
Big Data is growing!
From the evolutionary emergence of Big data industry in the decision-making of huge, medium-sized, or small-sized organizations, the market has created a void or say demand for the big data practitioners. Data engineers, analysts, scientists, cloud architects, admin, and many more profiles seem to be niche with the skyrocketing behavior of data chunks in the servers. According to Statista, Big data market seems to grow to 103 billion U.S. dollars by 2027, more than double its expected market size in 2018.
So, with such high demand, professionals with relevant skill sets are required at a fast pace. In this dire need of proficient data geeks, this article will guide you through how we can add some specific skills that will help us to acquire a desirable job in the big data market. Therefore, below are the top 10 big data technologies that one must inculcate to penetrate into this giant workplace.
List of Top key skills to grab Job in Big data industry
1. Python
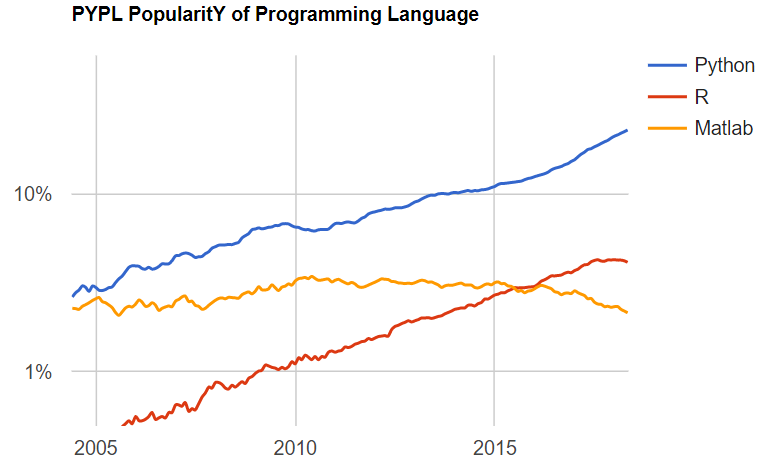
Without any doubt, Python has dethroned Java in the race of most used programming languages due to its simplicity, open-source, and easily available packages. Specifically, in the Data field, all the operations starting from Data collection, exploratory data analysis, data visualization, and machine learning can be achieved using Python language and at no cost. Packages named Pandas, numpy, Scikit-learn, and scipy have revolutionized the culture further with an unlimited source of tutorials and practical projects for self-learning. Thus, Python is the hot tech for all talent-seeking organizations. For a basic idea, you can see that how Python has drastically overruled R and MATLAB.
Read More: Learn how to use Recursion within Python Dataframes
2. Structured Query Language
While working in the Data industry for the past 6 years there was neither any company nor any project that was not implementing Database management with the help of some Structured Query Language. SQL has been evolved with different features, functionalities, serialization/deserialization, and data distribution in the form of Redshift, PostgreSQL, HiveQL, impala, and many more, but the basic idea and most of the syntax are the same. Every month, many job portals have posted thousands of jobs with SQL as their top-seeking tech. Take a look at the top Keywords that have been used by recruiters for the Data Analyst profiles in the Job portals.
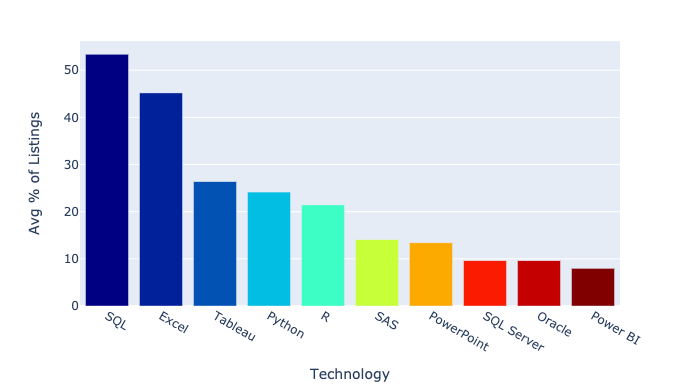
Learning SQL is even more easy and can be achieved in a maximum of 2 week’s time by self-learning. Tutorialpoint can be a good platform to start for beginners, whereas doing hands own Hackerrank is nice to initiate with.
3. Data Visualization Tool (Tableau/ PowerBI)
When we have petabytes of data in the raw form, then we do need Business intelligence tools that will help to create and understand the patterns using visual aids. In today’s market, the most popular data visualization tools are Tableau and Power BI that most organizations are expecting for their businesses. Thus, the job demands are changing their tangents accordingly. I think, from the below graph one can get a better understanding of the interests of Job seekers while comparing several BI tools.
