams
- 856mins of the webinar on Zoom
- 148k messages on Slack
- 6M people shopping Online
- $283k spend on Amazon
- 2M snaps send on Snapchat
- 12M IMESSAGES
- 167M users streaming on TikTok
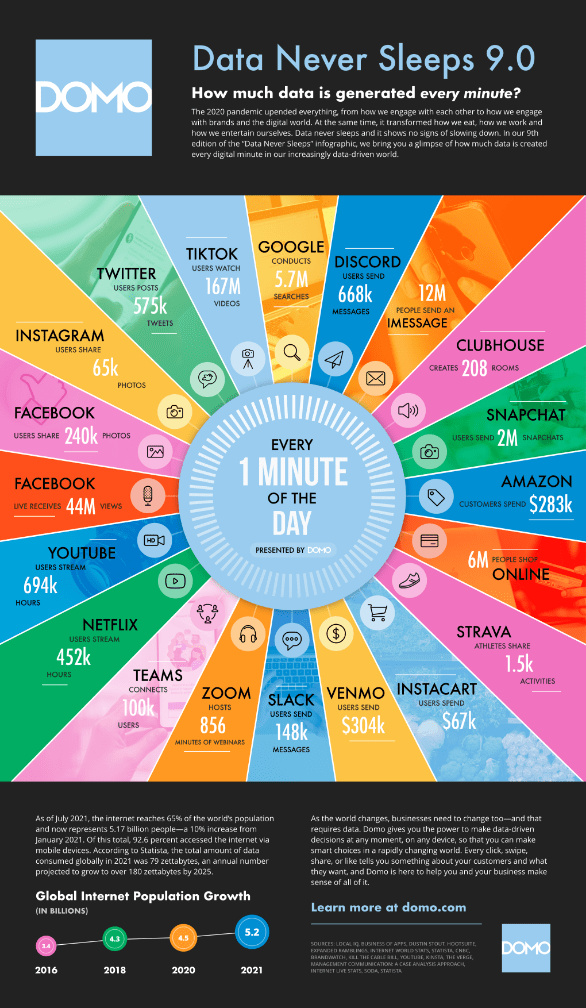

This large amount of dataset that is generated is basically big data, it can be in any form structured or unstructured. There can be a continuous flow of data or phases.
Importance of Big Data
- Faster and better decision-making.
- Cost Reduction.
- Business Purpose.
- Data Analysis. (In almost all the fields)
- Time Reduction
- New product development and optimization
Determining root causes of failures, issues, and defects in near-real-time. Generating coupons at the point of sale based on the customer’s buying habits. Recalculating entire risk portfolios in minutes.
Detecting fraudulent behavior before it affects your organization.
Challenges with Big Data
The major challenges are:
- Storage
- Capturing data
- Sharing
- Transfer
- Analysis
- Searching
The solution to the Big Data problem
Traditional Enterprise Approach
In this approach, an enterprise will have a computer and storage for storing and processing the data. For storage purposes, the developer will take the help of their choice of database vendors such as Oracle, IBM, etc. In this approach, the user interacts with the application, which in turn handles the part of data storage and analysis.
Limitation
This approach works fine with those applications that process less voluminous data that can be accommodated by standard database servers, or up to the limit of the processor that is processing the data. But when it comes to dealing with huge amounts of scalable data, it is a hectic task to process such data through a single database bottleneck.
Google’s Solution
Google solved this problem using an algorithm called MapReduce. This algorithm divides the task into small parts and assigns them to many computers, and collects the results from them which when integrated, form the result dataset.
Hadoop
Using the solution provided by Google, Doug Cutting and his team developed an Open Source Project called HADOOP.
Hadoop runs applications using the MapReduce algorithm, where the data is processed in parallel with others. In short, Hadoop is used to develop applications that could perform complete statistical analysis on huge amounts of data.
Hadoop
- An open-source software framework that supports data-intensive distributed applications, licensed under the Apachev2 license.
- Abstract and facilitate the storage and processing of large and/or rapidly growing data sets.
- Use commodity (cheap!) hardware with little redundancy Fault-tolerance.
- High scalability and availability.
HDFS
- Hadoop comes with a distributed file system called HDFS, which stands for Hadoop Distributed File system.
- HDFS is a file system designed for storing very large files with streaming data access patterns, running on clusters of commodity hardware.
