What is MLOps?
MLOps, short for “Machine Learning Operations,” is a set of practices and principles that combine machine learning, data engineering, and DevOps (Development and Operations) methodologies to streamline the end-to-end lifecycle of machine learning models. MLOps aims to bridge the gap between data science and IT operations, ensuring that machine learning projects are developed, deployed, monitored, and maintained efficiently and reliably.
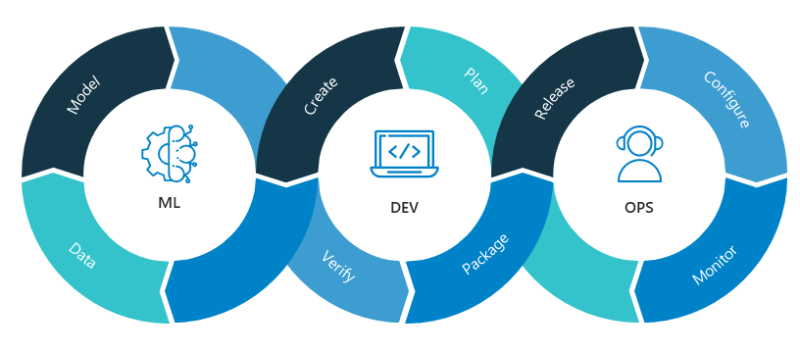
MLOps encompasses a range of activities and practices that focus on collaboration, automation, and the seamless integration of machine learning models into production environments. It addresses the challenges of managing the complete lifecycle of machine learning projects, from data preparation and model training to deployment, monitoring, and ongoing maintenance.
What is DevOps?
DevOps is a set of practices, principles, and cultural philosophies that aim to enhance collaboration and communication between software development (Dev) and IT operations (Ops) teams. The goal of DevOps is to streamline and automate the traditional software development and deployment process, leading to faster delivery of high-quality software and improved efficiency in managing IT infrastructure. DevOps bridges the gap between development and operations, promoting a culture of collaboration, continuous improvement, and automation.

Here, we can see both behavior is nearly the same, but there are some bold difference too. MLOps is used for the machine learning model and DevOps for traditional software are used.
Now let’s see the difference between ML models and traditional software.
Machine learning (ML) models and traditional software have distinct differences due to their nature and purposes. Here are some key bold differences between ML models and traditional software:
Logic and Rule-based vs. Data-driven Decision Making:
ML Models:
ML models learn patterns and relationships from data to make predictions or decisions. They make predictions based on patterns learned from historical data rather than following explicit rules or logic.
Traditional Software:
Traditional software follows predetermined logic and rules programmed by developers to execute specific tasks.
Adaptability:
ML Models:
ML models can adapt and improve over time as they’re exposed to more data. They have the potential to generalize to new, unseen examples.
Traditional Software:
Traditional software behavior remains constant unless manually updated by developers.
Generalization:
ML Models:
ML models generalize patterns from training data to make predictions on new, similar data points.
Traditional Software:
Traditional software executes predefined logic for specific input scenarios.
Dynamic Decision Making:
ML Models:
ML models can dynamically adjust their decisions based on new input data, leading to personalized and context-aware predictions.
Traditional Software:
Traditional software provides fixed outputs based on predefined conditions.
Uncertainty and Confidence:
ML Models:
ML models often provide predictions along with uncertainty estimates or confidence scores, indicating their level of confidence in the prediction.
Traditional Software:
Traditional software doesn’t inherently provide uncertainty estimates for its outputs.
Interpretability:
ML Models:
ML models can be complex and challenging to interpret, especially deep learning models. Understanding their decision-making process might be difficult.
Traditional Software:
Traditional software’s decision-making logic is usually easier to understand and trace.
Development Process:
ML Models:
Developing ML models involves data collection, preprocessing, feature engineering, model selection, training, and evaluation. It’s an iterative process involving data scientists and machine learning engineers.
Traditional Software:
Developing traditional software involves writing code based on specified requirements and logic. It’s typically done by software developers.
Deployment:
ML Models:
Deploying ML models involves considerations like data preprocessing, model versioning, containerization, and integration into production systems.
Traditional Software:
Deploying traditional software involves compiling and packaging the code, and it can be done using various deployment mechanisms.
Feedback Loop:
ML Models:
ML models can receive feedback and updates based on real-world performance, leading to model improvements over time.
Traditional Software:
Feedback might lead to software updates, but it’s not inherently tied to data-driven performance improvements.
Change Management:
ML Models:
Changes to ML models often involve retraining with new data and potentially revalidating the model’s performance.
Traditional Software:
Changes to traditional software involve updating the code and testing the new version.
Continuous Learning:
ML Models:
ML models can be designed to learn and improve from new data automatically, without manual code updates.
Traditional Software:
Traditional software doesn’t inherently learn or adapt without manual intervention.
ML models leverage data to make predictions, while traditional software relies on predetermined logic to execute tasks. MLOps practices combine both approaches to streamline the development, deployment, and maintenance of ML models in production environments
Traditional Software Example:
Online E-commerce Website
- Imagine you are developing an online e-commerce website. This is a classic example of traditional software development:
- Functionality: The website allows users to browse products, add items to their cart, proceed to checkout, and make purchases.