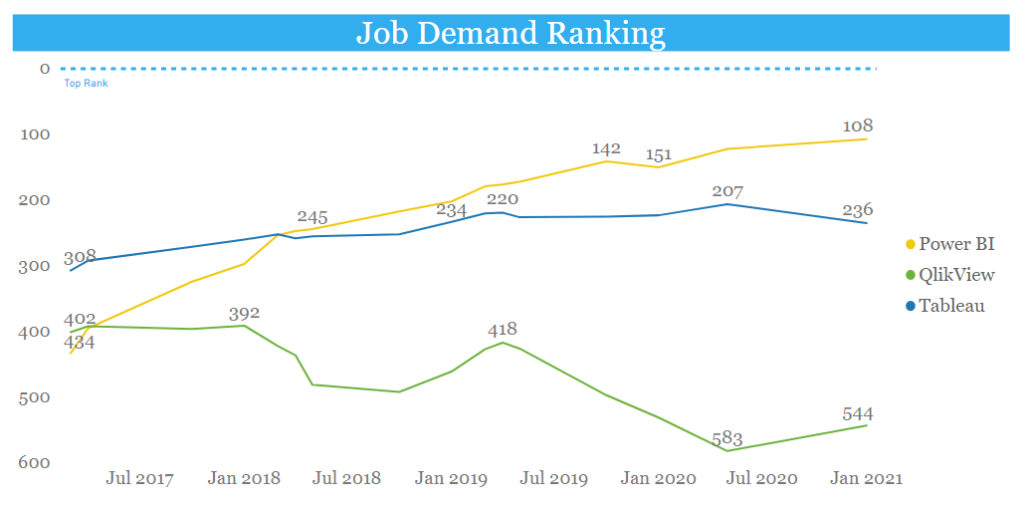
Which tool is better: Tableau or Power BI will also remain in the debate, but for the fresh pupils learning any visualization tool will be an asset. Power BI has a free desktop version to start with, whereas Tableau has paid one to buy the license. No doubt Tableau offers a 14-day trial desktop version with limited functionality, but one needs sufficient time to grasp the nerve of data visualization. For business, it is not necessary to know how many charts, graphs, or visualizations one can create, but it is necessary to understand which chart is suitable for which kind of data, or what purpose that dashboard will serve.
4. Spark/ MapReduce
Both Spark and Mapreduce are the execution engines that run on the top of the Hadoop ecosystem and have revolutionized the way traditional database query engines were performing. MapReduce is, without any doubt, an obsolete execution engine but before understanding the process of MR and its basic technique to crawl the data within the Hadoop ecosystem we cannot switch to Spark. Spark is another execution engine with high performance and low latency execution in the cluster. Both facilitate different data distribution techniques with highly scalable tuning methods. Thus, starting from the basics one must inculcate the knowledge of Hadoop, HDFS concepts, YARN, optimization techniques, storage methods, caching, and most importantly the architecture.
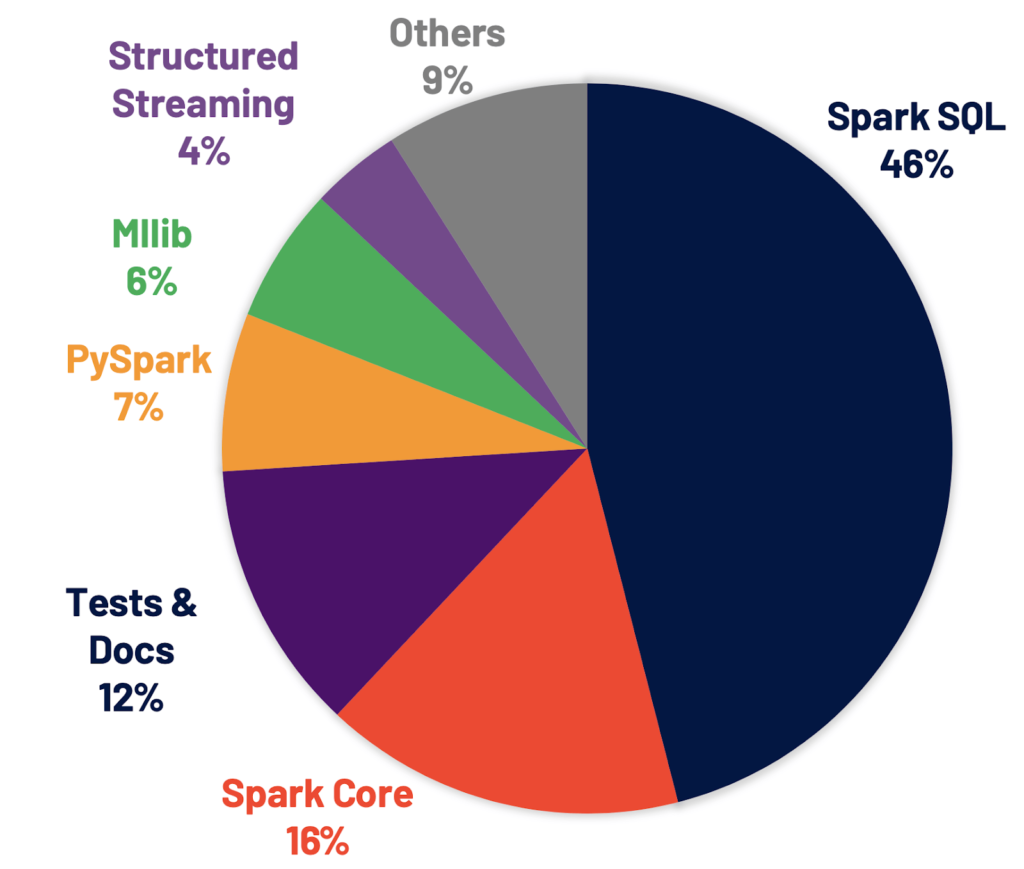