- Two main component
- Distributed File System
- Map Reduce Engine
Map Reduce Engine
MapReduce is a programming model and an associated implementation for processing and generating large data sets with a parallel, distributed algorithm on a cluster.
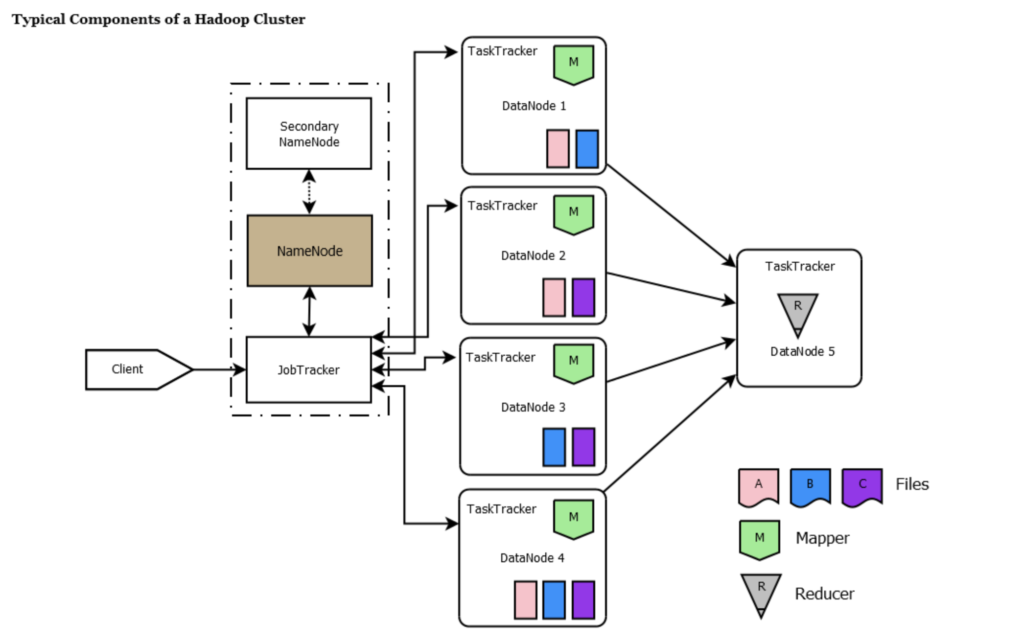
Data Node
- The data node is where the actual data resides. All data nodes send a heartbeat message to the namenode every 3 seconds to say that they are alive.
- If the namenode does not receive a heartbeat from a particular data node for 10 minutes, then it considers that data node to be dead/out of service and initiates replication of blocks which were hosted on that data node to be hosted on some other data node.
- The data nodes can talk to each other to rebalance data, move and copy data around and keep the replication high. When the datanode stores a block of information, it maintains a checksum for it as well.
- The data nodes update the namenode with the block information periodically and before updating verify the checksums. If the checksum is incorrect for a particular block i.e. there is a disk level corruption for that block, it skips that block while reporting the block information to the namenode. In this way, namenode is aware of the disk level corruption on that datanode and takes steps accordingly.
NameNode
NameNode works as Master in hadooop cluster. Below listed are the main function performed by NameNode:
1. Stores metadata of actual data. E.g. Filename, Path, No. of Block IDs, Block Location, No. of Replicas, data blocks, Slave related configuration
2. Manages File system namespace.
3. Regulates client access requests for the actual file data files.
4. Assign work to Slaves(DataNode).
5. Executes file system namespace operations like opening/closing files, renaming files, and directories.
6. As NameNode keeps metadata in memory for fast retrieval, a huge amount of memory is required for its operation. This should be hosted on reliable hardware.
Secondary NameNode
- The secondary namenode is responsible for performing periodic housekeeping functions for the NameNode.
- It only creates checkpoints of the filesystem present in the NameNode. The namenode stores the HDFS filesystem information in a file named fsimage.
- The secondary namenode job is not to be secondary to the namenode, but only to periodically read the filesystem changes log and apply them to the fsimage file, thus bringing it up to date.
- This allows the namenode to start up faster next time. NameNode is a primary node in which all the metadata is stored into fsimage and editlog files periodically. But, when the namenode is down secondary node will be online but this node only has the read access to the fsimage and editlog files and don’t have the write access to them.
- All the secondary node operations will be stored in a temp folder. when namenode is back online this temp folder will be copied to namenode and the namenode will update the fsimage and editlog files.