- Logic: The software contains logic to manage user authentication, handle cart updates, calculate prices, and process payment transactions.
- Development: Developers write code in programming languages like HTML, CSS, and JavaScript to create the user interface and implement the business logic.
- Testing: The software undergoes testing to ensure that all functionalities work as expected, including handling edge cases and errors.
- Deployment: The website is deployed to web servers, and users can access it through their browsers.
- Maintenance: Regular updates and bug fixes are released to enhance user experience and security.
Machine Learning Model Example: Spam Email Classifier
- Now, let’s consider a simple example of a machine-learning model:
- Problem: You want to develop a spam email classifier that can automatically identify whether an incoming email is spam or not.
- Data: You collect a labeled dataset of emails, where each email is labeled as either “spam” or “not spam.”
- Feature Extraction: You preprocess the emails, extracting features such as word frequency, presence of specific keywords, and email structure.
- Model Selection: You choose a machine learning algorithm, such as a Naive Bayes classifier, and train it on the labeled dataset.
- Training: The algorithm learns patterns from the labeled data to distinguish between spam and non-spam emails.
- Testing: You evaluate the trained model’s performance using a separate test dataset to measure its accuracy and other metrics.
- Deployment: The trained model is integrated into an email system. New incoming emails are passed through the model to predict whether they are spam or not.
- Monitoring and Retraining: Over time, the model might encounter new types of spam emails. Regular monitoring and periodic retraining ensure that the model remains accurate.
Now let’s see how DevOps fails in the case of ML models:
DevOps practices can face challenges when applied to machine learning (ML) models due to the unique characteristics of ML development. Here are some reasons why DevOps might face difficulties or fail in the context of ML models:
Data Complexity and Variability:
- Challenge: ML models heavily depend on data quality and availability. Data can be messy, inconsistent, and subject to change, making it harder to maintain a stable and consistent pipeline.
- Example: Imagine a sentiment analysis model for social media posts. The language used in social media is informal, with various abbreviations and misspellings. Handling such data complexities requires careful preprocessing and cleaning to ensure accurate predictions.
- Impact: If data issues are not adequately addressed in the DevOps process, it can lead to models that are unstable, unpredictable, or prone to errors.
Model Drift and Concept Drift:
- Challenge: ML models can experience concept drift (changes in data distribution) or model drift (changes in model behavior over time). Traditional DevOps pipelines may not account for these dynamic changes.
- Example: An e-commerce recommendation system trained on historical purchase data might face concept drift during holiday seasons when buying patterns change. If not addressed, it could recommend irrelevant products.
- Impact: DevOps pipelines that lack mechanisms to detect and handle drift can lead to inaccurate predictions and unexpected behavior in production.
Retraining Complexity:
- Challenge: Retraining ML models can be resource-intensive and time-consuming. Incorporating frequent retraining into DevOps pipelines might strain resources and slow down deployment.
- Example: Consider a fraud detection model in the banking sector. Frequent retraining is essential to keep up with evolving fraud patterns, but the process requires significant computational power and expertise.
- Impact: Without efficient retraining strategies, models may become outdated and less accurate over time, undermining their value in production.
Lack of Standardization:
- Challenge: ML development often involves a wide array of tools, libraries, and frameworks. Achieving standardization across different ML models and teams can be challenging.
- Example: In an organization, different data science teams use different libraries for model development. Lack of standardization makes it difficult to manage models consistently across the organization.
- Impact: Lack of standardization can lead to inconsistency in development, and deployment practices, and difficulties in integrating ML models into automated pipelines.
Model Interpretability:
- Challenge: ML models, especially complex ones like deep learning, might lack interpretability. DevOps practices often require transparent and understandable processes.
- Example: A deep learning model for medical image analysis can accurately diagnose diseases but might not provide insights into why a particular diagnosis was made, hindering trust and medical validation.
- Impact: Difficulty in explaining model decisions can hinder troubleshooting, debugging, and gaining stakeholder trust.
Unpredictable Model Behavior:
- Challenge: ML models might behave unexpectedly due to the inherent complexity of learning from data. This unpredictability can disrupt DevOps processes.
- Example: An autonomous vehicle’s object detection model might perform well in most scenarios but behave unpredictably when encountering rare or novel objects, leading to safety concerns.
- Impact: Unpredictable behavior can lead to sudden changes in production environments, causing operational challenges and affecting user experiences.
Cultural Misalignment:
- Challenge: Traditional DevOps emphasizes collaboration between development and operations teams. In ML projects, data scientists, engineers, and domain experts also need to collaborate effectively.
- Example: In a healthcare organization, data scientists and medical experts need to collaborate closely to develop accurate diagnostic models. Misalignment can lead to models that don’t meet medical standards.
- Impact: Without proper collaboration and alignment of roles, the deployment of ML models might not meet business objectives or technical requirements.
