
Natural language processing (NLP) is the relationship between computers and human language and essentially a teaching machine to understand human language and since it is all about human language. NLP is the root element of AI. Natural Language Processing (NLP) uses algorithms to know and manipulate human language. This technology is one of the foremost broadly applied areas of machine learning. It’s observed that AI continues to expand, so is the demand for NLP professionals. It has an extensive selection of business use cases that are mostly text-based, i.e. text mining is widely employed in various industry sectors.
NLP market will increase and to my knowledge, NLP budgets are growing. NLP has huge potential, which is the core reason companies are already investing in it. There’s an increase in the NLP budget by 30% in large and small companies.
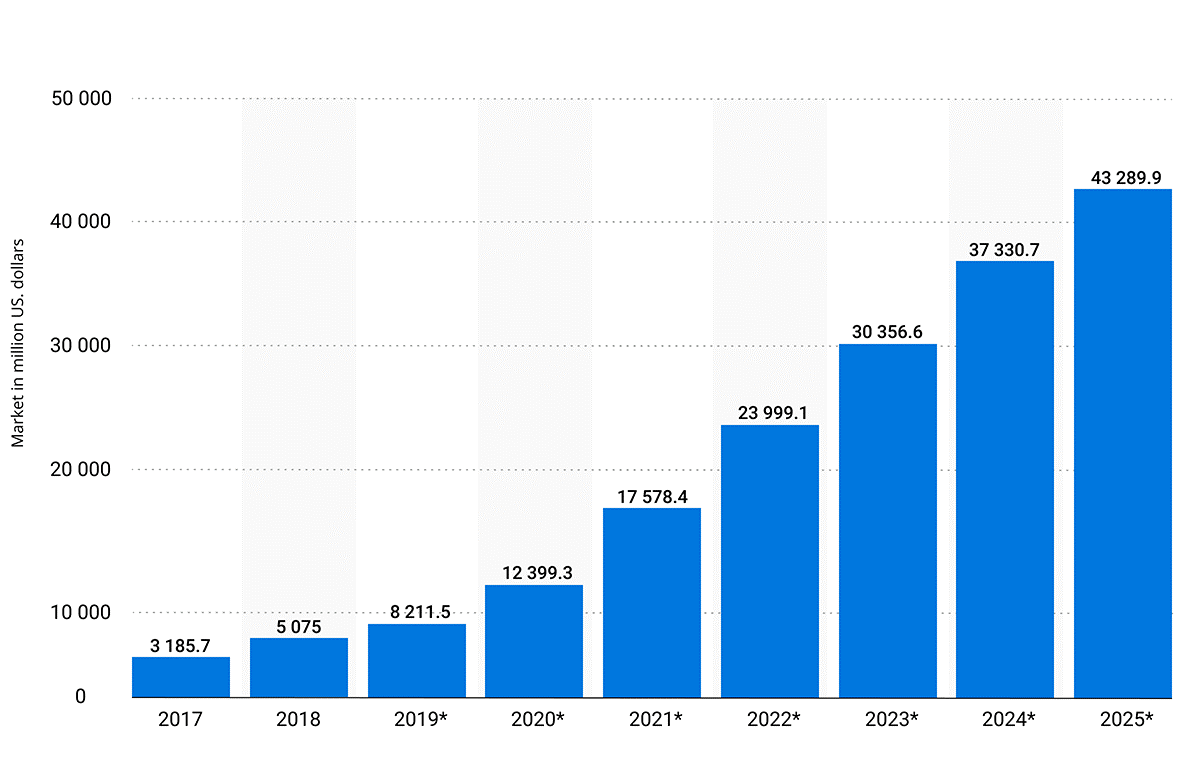
Revenues from the natural language processing (NLP) market worldwide from 2017 to 2025 (in million U.S. dollars)
What exactly are companies using NLP for?