Task Tracker
- TaskTracker is a daemon that accepts tasks (Map, Reduce and Shuffle) from the JobTracker.
- The TaskTracker keeps sending a heartbeat message to the JobTracker to notify that it is alive.
- Along with the heartbeat it also sends the free slots available within it to process tasks.
- TaskTracker starts and monitors the Map & Reduce Tasks and sends progress/status information back to the jobtracker.
Job Tracker
- JobTracker is responsible for taking in requests from a client and assigning TaskTrackers tasks to be performed. The JobTracker tries to assign tasks to the TaskTracker on the DataNode where the data is locally present (Data Locality).
- If that is not possible it will at least try to assign tasks to TaskTrackers within the same rack. If for some reason the node fails the JobTracker assigns the task to another TaskTracker where the replica of the data exists since the data blocks are replicated across the DataNodes.
- This ensures that the job does not fail even if a node fails within the cluster. JobTracker process runs on a separate node and not usually on a DataNode. JobTracker is an essential Daemon for MapReduce execution.
- JobTracker receives the requests for MapReduce execution from the client.JobTracker talks to the NameNode to determine the location of the data. JobTracker finds the best TaskTracker nodes to execute tasks based on the data locality (proximity of the data) and the available slots to execute a task on a given node.
- JobTracker monitors the individual TaskTrackers and the submits back the overall status of the job back to the client. JobTracker process is critical to the Hadoop cluster in terms of MapReduce execution. When the JobTracker is down, HDFS will still be functional but the MapReduce execution can not be started and the existing MapReduce jobs will be halted.
Apace Pig
- A high-level programming language and runtime environment for Hadoop.
- Pig raises the level of abstraction for processing large datasets.
- With Pig, the data structures are much richer typically being multivalued and nested; and the set of transformations you can apply to the data is much more powerful—they include joins, for example, which are not for the faint of heart in MapReduce.
Pig Latin
- The language used to express data flows is called Pig Latin.
- The execution environment to run Pig Latin programs. There are currently two environments: local execution in a single JVM and distributed execution on a Hadoop cluster.
- A Pig Latin program is made up of a series of operations, or transformations, that are applied to the input data to produce output.
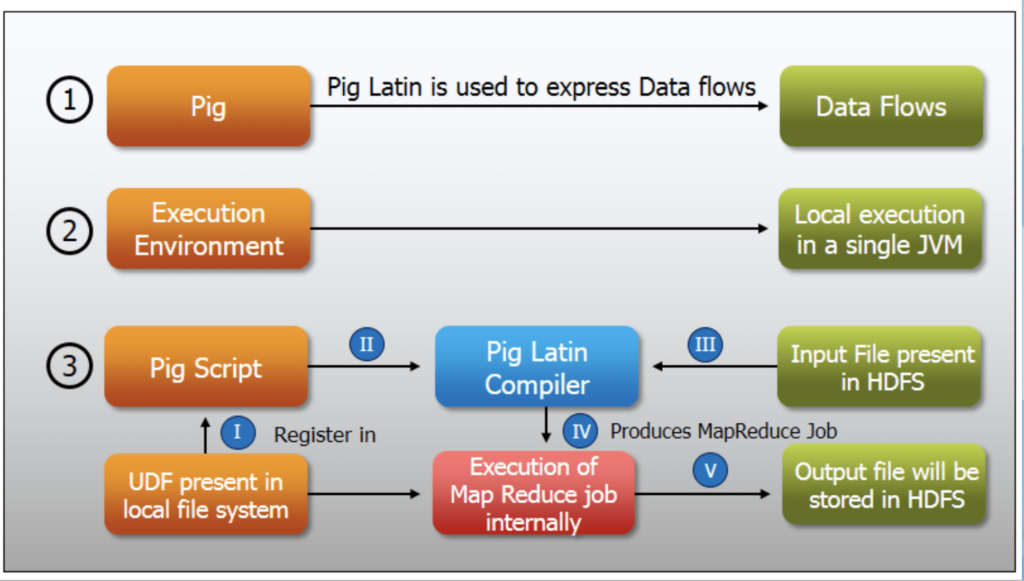
Pig Execution Modes
- Local Mode – All the files are installed and run from your localhost and local file system. There is no need for Hadoop or HDFS. This mode is generally used for testing purposes.
- MapReduce Mode – MapReduce mode is where we load or process the data that exists in the (HDFS) using Apache Pig. In this mode, whenever we execute the Pig Latin statements to process the data, a MapReduce job is invoked in the back-end to perform a particular operation on the data that exists in the HDFS.