Model Governance and Compliance:
- Challenge: ML models often deal with sensitive data and regulatory concerns. DevOps practices may not inherently address model governance and compliance requirements.
- Example: A credit scoring model that uses personal financial data must comply with data protection regulations. DevOps processes should ensure data privacy and compliance.
- Impact: Failure to comply with regulations can result in legal and reputational risks for organizations.
Automation Challenges:
- Challenge: Automating ML pipelines involves complexities beyond traditional software automation. Data preprocessing, feature engineering, and model training require specialized approaches.
- Example: Building a natural language processing pipeline involves tokenization, word embedding, and model training. Automating these steps requires domain-specific knowledge.
- Impact: Inadequate automation can result in manual errors, inconsistency, and delays in deploying ML models.
Lack of Monitoring for Data and Model Performance:
- Challenge: ML models require continuous monitoring not only for infrastructure but also for data quality and model performance.
- Example: A weather forecasting model needs to monitor the accuracy of its predictions against actual weather conditions. Ignoring monitoring can lead to inaccurate forecasts.
- Impact: Failing to monitor data and model performance can lead to suboptimal predictions and missed opportunities for improvement.
How MlOps comes to light:
MLOps emerged in response to the challenges faced by organizations in deploying, managing, and maintaining machine learning (ML) models in production environments. As ML adoption increased, it became evident that traditional software development practices were not fully suitable for the unique characteristics of ML projects. Here’s how MLOps came into the spotlight:
Rise of Machine Learning:
- The advancements in ML algorithms and technologies led to the integration of predictive and analytical capabilities into various applications and industries. ML became a critical component of business strategies. Transforming the way businesses make decisions and automate processes.
- Example: In the healthcare sector, machine learning models can analyze medical images to detect diseases. This technology revolutionizes diagnosis by providing accurate insights that assist doctors in making informed decisions.
Challenges with Model Deployment:
- Organizations found that developing ML models was only one part of the equation. Deploying models into production environments posed challenges due to data variability, model drift, and the need for continuous improvement.
- Example: A recommendation system deployed in an e-commerce platform might start recommending irrelevant products after a while due to changing customer preferences. This concept drift needs to be addressed to maintain the quality of recommendations.
Data Complexity and Versioning:
- ML models are highly dependent on data quality and versioning. Traditional software development practices didn’t account for data preprocessing, versioning, and management, leading to inconsistencies and errors.
- Example: An autonomous vehicle’s object detection model must be trained on a diverse dataset that represents various weather conditions, lighting, and scenarios. Proper preprocessing ensures the model generalizes well in real-world conditions.
Model Maintenance and Monitoring:
- ML models degrade over time due to changing data distributions. Continuous monitoring, retraining, and updates were necessary to maintain model accuracy and relevance.
- Example: A spam email classifier trained on historical data will encounter new types of spam emails over time. Regular monitoring and retraining are required to adapt to new spam patterns.
Interdisciplinary Collaboration:
- ML projects involve collaboration between data scientists, engineers, domain experts, and operations teams. Traditional silos between these roles created communication and alignment challenges.
- Example: Developing a personalized health app involves collaboration between medical experts, data scientists, and app developers to ensure accurate health recommendations are provided to users.
Automation for Reproducibility:
- Automation is essential in both software development and ML. However, the automation needs in ML, such as data preprocessing and model training, require specialized tools and workflows.
- Example: Automating the process of training a natural language processing model involves tokenizing text data, creating word embeddings, training the model, and evaluating its accuracy—all without manual intervention.
Need for Scalability:
- As organizations aimed to deploy multiple models across various applications, scalability, and resource allocation became critical considerations to ensure models perform well under increased workloads.
- Example: A financial institution may deploy fraud detection models across multiple branches and transactions. Scalability ensures that the models can handle the volume of transactions without performance degradation.
Business Impact of ML Models:
- ML models often make critical decisions with significant business impact, such as credit scoring or medical diagnoses. The reliability and transparency of these decisions became crucial.
- Example: A credit scoring model used by a bank to assess loan applications needs to provide accurate predictions. Incorrect predictions could result in financial losses for the bank and unfair treatment of applicants.
Emergence of DevOps Practices:
- DevOps practices have already shown success in accelerating software development, deployment, and operations. Adapting these practices to the ML context seemed like a natural progression.
- Example: Just as DevOps automates software deployment, MLOps automates the deployment and monitoring of machine learning models, ensuring consistent and reliable performance.
Holistic Approach to ML Lifecycle:
- Organizations realized that a holistic approach, encompassing data preparation, model development, deployment, monitoring, and retraining, was needed to address the challenges posed by ML projects.
- Example: Developing an autonomous drone for package delivery involves a complete lifecycle—from training the model to navigate obstacles to continuous monitoring and updating based on real-world experiences.
MLOps, came into the light as a natural evolution of DevOps practices to address the specific needs of machine learning projects. It focused on bridging the gap between data science, engineering, and operations teams, promoting collaboration, automation, and continuous improvement. MLOps provided a framework to manage the end-to-end lifecycle of ML models and enabled organizations to reap the benefits of ML while mitigating risks and challenges associated with model deployment and maintenance.
