

S3 stands for “Simple Storage Service” and helps you store your information in the Amazon cloud. Typically, it is one of the first services that was proffered by AWS. S3 is an object storage service that offers industry-driving versatility, information accessibility, security, and execution.This means customers of all sizes and industries can use it to store and protect any amount of data for a range of use cases, such as websites, mobile applications, backup and restore, archive, enterprise applications, IoT devices, and big data analytics.
Amazon S3 gives simple techniques to use management features so you can organize your data and configure finely-tuned access controls to meet your specific business, organizational, and compliance requirements.
S3 provides developers and IT teams with secure, durable, highly scalable object storage. Furthermore, it’s easy to use with a simple web services interface to store and retrieve any amount of data from anywhere on the web
Question arises, what s3 really is?
Multiple answers can be formulated for this question but they all lead to a common key point which is Storage.
- S3 is a safe and secure place to store the files.
- It is Object-based storage, meaning you can store the images, word files, video files, audio files, pdf files etc.
- The files which are stored in S3 can be from 0 Bytes to 5 TB.
- It provides the capability of massive storage depending on the need of the user.
- The interesting part is that the files are stored in Bucket. On imagination it looks similar to a physical bucket but totally different underlying programming. Well a bucket is like a folder available in S3 that stores a file.
- S3 is a universal namespace, i.e., the names must be unique globally. Bucket contains a DNS address. Therefore, the bucket must contain a unique name to generate a unique DNS address.
While planning to create a bucket, the URL should look similar to the one given below:

On uploading a file to S3 bucket, you’ll then receive an HTTP 200 code, implying that the file is successfully uploaded.
S3 as a key-value store
S3 is object-based. Objects consist of the following:
- Key- It is simply the name of the object. For example, statusneo.txt etc.
- Value- It’s the actual data inside the object file. The sequence of bytes that makes up the file.
- Version ID- It uniquely identifies the object. It is the generated string by S3 when objects are assigned in Amazon S3 Bucket.
- Metadata-It is the data about data that you are storing. A set of a name-value pair with which you can store the information regarding an object. Metadata can be assigned to the objects in Amazon S3 bucket.
- Sub resources-Sub resource mechanism is used to store object-specific information.
- Access control information-Facilitates on adding the permissions individually on your files.
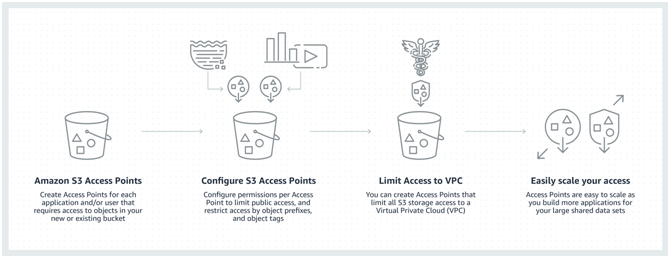
How do S3 access points work?
Amazon S3 Access points makes it easy to manage data access at scale for applications using shared data sets on S3. With the help of Access points one can easily create numerous access points per bucket, figuring out a new way of provisioning access to shared data sets. Access Points gives a personalized path into a bucket, comprising of a unique hostname and access policy that administers the specific permissions and network controls for any request made through the access point.
Creating your first S3 bucket
1. Create an AWS Account and Sign in. After Signing in go to management console and search for S3.
2. Move to the S3 service and the following screen appears.
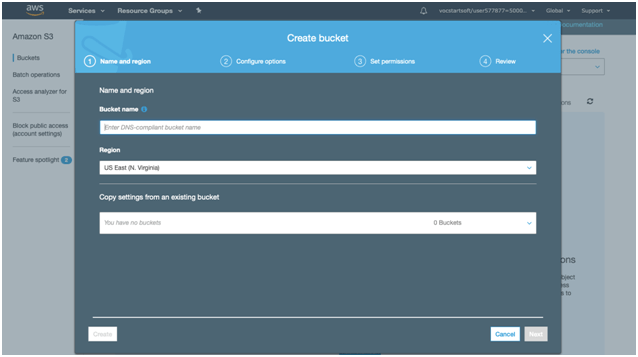
3. To create a S3 bucket, click on “create bucket”. After clicking on the specified button the following screen will appear.
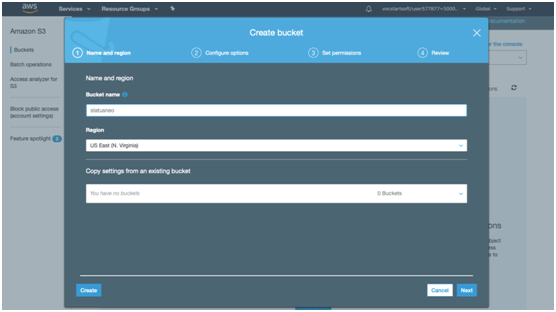
4. Type the bucket name which should look like DNS address, and it must be resolvable. A bucket is just like a folder that stores the objects. A bucket name should be unique. Its name should start with the lowercase letter, must not contain any invalid characters. Precisely it should be 3 to 63 characters long.
