
In this Big Data world parallel processing or parallel computing is the solution to faster processing and computation for incoming big data into the system. Although in most cases the CPU with multiple cores are used for parallel processing when it comes to massive parallel processing CPU-based algorithms or multi-core CPU-based algorithms are not fast enough to give a solution in a reasonable amount of time. This gives rise to GPU which was initially used for gaming purposes, graphic and image processing etc. Furthermore the concept of DPU (Data Processing Unit) for massive big data computation in a very small amount of time by using multiple CPUs and multiple GPUs.
CPU (Central Processing Unit)
Let’s start understanding CPU from the basics, let’s consider the CPU from your personal computer this CPU is connected with an in-memory(RAM), a hard drive and NIC (network interface controller), when you upgrade your PC for gaming or video editing purpose you will get an extra GPU attached to CPU and for faster memory access SSD can be an option nowadays. so below is the basic CPU block diagram.

When we specifically talk about CPU in common PC it has 4 to 8 flexible cores clocked at 2 to 3 GHz, CPUs at data centres can have more cores and clock speed. multiple cores allow parallel data processing or parallel threads at the same time with greater ease and high clock speeds mean faster processing. An ALU (Arithmetic and logical unit) is important in a CPU core, which is responsible for arithmetic and logical operations. CPU contains fewer but powerful cores while GPU can have a lot of cores but less power in terms of clock speed.

vCPUs:
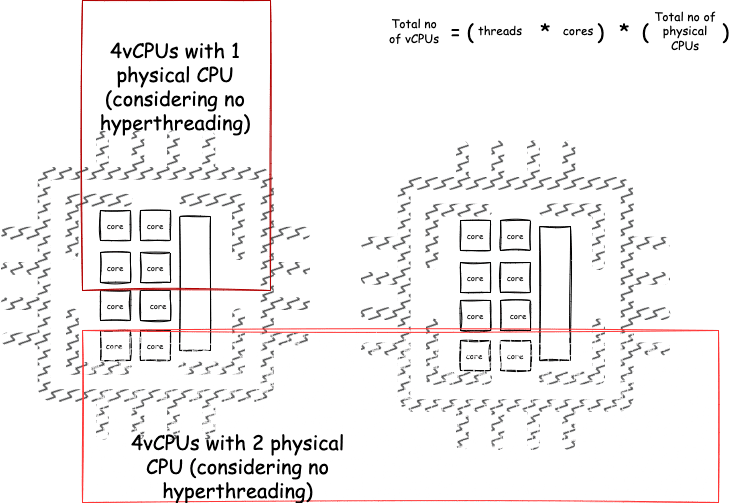
You have heard the term vCPU if you are working with cloud providers most of their instances have vCPUs, Virtual CPU host on cores of a physical CPU resides at the data centre, for a specific amount of time, the multi-core CPUs at the data-centre are of very high prices for a lesser instance there can be less requirement of CPU and its cores, hence we can use the physical CPU from data centres with fewer cores as a virtual CPU for a smaller instance.
Given a physical CPU, Intel Xeon Platinum R8282 processor with CPU specifications number of cores is 56 add number of threads 112 according to above formula for calculating vCPUs use the number of vCPUs is :

= (112 *56) * 1 = 6272 vCPUs
GPU (Graphics Processing Unit):
From the above basic CPU, information let’s learn more about CPU and GPU by comparing both of them and why from gaming and image/video processing, GPU is nowadays used for computations deep learning neural networks and artificial intelligence as well. When it comes to normal computations like arithmetic operations and logical operations CPU is the faster one but when it comes to large matrix multiplications and parallel algorithms GPU takes the number one spot coming first so why GPU and matrix multiplication? That is because most machine learning deep learning algorithm uses matrix multiplication, for example, in neural networks the output y(l)(j) of neuron j in a fully connected layer l is given by
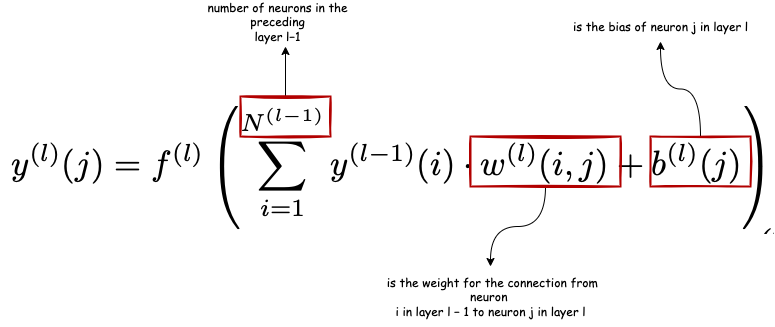
These previous weights in the equation can be stored in a cache associated with cores, and the multiplication can happen in parallel using thousands of cores that a GPU has, these cores are having less clock speed or weaker cores but are efficient in parallel computations and also each core has its own ALU.
CUDA (Compute Unified Device Architecture)describes a proprietary language by NVIDIA which is based on C and contains some special extensions to enable efficient programming. The extensions mainly cover commands to enable multithreading on GPU and to access the different types of memory on the GPU.