The reason why MlOps instead of DevOps:
MLOps (Machine Learning Operations) and DevOps (Development Operations) are both practices that aim to streamline and improve the software development and deployment process, but they have different focuses and objectives.
DevOps primarily focuses on integrating and automating the processes between software development (Dev) and IT operations (Ops). The goal is to shorten the development lifecycle, increase the frequency of software releases, and improve the quality of software. DevOps practices involve continuous integration, continuous delivery (CI/CD), infrastructure automation, and collaboration between development and operations teams.
MLOps, on the other hand, is an extension of DevOps tailored specifically for machine learning and data science projects. It incorporates DevOps principles and practices but also addresses the unique challenges posed by deploying and managing machine learning models. These challenges include versioning and tracking of models and data, managing model drift, retraining and updating models, monitoring model performance, and ensuring reproducibility in a data-driven context.
Here are some reasons why MLOps is emphasized for machine learning projects instead of relying solely on DevOps:
Data-Centric Nature:
Machine learning projects heavily rely on data. Proper handling, versioning, and management of data are crucial. MLOps provides tools and practices to ensure that the right data is used for model training and deployment.
In a credit risk prediction project, where a machine learning model is developed to assess the creditworthiness of applicants, proper data handling is crucial. MLOps involves creating a data pipeline that collects, cleans, and preprocesses the data. Tools like Apache Airflow can schedule and automate these data transformations. Data versioning ensures that the same dataset is used consistently for both training and deployment, preventing discrepancies that might arise from using different data sources.
Model Management:
Machine learning models are not static; they evolve. MLOps addresses the challenges of versioning models, managing different versions in production, and handling model updates seamlessly.
Consider a recommendation system for an e-commerce platform. As user preferences change and new products are added, the recommendation model needs to evolve. MLOps provides version control for models, enabling teams to track changes, compare performances, and deploy newer versions seamlessly. Docker containers can be used to package models, ensuring consistent behavior across different environments.
Monitoring and Maintenance:
Monitoring the performance of a machine learning model in production is vital. MLOps focuses on continuous monitoring, detecting model degradation, and triggering retraining or updates when necessary.
Imagine a chatbot that assists customers. The natural language processing model it uses can experience performance degradation over time due to changes in user behavior and language trends. MLOps involves setting up monitoring pipelines that track metrics like response time and accuracy. If accuracy drops below a certain threshold, the system can automatically trigger a retraining process to improve performance.
Reproducibility:
Reproducing and replicating machine learning experiments is essential for scientific integrity. MLOps ensures that the entire pipeline, from data preprocessing to model training, is well-documented and reproducible.
In a medical imaging project, a deep learning model is developed to detect anomalies in X-ray images. MLOps ensures reproducibility by maintaining a detailed record of the entire pipeline. This includes the specific preprocessing steps, hyperparameters, and training data used. By following the same pipeline, researchers can replicate experiments and verify results.
Compliance and Governance:
MLOps takes into account regulatory and compliance concerns related to handling sensitive data and making predictions that impact critical decisions.
Consider a financial institution building a fraud detection model. MLOps addresses compliance by implementing access controls and encryption mechanisms to protect sensitive customer data. Additionally, audit trails are maintained to demonstrate how the model arrived at its predictions, ensuring transparency and accountability.
Cross-Functional Collaboration:
MLOps encourages collaboration between data scientists, machine learning engineers, developers, and operations teams, ensuring that everyone is aligned and working towards the same goals.
In a self-driving car project, various teams work together. Data scientists collect driving data, machine learning engineers develop models, developers integrate them into the car’s software, and operations teams ensure safe deployment. MLOps tools like Kubernetes facilitate collaboration by enabling easy deployment and management of models, while documentation and versioning ensure everyone understands the model’s behavior.
DevOps provides a foundation for efficient software development and deployment, and MLOps extends these principles to address the specific challenges of machine learning projects. MLOps is particularly relevant for managing the end-to-end lifecycle of machine learning models, ensuring their reliability, performance, and continuous improvement in production environments
Tools used in MlOps:
Git:

Git is a distributed version control system widely used in software development to track changes in source code and manage collaboration among developers. It was created by Linus Torvalds in 2005 and has become one of the most popular tools in the development industry.
Version control is a systematic approach to managing changes to files and projects over time. It allows you to track the history of modifications, collaborate with others, and revert to previous versions if needed. Version control systems (VCS) help keep track of every change made to files, providing a chronological record of who made the changes, what changes were made, and when they were made.