Most companies have seen a dire need to hire Spark or Big Data engineers for better management of data and creating ETL (extract, transform, load) pipelines. Nevertheless, Spark has diversified its usage as shown below in the pie chart.
5. NoSQL (MongoDB, Cassandra, etc)
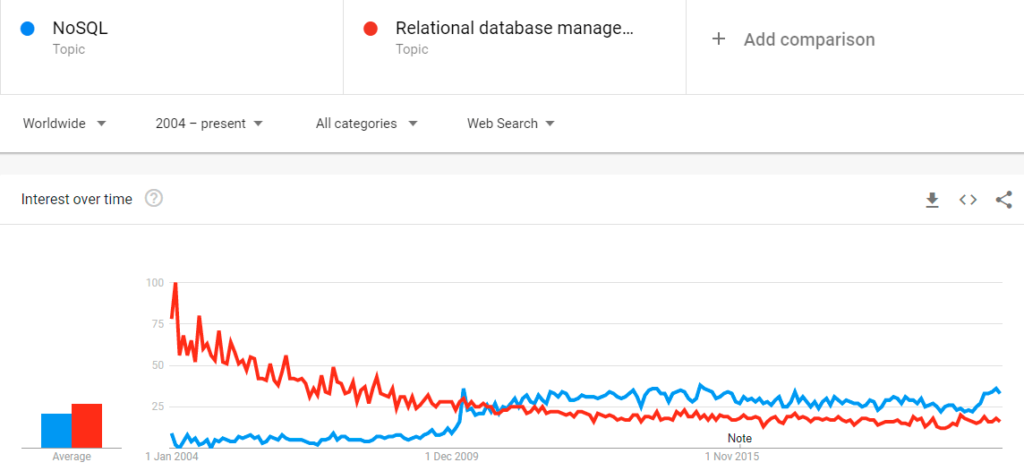
NoSQL database has gained popularity with its flexible ability to create new structures. It is mostly considered a great substitute for RDBMS as it is very quick with transactional data. More specifically NoSQL is a non-relational database system that permits us to save and extract the unstructured data with the key-value pair data structures. Just a decade older technology has passed the traditional RDBMS and now became more popular in the big data industry. Even the market share of relational databases is 61%, but NoSQL software like MongoDB and Cassandra has drastically occupied 39% of the market share. MongoDB was first patented by organization 10gen, later renamed MongoDB Inc. Learning MongoDB is an edge over other Big Data geeks who are still not updated with the flexible non-relational database. This can be achieved by MongoDB university which is free to absorb with some paid certifications. Below google trends show the popularity graph between these two DB techs from the past few years.
I hope this article might help you to penetrate the Big data industry in due course of time by increasing your proficiencies in discussed skills. Moreover, join our Big Data family by applying to Statusneo open jobs. Keep upskilling and keep upgrading yourself.
If you like this post then do share this with your friends and job seekers.


