RAG stands for Retrieval Augmented Generation. It is a technique to give proper contexts for the asked user-query from the curated knowledge base.It enhances and optimizes the output of LLMs i.e. large language models.
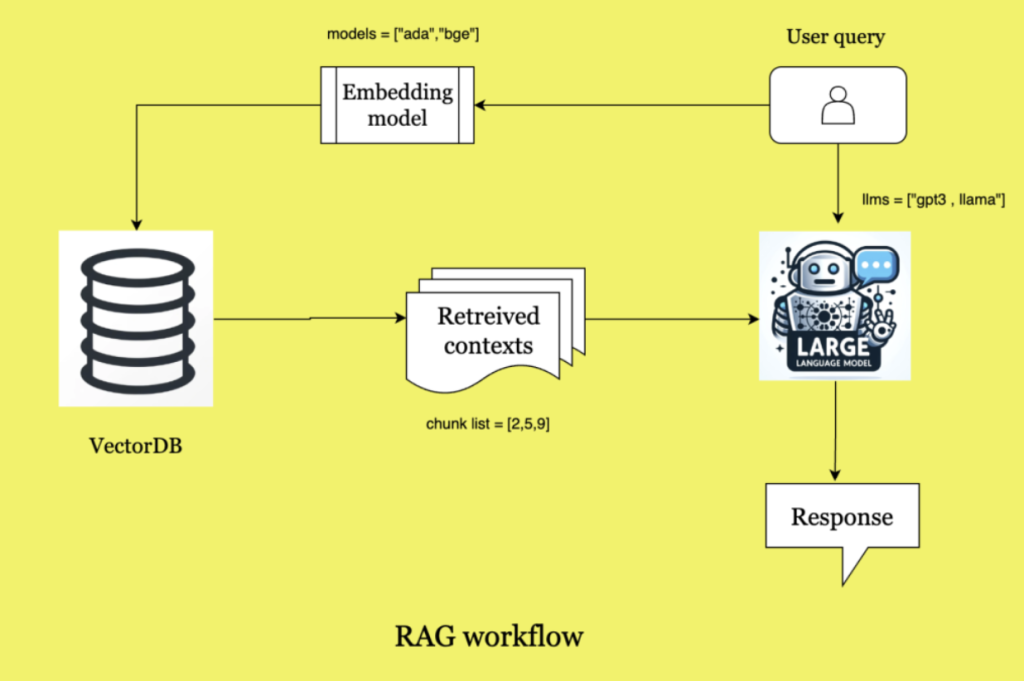
This is the normal workflow of RAG.
Let’s try to understand the above diagram using an example. Let’s say a user wants to ask a query “ What is the impact of climate change ? ”
This query will be converted into vectors using any embedding model. Few examples are shown in the diagram.Let’s understand the vectorDB part first. VectorDB are used to have permanent access to contexts for our LLM to help him answer the user questions. Let’s say we have a pdf report of climate impact on the world. We will save this pdf report in the vectorDB.We will break down the pdf into smaller chunks and then vectorize these chunks using any embedding model and then store these vector chunks in the vectorDB.
So, now we have vectorized chunks of our climate impact pdf report in vectorDB and also the user asked query’s vectorized form. Using this vectorized query , semantic search operation will be performed on the vectorDB to find the most relevant contexts to the query.These retrieved contexts , the user query and the pre established prompt will go as an input to our LLM and then the LLM will answer it and generate the appropriate response.
Let’s implement this in code.
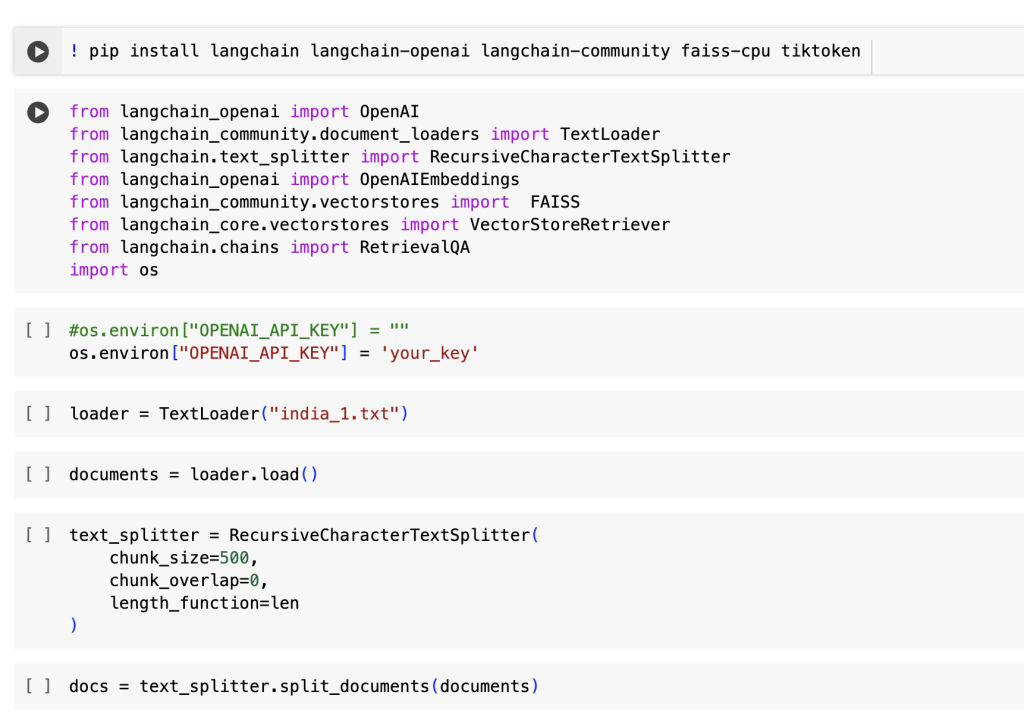
Cell 1 : Installation of the required packages.
Cell 2: Importing all the required packages and classes.
Cell 3 : Setting up the Open-ai key.You can get yours here : https://openai.com/blog/openai-api
Cell 4-5 : Creating an object of Text Loader class and loading up the text file.
Cell 5-6 : Creating a recursive character splitter object and splitting the text file into chunks ,We have kept the chunk size at 500 characters and overlap as 0 but for better context understanding between chunks , it is good to keep some overlap of characters between chunks.
Cell 7 : Number of chunks created.
Cell 8-9 : Creating embeddings for the chunks using open-ai’s text ada 002 default model.
Cell 10-15 : The query is being converted to vectors and then using vector similarity search operation we are finding the best similar chunks with scores. The lower the score , more similar it is.

Cell 16-17 : Creating a Retrieval QA chain.
Cell 18-20 : Asking the user query and the RAG pipeline answer for it.
Cell 21-22 : Saving and retrieving the faiss indexes.
Here , we saw step by step the RAG pipeline execution in python. For more explanation , can refer the below links.
Reference :
YouTube link : https://www.youtube.com/watch?v=q25LjUtsdbs