
Spark/Pyspark partitioning is a way to split the data into multiple partitions so that you can execute transformations on multiple partitions in parallel which allows completing the job faster. You can also write partitioned data into a file system (multiple sub-directories) for faster reads by downstream systems.
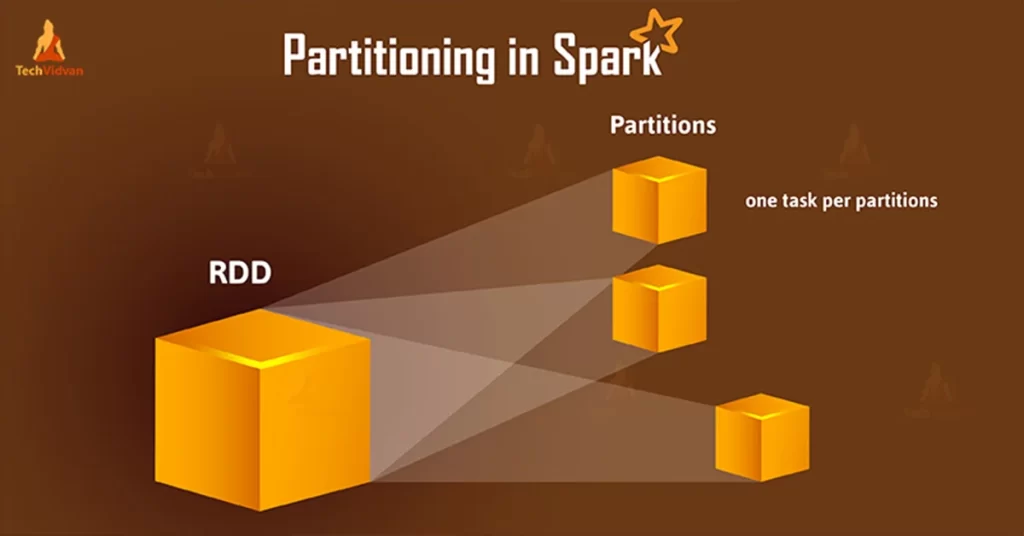
Understanding Spark Partitioning
By default, Spark/Pyspark creates partitions that are equal to the number of CPU cores in the machine.
Data of each partition resides in a single machine.
Spark/Pyspark creates a task for each partition.
Spark Shuffle operations move the data from one partition to other partitions.
Partitioning is an expensive operation as it creates a data shuffle (Data could move between the nodes)
By default, Dataframe shuffle operations create 200 partitions.
what are partitions ?
Partition is a logical division of the data , this idea is derived from Map Reduce (split). Logical data is specifically derived to process the data. Small chunks of data also it can support scalability and speed up the process. Input data, intermediate data, and output data everything is partitioned RDD.
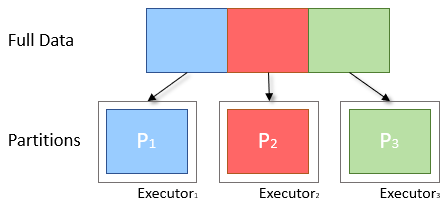
How does spark partition the data ?
Spark uses the map-reduce API to do the partition the data. In input format, we can create a number of partitions. By default, HDFS block size is partition size (for best performance), but it’s possible to change partition size like split.
Factor to consider while partitioning the data
⦁ Avoid having too big or small files:
Having bigger partitioned data will lead too some of the executor doing the heavy load work, while others are just sitting idle. We need to ensure that no executors in the cluster is sitting idle due to skewed workload distribution across the executors. This will lead to increased data processing time because of weak utilization of the cluster.
On the other hand, having too many small files may require lots of shuffling data on disk space, taking a lot of your network compute.
The recommendation is to keep your partition file size ranging 256 MB to 1GB.
How to decide the partition Key(s) ?
⦁ Do not partition by columns having high cardinality. For example, don’t use your partition key such as roll no, employee id etc , Instead your state code, country code etc.
⦁ Partition data by specific columns that will be mostly used during filter and group by operations.
Partition in memory
You can partition or repartition the Dataframe by calling repartition() or coalesce() transformations.
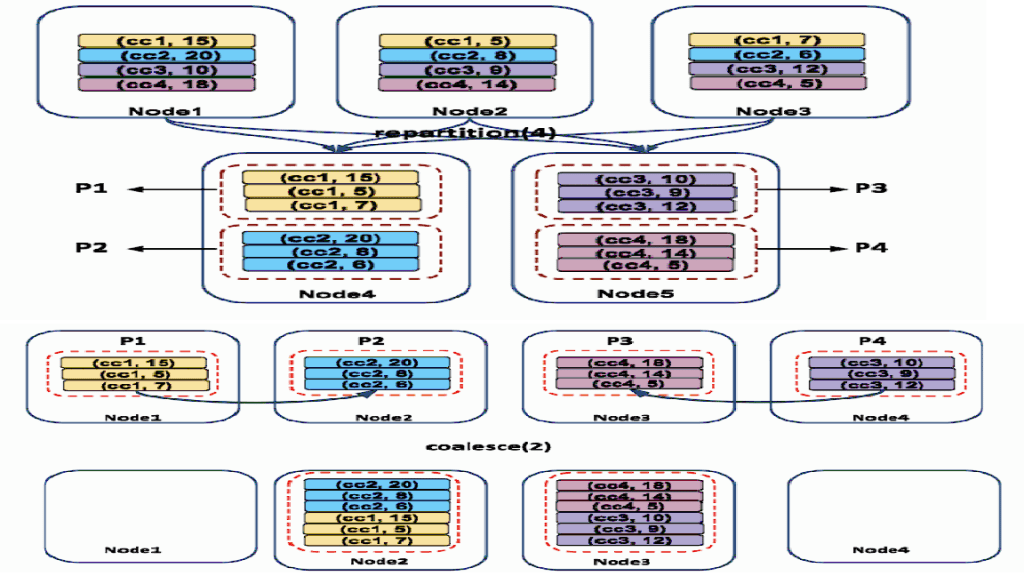
⦁ Coalesce – The coalesce method reduces the number of partitions in Dataframe. It avoids full shuffle , instead of creating new partitions, it shuffles the data using the default Hash Partitioner, and adjusts into existing partitions, this means it can only decrease the number of partitions.
⦁ Repartition – The repartition method can be used to either increase or decrease the number of partitions in a Dataframe. Repartition is a full shuffle operations, where whole data is taken out from existing partitions and equally distributed into newly formed partitions
⦁ Partition By – Spark partition By() is a function of pyspark.sql.DataFrameWriter class which is used to partition based on one or multiple column values while writing Data frame to Disk/File system. When you write Spark Data frame to disk by calling partition By(), Pyspark splits the records based on the partition column and stores each partition data into a sub-directory.
Spark Partitioning Advantages
As you are aware Spark is designed to process large datasets 100x faster than traditional processing, this wouldn’t have been possible without partitions. Below are some of the advantages of using Spark partitions on memory or on disk.
Fast accessed to the data.
Provides the ability to perform an operation on a smaller dataset.
Partitioning at rest (disk) is a feature of many databases and data processing frameworks and it is key to make reads faster.
Hope that is able to explain all the different ways of data partitioning using Spark.