All cloud providers provide:
- Compute Optimised instances – high-performing processors, a lot of in-memory (RAM).
- Accelerated Computing (hardware-based compute accelerators such as Graphics Processing Units (GPUs), Field Programmable Gate Arrays (FPGAs)
Field Programmable Gate Arrays
FPGA stands for Field Programmable Gate Array, essentially it’s a piece of hardware that can be programmed as many times as the user wants and it can convert or implement any arbitrary equation into the form of the boolean equation, consequently, implement this as combinational and sequential logic. Simply put, an FPGA can be used to implement any logic function. Unlike graphics processing units (GPUs) or ASICs, the circuitry inside an FPGA chip is not hard etched—it can be reprogrammed as needed. This capability makes FPGAs an excellent alternative to ASICs, which require a long development time and a significant investment to design and fabricate.
FPGA-based instances provide access to large FPGAs with millions of parallel system logic cells. You can use FPGA-based accelerated computing instances to accelerate workloads such as genomics, financial analysis, real-time video processing, big data analysis, and security workloads by leveraging custom hardware accelerations. Designers can build a neural network from the ground up and structure the FPGA to best suit the model. FPGAs can offer performance advantages over GPUs when the application demands low latency and low batch sizes.
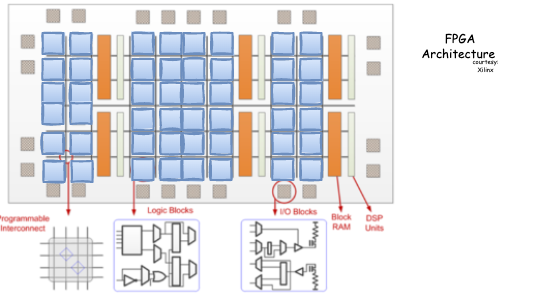
Compared with GPUs, FPGAs can deliver superior performance in deep learning applications where low latency is critical. FPGAs can be fine-tuned to balance power efficiency with performance requirements.
DPU (Data Processing Unit)
In a computer architecture CPU has multiple responsibilities such as running your application, performing computations, and at the same time it plays the role of data traffic controller moving data between GPU, storage, FPGA and others, the CPU is more computer-centric thus came a requirement of data-centric architecture. The new architecture should give resources direct access to the network allowing the task what they do best.
The data processing unit or DPU should take the role of a data traffic controller offloading the CPU from this IO-intensive task but doing it orders of magnitude more efficiently than the CPU, specifically the DPU should be sending and receiving packets from the network encrypting and compressing the immense amount of data around the servers and running firewalls to protect servers against abuse. The DPU should enable heterogeneous compute and storage resources distributed across servers to be pooled to maximise utilization and in doing so reduce the total cost of ownership of the computer and storage resources. The data engines such as the DPUs will enable data centres to reach the efficiencies and speeds necessary to compute large volumes of data and many cloud ETL products provide DPUs in a distributed way to perform the data processing, transformation and loading.

AWS provides an ETL server-less service named AWS glue, AWS glue use DPUs and these DPUs become worker nodes and perform in-memory computations. There are different worker types in AWS Glue.
- The standard worker : 16 GB memory, 4 vCPUs of compute capacity, and 50 GB of attached EBS storage with 2 Spark executors .
- G.1X worker : 16 GB memory, 4 vCPUs, and 64 GB of attached EBS storage. (1 Spark executor = 1 DPU)
- G.2X worker : twice as much memory, disk space, and vCPUs as G.1X worker type. (1 Spark executor =2 DPU).
Key Concepts:
- Algorithms can be sequential or can be made parallel, some perform well sequentially and some of them perform exceptionally faster with parallel computations.
- More the CPU core, the more threads available for parallel computations/processing.
- A single CPU can have multiple cores, hence CPU alone can handle parallel processing until there is a requirement of massively parallel processing more than thousands of threads processed at the same point in time.
- GPU has thousands of cores and has API like CUDA for programming them for computations.
- In Distributed computing there can be more than one instance that can have CPUs/DPUs or CPU-GPU or DPU-vCPUs or DPU-vCPUs-GPUs. The data is partitioned and each partition is assigned to each instances / DPUs. Each instance can again do the massive computations parallel using the cores.
- Distributed computing can be done faster if the memory involves is in-memory (RAM), The apache Spark way. A lot of Cloud providers provide instance for computing massive data in an in-memory parallel-distributed fashion.
- Distributed computing can be done using lot of memory (HDD/SSD) and less RAM, creating a lot of replicas of partitioned data for fault tolerance and applying MapReduce.

Shrikant Gourh
Senior Consultant at StatusNeo



2 comments
Thank you for your shening. I am worried that I lack creative ideas. It is your enticle that makes me full of hope. Thank you. But, I have a question, can you help me? https://www.binance.com/en/register?ref=P9L9FQKY