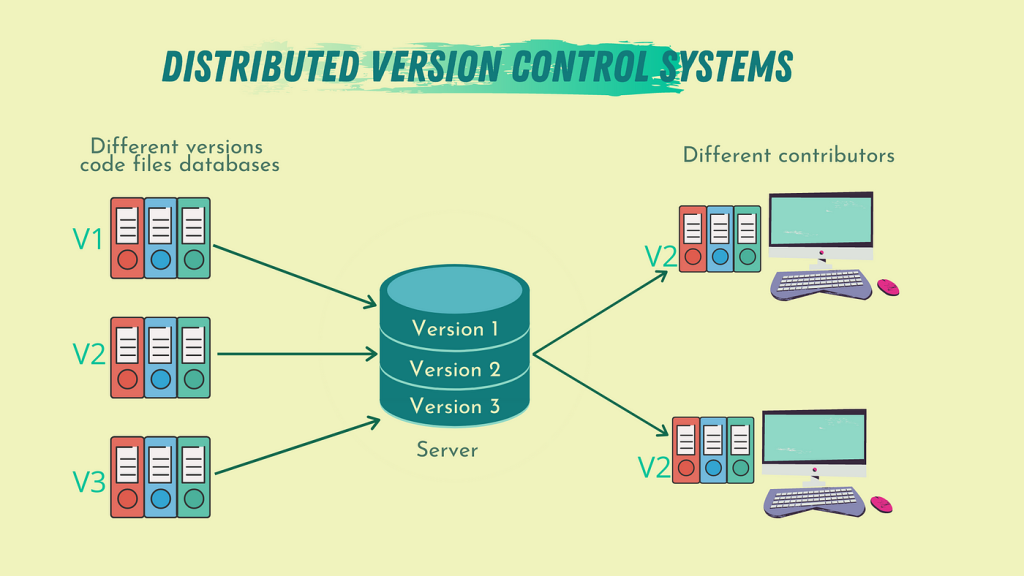
- Version control is highly valuable in various contexts, including software development, data science, and machine learning. General Use and Benefits are as follows:
- History Tracking: Version control systems maintain a complete history of changes made to files and projects. This history is useful for tracking progress, understanding past decisions, and identifying the origin of issues.
- Collaboration: Multiple people can work on the same project simultaneously without overwriting each other’s work. VCS allows for merging and resolving conflicts, ensuring smooth collaboration.
- Reversion: If a mistake is made or if a feature needs to be rolled back, version control makes it easy to revert to a previous working state.
- Branching and Merging: Version control systems support creating branches, which are separate lines of development. This allows for experimenting with new features or fixes without affecting the main project. Merging branches back into the main project is facilitated by the VCS.
- Documentation and Communication: The commit history in version control serves as a form of documentation, providing insights into the evolution of the project and the rationale behind decisions.
- Backup and Disaster Recovery: Version control systems act as a backup mechanism, protecting against accidental data loss or hardware failures.
Git is extremely useful for managing machine learning (ML) models and projects. Just like in software development, Git helps you track changes, collaborate with team members, and maintain a history of work.
Here’s how Git is beneficial specifically for ML models:
Versioning Data and Code:
Git allows you to track changes to both your machine-learning code and the datasets you use. This is crucial for maintaining a history of changes made during preprocessing, model selection, and evaluation. You can easily revert to previous versions of your code or data if needed.
Experiment Tracking:
ML projects involve numerous experiments with different algorithms, hyperparameters, and data preprocessing steps. With Git, you can create branches for different experiments, enabling you to compare different approaches side by side. Each experiment’s code, data, and results are neatly organized.
Collaboration:
Git facilitates collaboration among team members. Multiple data scientists, machine learning engineers, and domain experts can work on the same project simultaneously. Each person can work on their branch and then merge their changes back into the main codebase.
Code Reviews:
You can use Git to conduct code reviews for machine learning projects. Team members can review each other’s code changes, model implementations, and evaluation methods, ensuring quality and accuracy.
Model Deployment and Monitoring:
Git helps manage the entire lifecycle of a machine learning model, from development to deployment. You can use Git to version control deployment scripts, configuration files, and monitoring scripts. This ensures that the model deployed in production matches the one that was tested and validated.
Handling Large Files:
Machine learning projects often involve large datasets, model checkpoints, and trained weights. Git’s support for Large File Storage (LFS) allows you to manage and version control these large files efficiently without bloating your repository.
Documentation:
Git encourages good documentation practices. Each commit message can provide a summary of the changes made, and you can use README files to document the project’s structure, data sources, preprocessing steps, and model details.
Reproducibility:
Git’s ability to track changes to code, data, and configuration files makes it easier to reproduce experiments. By sharing the entire codebase and history, other researchers can replicate your work precisely.
Model Monitoring and Updates:
As ML models are deployed in production, they might require updates due to changing data distributions or business requirements. Git allows you to track and manage these updates systematically. Git provides version control, collaboration, and organization benefits that are highly valuable for machine learning projects. It helps data scientists and engineers work together effectively, maintain the integrity of models, and enable transparent and reproducible research.
Git-Hub:

- GitHub is a web-based platform that provides hosting for software development projects. It uses the Git version control system to enable collaborative development, code sharing, and project management. GitHub is widely used by individual developers, open-source communities, and organizations to collaborate on code, track changes, and manage software projects.
- Experiment Tracking: With GitHub, you can create branches or repositories for different machine learning experiments. This makes it easy to compare results, share findings, and replicate experiments.
- Collaboration: Teams working on machine learning projects can collaborate effectively on GitHub. Different team members can work on different branches, and pull requests allow for code review and collaboration before merging changes.
