
Introduction:
Imbalanced data presents a prevalent issue in machine learning, characterized by one class containing significantly more observations than the other, leading to biased models and below average performance, particularly on the minority class. Imbalanced learning data substantially compromises the learning process since most of the standard machine learning algorithms expect balanced class distribution or an equal misclassification cost.
In this blog, we will dig into various techniques aimed at mitigating the challenges posed by imbalanced data and enhancing model effectiveness. If you’ve ever tackled classification problems, you’re likely familiar with imbalanced datasets, where the distribution of examples across different classes is skewed.
Consider a scenario where a binary classification task involves classes 1 and 0, with over 90% of training examples belonging to just one class. Training a classification model on such data results in bias towards the majority class since models learn predominantly from examples, resulting the problem of class imbalance.
This common issue, termed as the class imbalance or imbalanced data problem, demands effective strategies for reliable model performance.
If you take such imbalanced dataset and plot them, resulting graphs will look something like below:
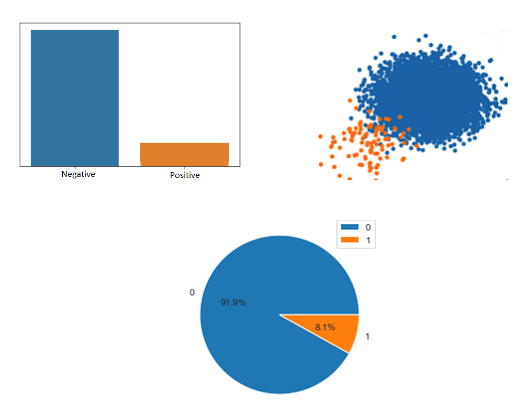
Evaluation Metrics for Imbalanced datasets:
Traditional evaluation metrics like accuracy may not be suitable for imbalanced datasets due to their inherent bias towards the majority class.
Imagine you are trying to teach a computer to tell the difference between lions and elephants in pictures. Now, let’s say you have some pictures and most of them are of lions. This is an imbalanced dataset.
Since accuracy focuses on getting as many pictures right as possible, it doesn’t give much importance to the less common thing – in this case elephants. So, if there are mostly lions and computer just guess lions for every picture, it would get a high accuracy score because it’s right most of the time.
So, when you are dealing with imbalanced data, it’s important to look at other evaluation metrics like precision and recall. Precision will tell how many guessed elephants are elephants in actual and Recall will tell how many actual elephants the computer found. There is another metrics, F1 Score. It takes both precision and recall into consideration. It is a harmonic mean of both precision and recall.
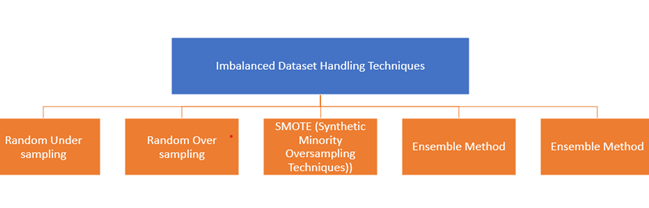
Techniques of handling Imbalanced datasets:
Some of the most common techniques of handling imbalanced datasets are as below:
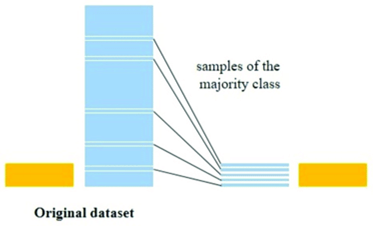
Random Under sampling:
It’s a way to make a dataset smaller by randomly removing some of the examples from the majority group.
This approach is generally used when you have a huge amount of training data with you.
But this is not a good approach as the random removal of samples from the majority class could lead to the loss of valuable information necessary for the model’s learning process. Additionally, the resulting reduced training set might not accurately reflect the overall population. Consequently, a model trained on such data may struggle to generalize effectively when presented with unseen data in the test dataset.
Random Oversampling:
It’s a way to make a dataset bigger by adding more examples from the minority group.
This approach is generally used when we have a lot fewer examples of one class compared to another.
The sole caveat is that replicating the minority class could elevate the risk of overfitting. It’s crucial to bear in mind that when employing the oversampling technique, the division between the training and test sets must be established prior to oversampling. Otherwise, the dataset split might become uneven.
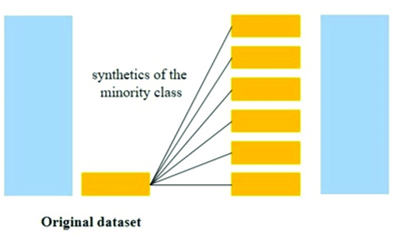
SMOTE (Synthetic Minority Oversampling Technique):
This is also an oversampling technique which generates synthetics examples using K nearest neighbor algorithm.
SMOTE creates new, synthetic examples of the minority class by looking at the existing examples of the minority class and creating new ones that are similar but not exactly the same. It does this by picking a random example from the minority class and finding its nearest neighbours. Then, it randomly selects one of those neighbours and creates a new example that’s somewhere between the two.
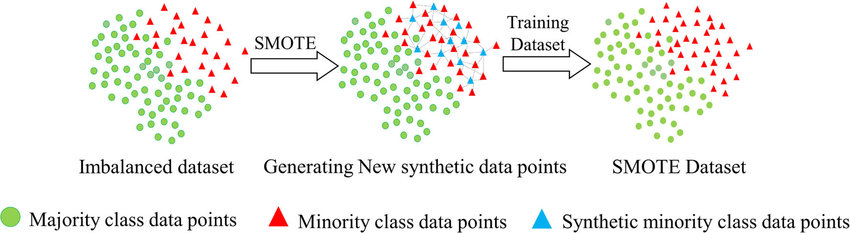
Though, SMOTE is an effective technique, it has its limitations too. With high-dimensional data, finding appropriate nearest neighbors for generating synthetic examples becomes challenging and has increased computational complexity.
Ensemble Method:
Ensemble techniques involve combining multiple models to result in high performing model. There are various techniques to achieve this, such as bagging, boosting, and stacking.
Focal Loss:
Focal loss introduces a new loss function that penalizes the contribution of majority class and focusses more on minority class.
It tries to introduce a modulating factor that decreases the loss for well classified examples and thus reducing the impact of majority class while simultaneously amplifying the loss for misclassified examples.
Conclusion:
We’ve explored five distinct approaches for managing imbalanced data in machine learning classification tasks. Each method comes with its own set of advantages and limitations. Your choice of method should be guided by the specific characteristics of your dataset and the nature of the problem.