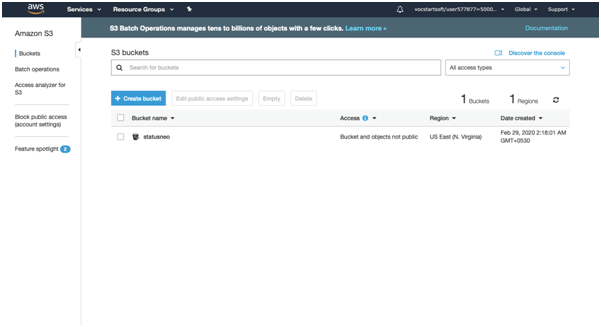
5. Click on “create button” and the bucket will be created.
We have seen from the above screen that bucket and its objects are not public by default, all the objects are private.
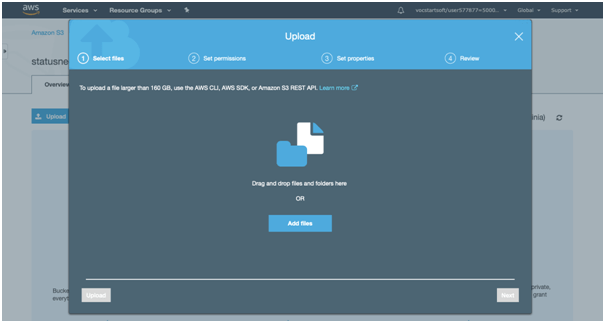
6. Click on any file to upload that file in this bucket. We are using “statusneo.png” for the upload. On clicking, the screen appears and then press “upload” button. The following screen will appear.
7. Click on the “Add Files” button.
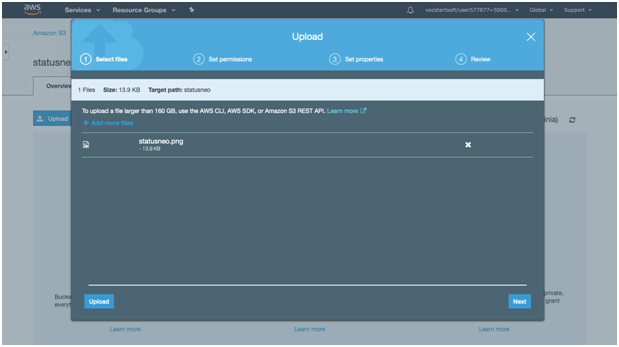
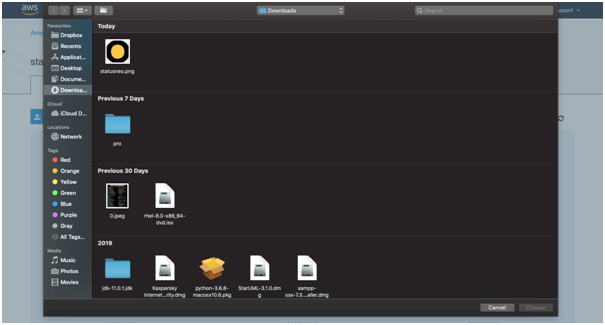
8. Add the required file of your choice. Like here we have chosen “statusneo.png” file.
9.) Click on “upload” button.
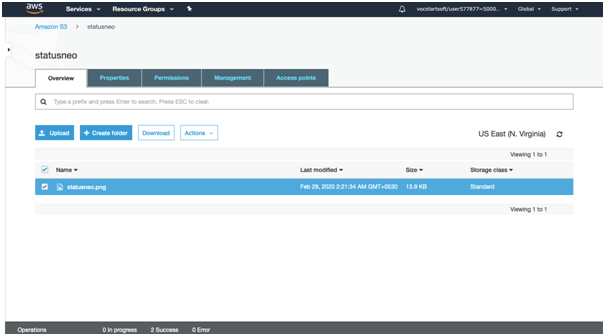
From the above screen, we observe that the “statusneo.png” has been successfully uploaded to the bucket “statusneo”.