- Model Sharing: GitHub makes it simple to share your machine-learning models and projects with others. Anyone with access to your repository can clone it and explore your work.
GitHub for MLOps:
CI/CD Pipelines:
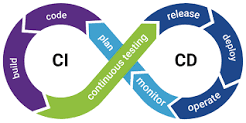
GitHub integrates seamlessly with various CI/CD tools. This enables you to automate testing, building, and deployment processes for your machine-learning models.
CI/CD stands for Continuous Integration and Continuous Deployment (or Continuous Delivery). It is a set of practices and processes in software development that aim to automate and streamline the building, testing, and deployment of applications. CI/CD pipelines help ensure the consistent and reliable delivery of code changes to production environments, improving efficiency, quality, and collaboration among development teams.
- Continuous Integration (CI):
- CI involves the practice of frequently integrating code changes from multiple contributors into a shared repository. Each code change triggers an automated build and test process to identify integration issues early in the development cycle. The main goals of CI are to catch defects early, improve collaboration, and ensure that the codebase remains in a functional state.
- Continuous Deployment (CD):
- CD extends CI by automatically deploying code changes to production or staging environments after successful testing. This practice reduces manual intervention and ensures that new features, bug fixes, and improvements are delivered to users quickly and frequently.
- Continuous Delivery (CD):
- Continuous Delivery is closely related to Continuous Deployment. While CD includes the practice of automatically deploying changes to production, Continuous Delivery focuses on having a codebase that is always in a deployable state, allowing teams to choose when to release changes.
- Benefits of CI/CD:
- Faster Feedback: Automated testing and deployment provide rapid feedback on the quality of code changes, allowing developers to catch issues early and address them before they reach production.
- Reduced Manual Work: CI/CD pipelines automate time-consuming and error-prone tasks, such as building, testing, and deployment. This frees up developers to focus on coding and innovation.
- Consistency: CI/CD pipelines ensure that every code change goes through the same standardized process, reducing the likelihood of human errors and ensuring consistent quality.
Improved Collaboration:
CI/CD encourages collaboration among team members by providing a common and transparent process for integrating, testing, and deploying code changes.
Rapid Releases:
CI/CD enables frequent releases of new features and bug fixes, allowing organizations to respond quickly to user feedback and market demands.
Reduced Deployment Risk:
Automated testing helps identify issues early, reducing the risk of deploying faulty code to production environments.
Scalability:
CI/CD pipelines can handle large-scale development by automating repetitive tasks, making it feasible to manage complex projects and frequent code changes.
Deployment Scripts and Configurations:
GitHub hosts deployment scripts and configuration files for deploying machine learning models in production. This includes Dockerfiles, Kubernetes configurations, and other deployment-related assets.
Model Monitoring and Drift Detection:
GitHub can host scripts and code related to monitoring the performance of deployed models and detecting model drift. This helps ensure that models in production remain accurate and effective.
Collaborative MLOps Workflows:
Teams working on MLOps projects can collaborate on GitHub, ensuring that everyone is aligned on changes, updates, and improvements to the end-to-end pipeline.
Documentation:
GitHub’s README files and documentation capabilities allow you to document your MLOps processes, best practices, and project setup for easy sharing and onboarding.
In both machine learning and MLOps contexts, GitHub provides collaboration, and documentation capabilities that enhance transparency, efficiency, and reproducibility in development and deployment processes.
Docker:

Docker is a platform that enables you to develop, deploy, and run applications in containers. Containers are lightweight, isolated environments that package an application and its dependencies, ensuring consistency across different environments, from development to production. Docker provides a way to package, distribute, and manage applications and their dependencies as a single unit, making it easier to build, ship, and run software across different systems.
Docker is an essential tool in MLOps (Machine Learning Operations) for creating reproducible and consistent environments, enabling efficient deployment, monitoring, and management of machine learning models. Here’s how Docker can be applied in the context of MLOps:
Environment Consistency:
In MLOps, maintaining consistent environments across different stages of the machine learning lifecycle is crucial. Docker allows you to package not only the model code but also the entire environment, including libraries, dependencies, and configurations, into containers. This consistency ensures that what you develop and test matches what is deployed in production.
Reproducibility:
Docker containers encapsulate the complete environment needed to run your machine learning pipeline, including data preprocessing, feature engineering, model training, and evaluation. By sharing the Docker image and code, you ensure that experiments are reproducible across different environments.
Model Deployment:
Docker containers are an effective way to package and deploy machine learning models. You can create containers that serve your trained models as APIs, making it easy to integrate them into applications and services. This approach ensures that the deployed models are isolated and self-contained.
Scalability:
Docker’s containerization enables easy scalability of machine learning applications. You can scale up or down based on demand, allowing you to handle varying workloads and ensuring responsiveness.
Model Monitoring and Drift Detection:
Monitoring the performance of deployed machine learning models is a key aspect of MLOps. Docker containers can host monitoring scripts that track model performance metrics and detect drift. If model drift is detected, the containerized pipeline can trigger retraining or alert notifications.