Pig Execution Mechanism
- Interactive Mode (Grunt shell)− You can run Apache Pig in interactive mode using the Grunt shell. In this shell, you can enter the Pig Latin statements and get the output (using the Dump operator).
- Batch Mode (Script) − You can run Apache Pig in Batch mode by writing the Pig Latin script in a single file with the .pig extension.
- Embedded Mode (UDF) −Apache Pig provides the provision of defining our own functions (User Defined Functions) in programming languages such as Java and using them in our script.
- Parser – Initially the Pig Scripts are handled by the Parser. It checks the syntax of the script, does type checking, and does other miscellaneous checks. The output of the parser will be a DAG (directed acyclic graph), which represents the Pig Latin statements and logical operators.
- Optimizer – The logical plan (DAG) is passed to the logical optimizer, which carries out the logical optimizations such as projection and pushdown.
- Compiler – The compiler compiles the optimized logical plan into a series of MapReduce jobs.
- Execution engine – Finally, the MapReduce jobs are submitted to Hadoop in sorted order. Finally, these MapReduce jobs are executed on Hadoop producing the desired results.
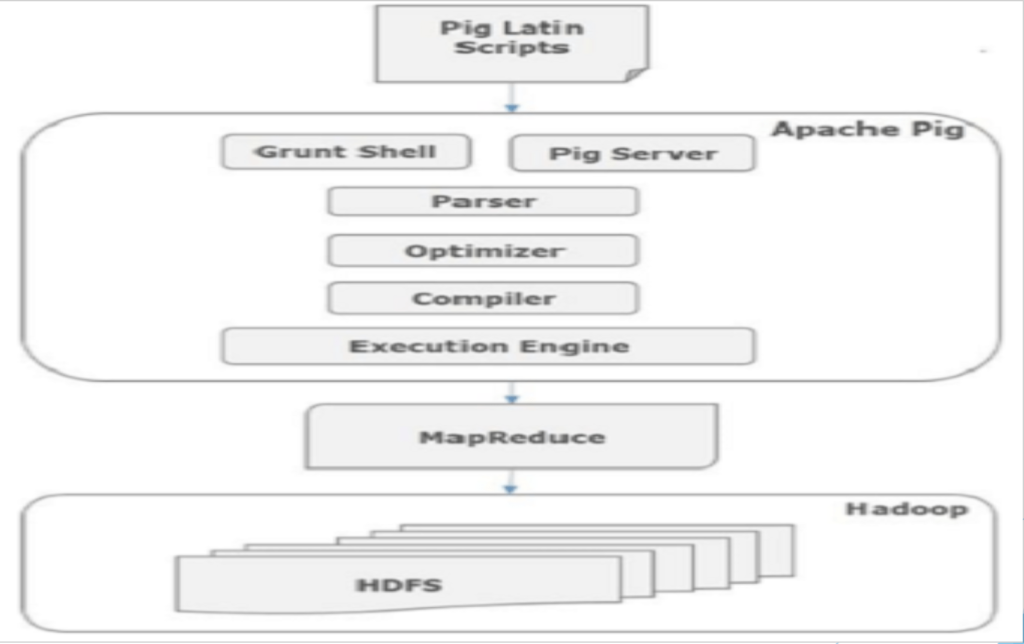
Installing and Running Pig
- Pig runs as a client-side application. Even if you want to run Pig on a Hadoop cluster, there is nothing extra to install on the cluster: Pig launches jobs and interacts withHDFS (or other Hadoop filesystems) from your workstation.
- Installation is straightforward. Java 6 is a prerequisite (and on Windows, you will need Cygwin). Download a stable release from http://pig.apache.org/releases.html, and unpack it in a suitable place on your workstation.
Demo
In the demo we are going to use the IPL dataset, I have shared the dataset link also. This is my favorite dataset as it is simple to understand and a variety of analyses are possible on this dataset. Currently, the data is from the 2008 to 2016 season. On the shared link, you can find out the latest dataset also.
- Analyze the IPL(INDIAN PREMIER LEAGUE) dataset for 10 years.
- Find out the various stats related to the game.
- Save the output and verify the result.
- Software-
- VMware Workstation
- IBM INFOSPHERE
VMware Workstation
- VMware Workstation is a hosted hypervisor that runs on x64 versions of Windows and Linux operating systems (an x86version of earlier releases was available).