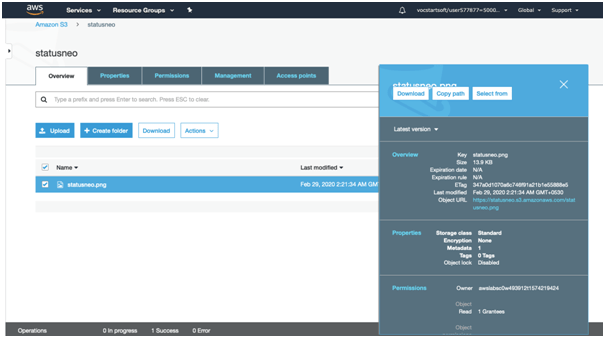
10. Move to the properties of the object “statusneo.png” and click on the object URL to run the file appearing on the right side of the screen
11. After clicking on the URL the page shown below will appear.

From this screen it is prevalent that we don’t have the access of the objects in the bucket.
12. To overcome from the above problems, we need to set the permissions of a bucket, i.e., “statusneo” and unchecked all of them.
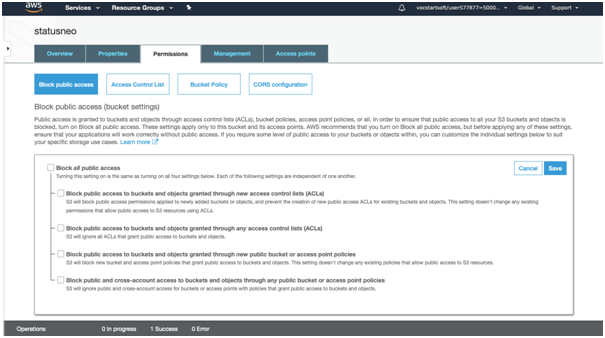
13. Save these permissions.
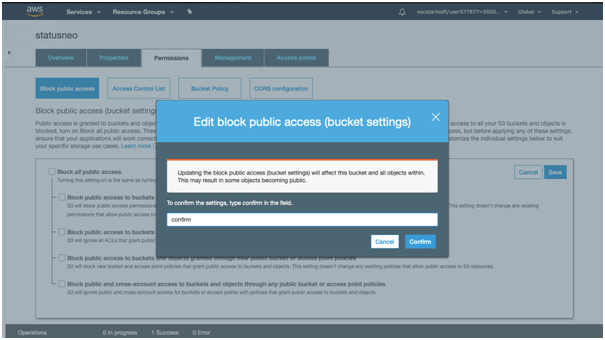
Now type “confirm” in a textbox, then click on the “confirm” button.
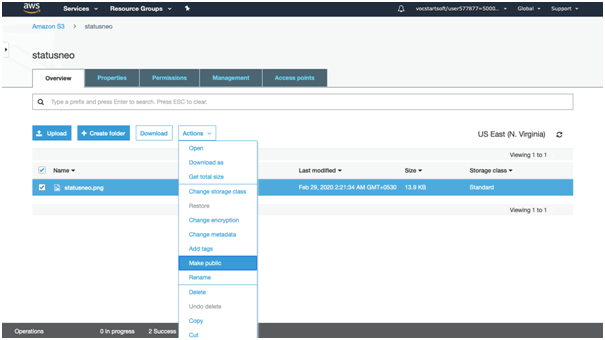
14. Go the overview page, select the object “statusneo” and then click on “actions” and make them Public.
15. Now, click on the Object URL of an object to run the file.
It is observed that primarily all our objects are assigned with private permissions, so we need to manually change them in order to view our files.
S3 – Pros & Cons
Pros
- AWS S3 is a secure service with variety of encryption services available, it is a best bet. You can encrypt most of our data using AWS KMS (Client-Side) encryption where we manage the key and the data is secure on the servers.
- You can also download your data from a bucket and can also give permission to others to download the same data. You can download the data at any time whenever you want.
- You can also grant or deny access to others who want to download or upload the data from your Amazon S3 bucket. Authentication mechanism keeps the data secure from unauthorized access.
- S3 is used with the standard interfaces REST and SOAP interfaces which are designed in such a way that they can work with any development toolkit.
- In order to overcome the cost of maintaining the data nodes on Hadoop EMR we switched to better storage grounds called as S3, where the same data in its original form can be stored.
- S3 offers infinite measures of scaling and also best availability which attracts our attention, in-order to make sure of our app’s maximum availability.
- Amazon S3 offers security features by protecting unauthorized users from accessing your data.
- S3 is very durable and easy to manage.
Cons
- The cost of IO is comparatively higher when transferring the data to glacier archives. The cost should be minimal or negligible while the data transfer happens between the AWS resources.
- Scanning for the object size (Get Size) using the new AWS S3 console is considerably slower. AWS team must maintain a hourly or daily metadata backup of the bucket or object structure which would fetch the results faster.
- The outages should be minimized in future because many businesses were impacted by the long lasting outage.