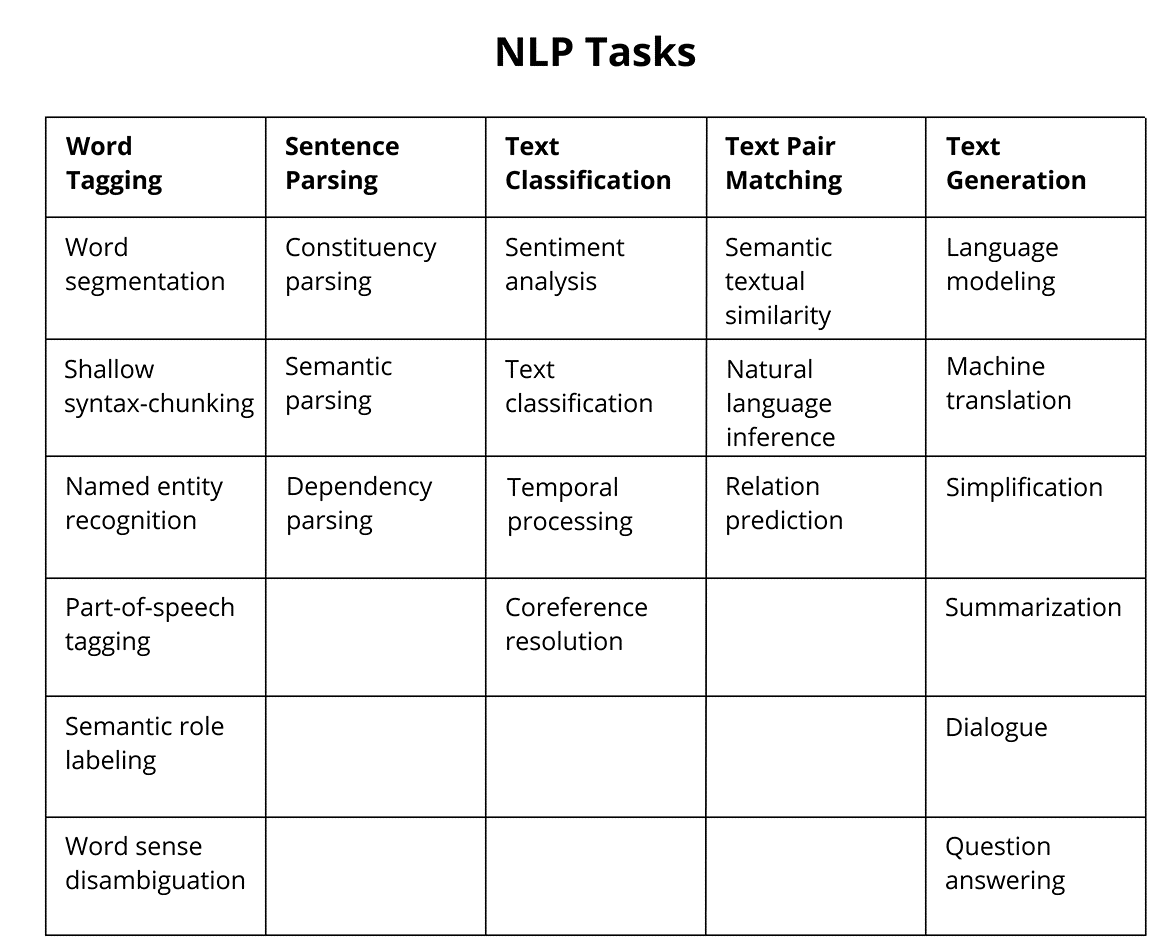
- The most popular applications of NLP technologies: The four most popular applications of NLP are Document Classification, Named Entity Recognition (NER), Sentiment Analysis, and Knowledge Graphs. Document classification and NER are the most popular use cases in an organization. De-identification is a common use case in the Healthcare industry.
- Sources of Data: Databases and multiple forms of data files(pdf, txt, doc, etc.) are popular data sources used in NLP projects. One-third of the organization (36%) used a text annotation implement for labeling training data for NLP.