- It enables users to set up virtual machines (VMs) on a single physical machine, and use them simultaneously along with the actual machine.
- Each virtual machine can execute its own operating system, including versions of Microsoft Windows, Linux, BSD, and MS-DOS. VMware Workstation is developed and sold by VMware, Inc., a division of Dell Technologies.
IBM INFOSPHERE BIGINSIGHT
- InfoSphere BigInsights 1.2 is a software platform designed to help firms discover and analyze business insights hidden in large volumes of a diverse range of data—data that’s often ignored or discarded because it’s too impractical or difficult to process using traditional means.
- Examples of such data include log records, clickstreams, social media data, news feeds, electronic sensor output, and even some transactional data. To help firms derive value from such data in an efficient manner, BigInsights incorporates several open source projects (including Apache™ Hadoop™) and a number of IBM-developed technologies.
DATA LOADING QUERIES
Dataset link – https://www.kaggle.com/datasets/patrickb1912/ipl-complete-dataset-20082020
There are two files deliveries and matches, we will be loading both of them.
data = load '/home/biadmin/matches.csv' using PigStorage(',') as (id: int,season:int, city:chararray, team1:chararray,team2:chararray,tosswinner:chararray,tossdecision:chararray,result:chararray,dlapplied:chararray,winner:chararray,winbyrun:int,winbywickets:int,playerofthematch:chararray,venue:chararray,umpire1:chararray,umpire2:chararray);
data = load '/home/biadmin/deliveries.csv' using PigStorage(',') as (matchid:int,inning:int,battingteam:chararray,bowlingteam:chararray,over:int,ball:int,batsman:chararray,nonstriker:chararray,bowler:chararray,issuperover:int,wideruns:int,byeruns:int,legbyeruns:int,noballruns:int,penaltyruns:int,batsmanruns:int,extraruns:int,totalruns:int,playerdismissed:chararray,dismissalkind:chararray,fielder:chararray);
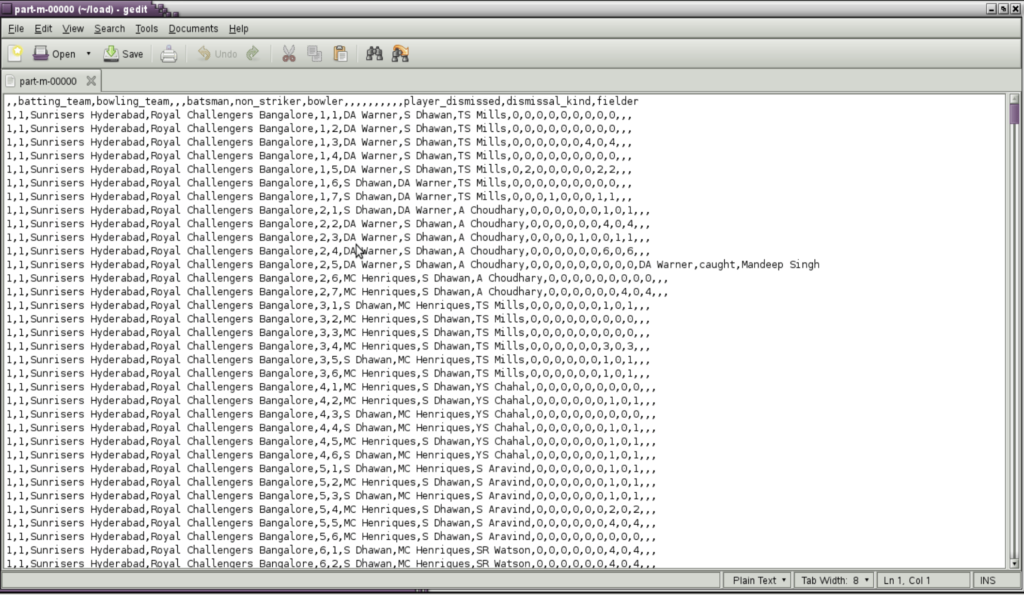
NUMBER OF MATCHES WON BY EACH TEAM
a= group data by winner;
b = foreach a generate group , COUNT ($1);
c = order b by $1 asc;
dump c;
STORE c into '/home/biadmin/result' using PigStorage(',');
{RESULT WILL BE STORED IN RESULT.TXT DIRECTORY}
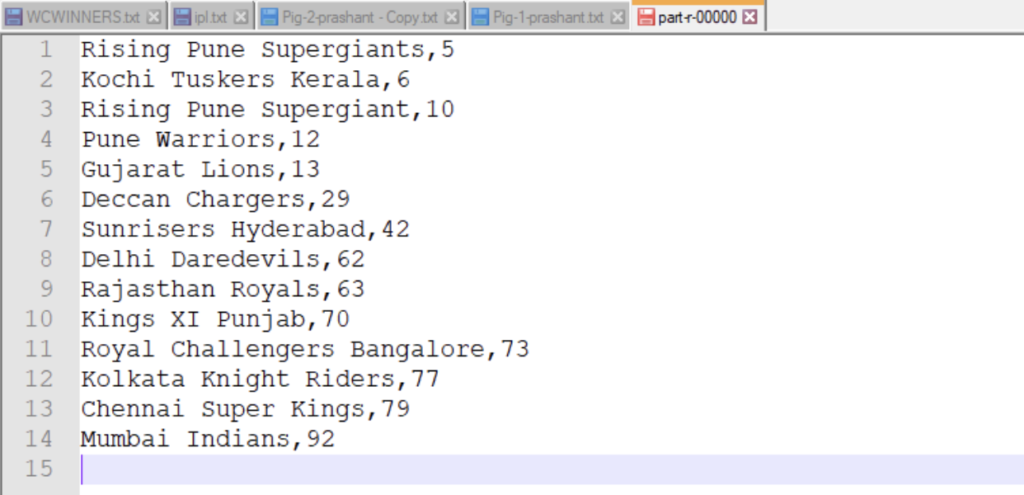
NUMBER OF TIMES A PLAYER HAS BEEN AWARDED THE TITLE OF “MAN OF THE MATCH”