Infrastructure as Code:
Docker containers can be part of your infrastructure as a coding strategy in MLOps. The Docker image creation process can be defined in code (Docker files), ensuring that deployment and scaling processes are repeatable and automated.
CI/CD Pipelines:
Docker containers integrate seamlessly into CI/CD pipelines for machine learning projects. You can automate the building, testing, and deployment of Docker images, ensuring consistent and reliable deployment of models.
Collaboration:
Docker simplifies collaboration among data scientists, machine learning engineers, developers, and operations teams in MLOps workflows. Everyone can work in a consistent environment and contribute to the pipeline seamlessly.
Rollbacks and Recovery:
Docker containers make it easy to roll back to previous versions of your machine-learning pipeline. In case of issues or unexpected behavior, you can revert to a known working state.
Hybrid and Multi-Cloud Deployments:
Docker enables consistent deployments across different cloud providers and on-premises environments. This flexibility is valuable in MLOps scenarios where you might need to deploy models across various platforms.
Docker is a powerful tool in MLOps, offering benefits like consistency, reproducibility, scalability, deployment efficiency, and collaboration. It enhances the management and automation of the machine learning lifecycle, from development to deployment and monitoring.
Kubernetes:
Kubernetes (often abbreviated as “K8s”) is an open-source container orchestration platform that automates the deployment, scaling, and management of containerized applications. It was originally developed by Google and is now maintained by the Cloud Native Computing Foundation (CNCF). Kubernetes provides a powerful toolset for managing the complex task of deploying and managing containerized applications in dynamic and scalable environments.
Kubernetes is highly beneficial for managing machine learning (ML) models and implementing MLOps (Machine Learning Operations) practices. It provides a powerful platform for deploying, monitoring, scaling, and managing ML models and pipelines efficiently and reliably. Here’s how Kubernetes enhances ML models and MLOps:
For ML Models:
Containerized ML Workloads:
Kubernetes allows you to containerize your ML models and their dependencies using Docker containers. This ensures that your models are isolated, consistent, and easily deployable across different environments.
Scalability:
Kubernetes supports automatic horizontal scaling of pods (containers). This is essential for handling varying workloads in ML applications, especially when dealing with multiple concurrent inference requests.
Resource Management:
Kubernetes helps manage the allocation of resources (CPU, memory) to ML model containers. This ensures that models receive the required resources for efficient performance and prevents resource contention.
High Availability:
Kubernetes manages the deployment of replicas, ensuring that your ML models are highly available and capable of handling failures.
Rolling Updates:
Kubernetes allows for controlled rollouts of new versions of ML models. This ensures zero downtime updates and easy rollback in case issues are detected.
Secrets and Configurations:
Kubernetes provides mechanisms like Secrets and ConfigMaps for managing sensitive information and configuration data separately from your model code.
Service Discovery and Load Balancing:
Kubernetes abstracts networking, providing service discovery and load balancing for your ML model deployments. This is crucial for routing requests to the appropriate model instance.
Ingress Controllers:
Kubernetes supports ingress controllers for managing external access to your ML model services, enabling secure and controlled API access.
Custom Metrics:
Kubernetes can be extended to handle custom metrics, which is valuable for ML models where monitoring specific metrics like prediction latency or accuracy is essential.
For MLOps:
Consistent Environments:
Kubernetes ensures that the same environment used for development and testing is also used in production. This consistency reduces the “it works on my machine” problem.
CI/CD Pipelines:
Kubernetes integrates seamlessly with CI/CD tools, allowing for automated testing, building, and deployment of ML models. This supports a continuous delivery workflow.
Model Deployment:
Kubernetes simplifies the deployment of ML models as APIs. You can serve your models using containers, making it easy to integrate them into applications and services.
Model Monitoring:
Kubernetes supports monitoring tools and solutions that help track model performance, detect drift, and trigger retraining as needed.
Infrastructure as Code:
Kubernetes manifests (YAML files) define your deployments and services as code, enabling consistent and repeatable infrastructure setups.
GitOps:
Kubernetes can be integrated with GitOps practices, where infrastructure and deployment configurations are version-controlled in Git repositories.
Multi-Environment Support:
Kubernetes abstracts the differences between environments, making it easier to deploy and manage models across different cloud providers or on-premises setups.
Collaboration:
Kubernetes fosters collaboration by providing a consistent environment for development, testing, and deployment, enabling teams to work together effectively.
Kubernetes enhances ML models and MLOps practices by providing orchestration, scaling, monitoring, and management capabilities. It promotes consistency, scalability, and automation in deploying and managing ML models throughout their lifecycle.
Kubernetes and Docker work together to provide a comprehensive solution for deploying, managing, and scaling containerized applications. While Docker focuses on creating and packaging containers, Kubernetes takes care of orchestrating and managing those containers in a dynamic and scalable manner. Here’s how Kubernetes enhances the utility of Docker:
Orchestration and Scaling:
Kubernetes automates the deployment, scaling, and management of Docker containers across a cluster of machines. It allows you to define desired states for your application, and Kubernetes ensures that the actual state matches the desired state by managing container placement, scaling, and load balancing.