- Accuracy, performance, and scalability in NLP libraries: Accuracy points to pre-trained models that get used in multi-stage pipelines in NLP libraries. These models let the user’s input text get mapped with common outputs (e.g., tokens, lemmas, part-of-speech (POS), similarity, and entity recognition), but customizing models has challenges. Accuracy is paramount for NLP technology but especially in highly regulated industries, such as healthcare and financial services, where compliance and safety are of the utmost importance. Accuracy is the essential criterion they use when they evaluate NLP libraries and NLP cloud services.
- NLP libraries: Spark NLP and spaCy are the most popular library. Allen NLP, a newer PyTorch- based library for NLP research, was the third most popular library. The most popular libraries in key industry sectors are healthcare, technology, and financial services.
- NLP cloud services: Four popular NLP cloud services are GCP, AWS, Azure, and IBM cloud. Google cloud is popular among companies that are in the early stages of adopting NLP.
Use Cases
Given the relative mix of Healthcare and Finance, it’s no surprise that document classification, named entity recognition (NER), and sentiment analysis topped the list of use cases. NER models seek to automatically extract named entities (for example, “company name” or “location”) from unstructured text. Over one-third, i.e. (39%) of all companies use NLP for entity linking and knowledge graphs.
These use cases are classic applications of NLP. Since late 2017, breakthroughs in using deep learning for natural language have raised the level of accuracy for predicting the next word or character in a text sequence, as well as training leverage based on transfer learning. You may read about these approaches described as embedded language models, transformers, and Sesame Street (ELMo, BERT, ERNIE). Use cases such as translation, NER, and summarization have undergone significant advances, while others such as question answering and link prediction have now become more practical. We expect to see the latter deployed in industrial applications more frequently.
The main NLP use cases that production system supports are–
- Document Classification
- Named Entity Recognition
- Sentiment Analysis
- Entity linking / Knowledge Graph
- De-identification
- Summarization
- Intent Classification / Chatbot
- Translation
Conclusion
Overall, an approximate formula for NLP adoption emerges as the breadth of industry applications grows as the level of accuracy increases, especially for use cases that must understand or generate text. Growth in business applications is due to how NLP enhances automation and scale, enabling the more complex use cases to become cost-effective. While on the surface we talk about text-based data sources as being “unstructured” or “semi-structured,” the semantics that is embedded in the text are often highly structured. This is especially the case in the more formal uses of text, including legal contracts, financial disclosures, sales reports, patent applications, policy hearings, and scientific articles.
As advances in NLP lead to AI applications that can leverage those embedded meanings within the text, and generate text summaries that are more readily “consumed” by both people and machines, we will probably see much broader industry adoption of NLP to date, deep learning applied in NLP has been focused on predicting the next word or character in a text sequence—with ongoing improvements in overall accuracy. Related techniques are proving to be powerful in other ways—e.g., for predicting links in a graph or missing relationships between objects in a database. These additional uses of advanced NLP open a much broader range of applications in business areas such as legal practices, supply chain management, accelerated development of pharmaceuticals, material science, and even AI used for developing public policy.
It is noted that the state of NLP in the industry poses somewhat of a dilemma for cloud providers. On one hand, the cloud providers are among the largest AI teams and top R&D talent, they have business units that gain highly valuable, large amounts of labeled data, plus they own the computer resources required to train largely machine learning models for NLP, which often have billions of parameters. It makes sense to expose these enormous, high-performance NLP capabilities via SaaS offerings. So many of the NLP applications in business depend on domain-specific uses of language. The cloud providers have been slow to respond to market needs for customizing solutions and extensibility and have pricing strategies that work against other organizations’ integration efforts. The net result is that cloud-based NLP services are perceived as high in cost and low inaccuracy. Given these conditions, plus a long-term trend toward the commodification of deep learning, open-source libraries for NLP have enjoyed adoption based on their relative ease of use and extensibility per application, which results in better overall cost-effectiveness. Tension persists between the power and dominance of tech giants, which favor one-size-fits-all service offerings, and the effectiveness of open source libraries that address many specific business opportunities.