d= group data by playerofthematch;
e = foreach d generate group , count ($1);
f= order e by $1 asc;
STORE f into '/home/biadmin/result1' using PigStorage(',');
{RESULT WILL BE STORED IN RESULT.TXT DIRECTORY}
HOW MANY TEAMS HAVE WON BOTH, THE TOSS AND THE MATCH
g = foreach data generate tosswinner,winner;
split data into h if tosswinner==winner , i if tosswinner != winner ;
a = group h by winner;
b = foreach a generate group , COUNT ($1);
dump b;
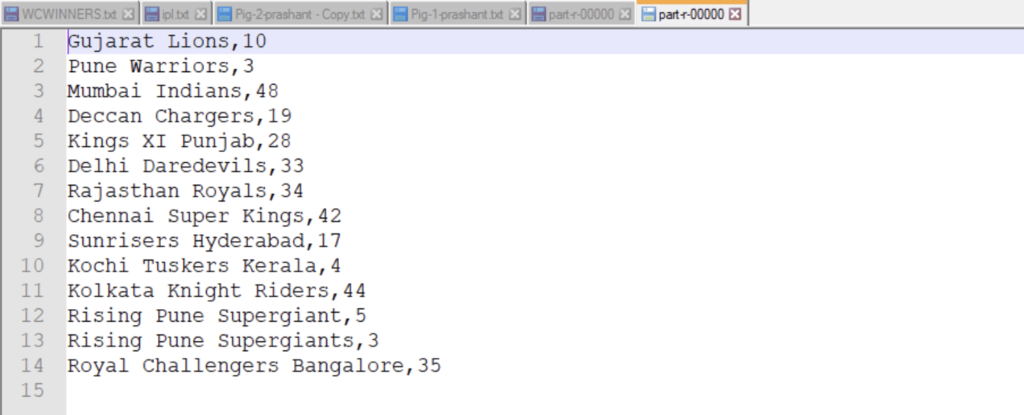
BY WHAT MAXIMUM WICKETS HAS THE TEAM “GUJARAT LIONS” HAVE WON THE MATCH
j = filter data by winner == 'Gujarat Lions';
k = group j by winner;
l = foreach k generate group, MAX(j.winbywickets);
dump l;
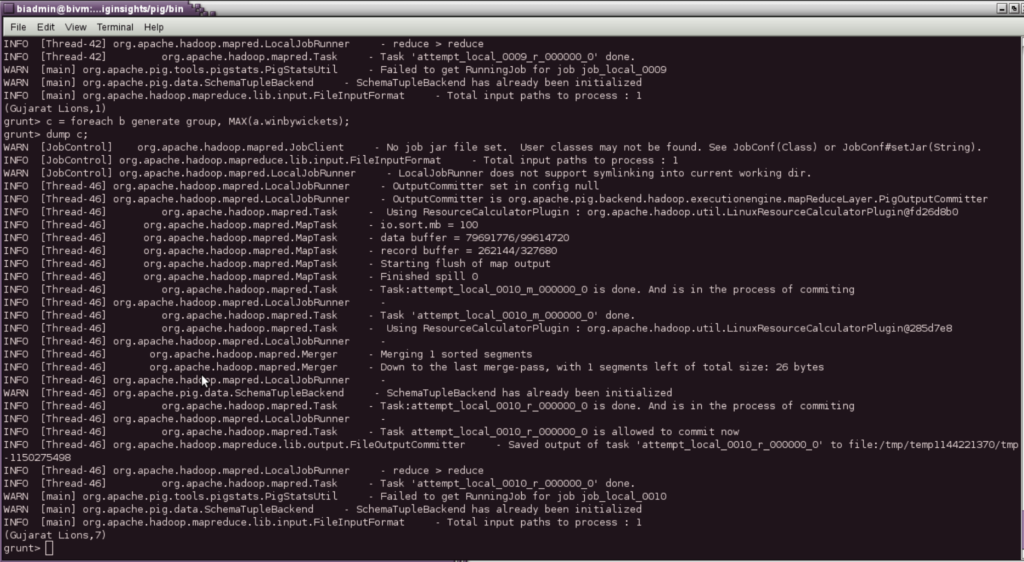
BY WHAT MAX MARGIN A TEAM HAS WON
q = group data by winner;
max = foreach q generate group, MAX(data.winbyrun);
dump max;
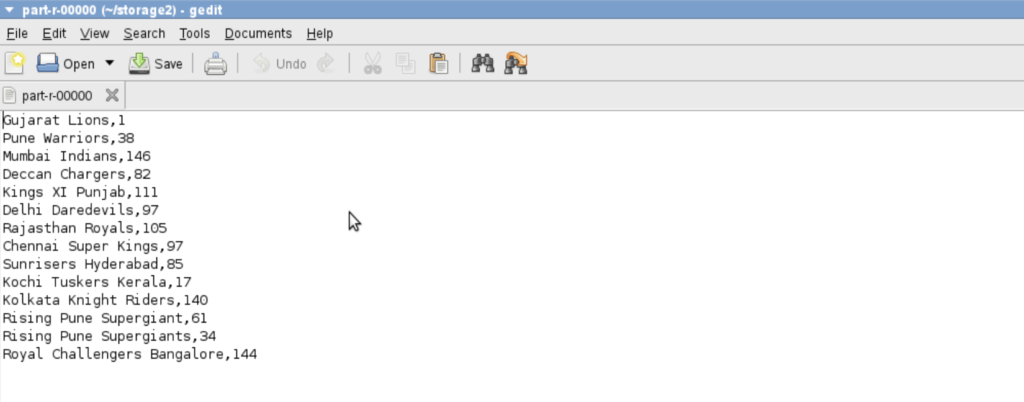
WHICH CITY HAS HOSTED HOW MANY MATCHES
a = group data by city;
b = foreach a generate group , COUNT($1);
c = order b by $1 asc;
dump c;
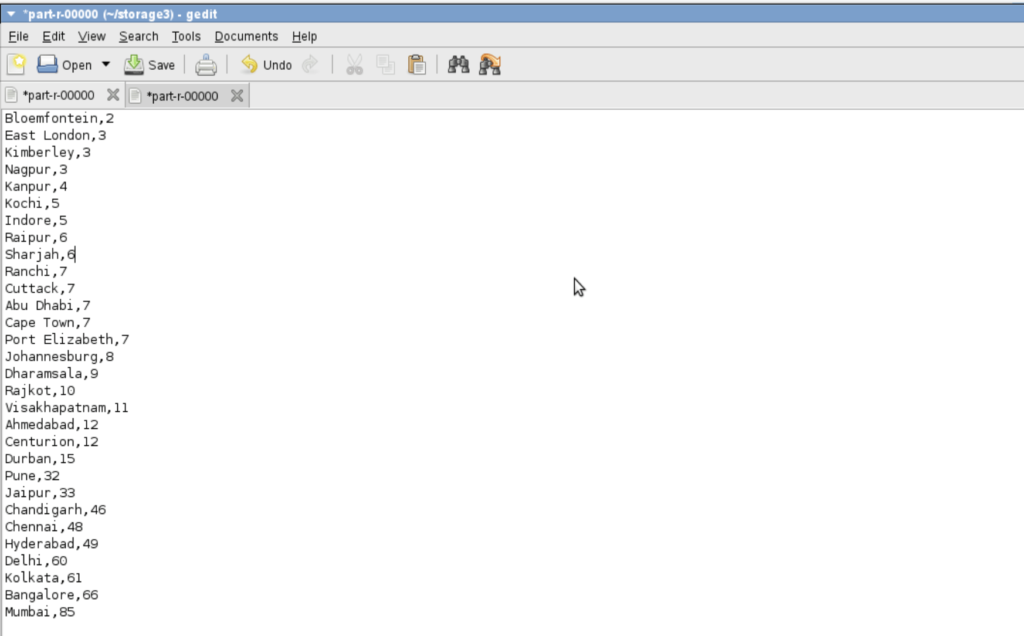
WHICH BATSMAN HAS PLAYED HOW MANY DELIVERIES
a = group data by batsman;
b = foreach a generate group ,COUNT($1);
c = order b by $1 desc;
STORE c into '/home/biadmin/MAXBALLFACEDBYBATSMAN' using PigStorage(',');
WHICH BOWLER HAS BOWLED HOW MANY DELIVERIES
a = group data by bowler;
b = foreach a generate group , COUNT($1);
c = order b by $1 desc;
STORE c into '/home/biadmin/MAXdeliveryBOWLER' using PigStorage(',')
WHICH BOWLER HAS BOWLED HOW MANY NO BALLS AND WIDE BALLS
split data into h if noballruns==1 , i if wideruns==1;
a = group h by bowler;
b = foreach a generate group ,COUNT($1);
c= order b by $1 desc;
a = group i by bowler;
b = foreach a generate group ,COUNT($1);
c = order b by $1 desc;
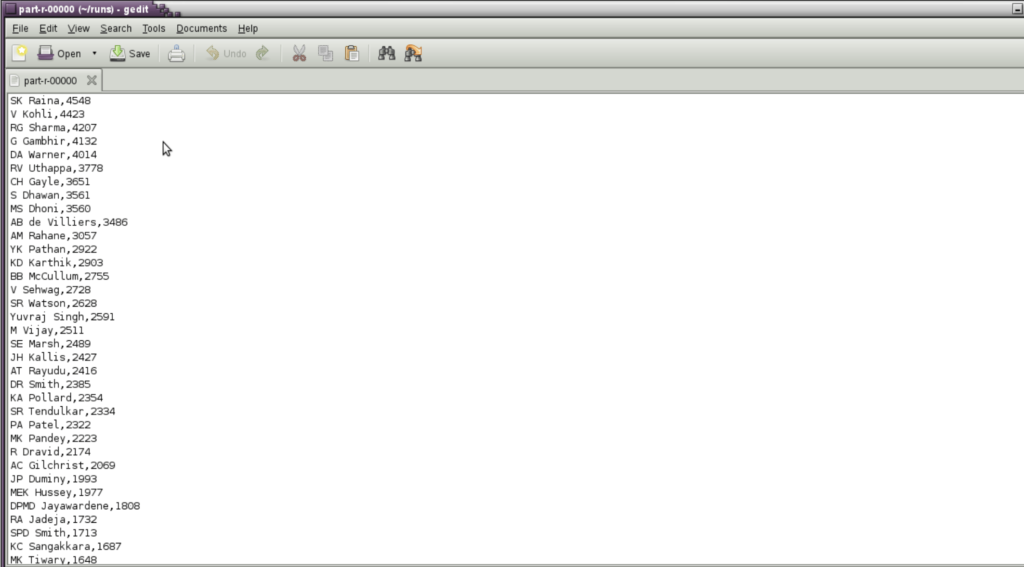
NUMBER OF RUNS SCORED BY EACH BATSMAN
a = group data by batsman;
b = foreach a generate group,SUM(data.batsmanruns);
c = order b by $1 desc;
STORE c into '/home/biadmin/runs' using PigStorage(',');
Conclusion
In this blog, we have covered the basics of Big Data and Hadoop with hands-on practice on Pig Latin. Feel free to ping me with any doubts.
Still Curious? Visit my website to know more!
For more interesting Blogs Visit- Utkarsh Shukla Author
Feature Image Link – https://www.pexels.com/@utkarsh-shukla-204757820/