Service Discovery and Load Balancing:
Kubernetes provides services that abstract the network connections between sets of pods. This simplifies the process of service discovery and load balancing for your containerized applications. It ensures that traffic is distributed evenly among healthy pods.
High Availability:
Kubernetes supports replicating and scaling your Docker containers to ensure high availability. If a container or node fails, Kubernetes automatically reschedules or replaces the containers to maintain the desired state.
Rolling Updates and Rollbacks:
Kubernetes facilitates controlled rollouts and rollbacks of updates to your Docker containers. This ensures that updates are introduced gradually and can be reverted if issues arise.
Configuration Management:
Kubernetes supports the separation of configuration data from application code. ConfigMaps and Secrets allow you to manage configuration data and sensitive information independently of your Docker container images.
Efficient Resource Utilization:
Kubernetes monitors the resource utilization of your Docker containers and automatically adjusts the number of replicas based on resource requirements. This ensures efficient resource utilization while accommodating varying workloads.
Cluster Management:
Kubernetes handles the management of a cluster of machines, including node health, placement of containers, and node autoscaling. This abstraction allows developers to focus on their applications rather than the underlying infrastructure.
Multi-Environment Support:
Kubernetes abstracts away the differences between various environments, whether it’s on-premises hardware or different cloud providers. This allows you to deploy your Docker containers consistently across different environments.
Extensibility:
Kubernetes is extensible through its API and supports custom resources and controllers. This extensibility allows you to tailor Kubernetes to your specific use cases and integrate it with other tools and services.
Management of Stateful Applications:
While Docker containers are often stateless, Kubernetes offers StatefulSets to manage stateful applications, such as databases, with unique and stable identities.
Kubernetes complements Docker by providing a higher-level orchestration and management layer for containerized applications. It addresses challenges related to scalability, availability, configuration management, and dynamic orchestration, allowing you to efficiently deploy and manage Docker containers at scale.
Cloud Platform:

Cloud platforms play a crucial role in enabling and supporting the implementation of MLOps (Machine Learning Operations). MLOps is the practice of bringing together machine learning, data engineering, and DevOps principles to streamline the end-to-end lifecycle of machine learning models. Here’s how cloud platforms contribute to MLOps:
Scalable Infrastructure:
Cloud platforms offer scalable infrastructure that can be provisioned and configured on demand. This is essential for accommodating the resource-intensive tasks involved in training and deploying machine learning models.
Containerization and Orchestration:
Cloud platforms support containerization technologies like Docker and orchestration tools like Kubernetes. Containers enable consistent environments, and orchestration simplifies the management of complex multi-container applications.
Automation and CI/CD:
Cloud platforms provide tools and services for automating processes, including continuous integration and continuous deployment (CI/CD) pipelines. These tools help automate the testing, building, and deployment of ML models and pipelines.
Managed Services:
Cloud providers offer managed services specifically designed for MLOps. These services handle various aspects of the ML lifecycle, such as model training, deployment, monitoring, and management.
Data Storage and Management:
Cloud platforms offer various data storage solutions, including data lakes, databases, and data warehouses. These solutions support the storage and management of the data used for training and evaluation.
Collaboration and Version Control:
Cloud platforms provide collaboration tools, including version control and project management, which are crucial for coordinating efforts between data scientists, machine learning engineers, and operations teams.
Machine Learning Services:
Cloud providers offer machine learning services that simplify model training and deployment. These services abstract away much of the complexity of infrastructure setup, allowing teams to focus on model development.
Resource Management:
Cloud platforms offer tools for resource monitoring, allocation, and management. This is important for optimizing resource usage and controlling costs.
Security and Compliance:
Cloud providers offer security features to safeguard ML models and data. They also provide compliance certifications and tools to help organizations adhere to regulatory requirements.
Monitoring and Alerting:
Cloud platforms provide monitoring and logging services that allow you to track the performance of deployed models, detect anomalies, and set up alerts for potential issues.
Geographical Distribution:
Cloud providers have a global data center presence, enabling you to deploy models closer to your target audience for improved latency and user experience.
Experiment Tracking:
Cloud platforms offer tools for tracking machine learning experiments, allowing teams to document changes, compare results, and reproduce experiments.
Machine Learning Pipelines:
Cloud platforms support building and managing end-to-end machine learning pipelines, which include data preprocessing, feature engineering, model training, and deployment.
- Key components of a machine learning pipeline typically include:
- Data Collection: Gathering raw data from various sources, such as databases, APIs, files, or sensors.
- Data Preprocessing: Cleaning, transforming, and preparing the data for modeling. This involves handling missing values, scaling features, encoding categorical variables, and more.
- Feature Engineering: Creating new features from the existing data or transforming existing features to improve the model’s predictive power.
- Model Selection: Choosing the appropriate machine learning algorithm or model architecture for the task at hand.
- Model Training: Training the selected model using the preprocessed data.
- Model Evaluation: Assessing the performance of the trained model using evaluation metrics and validation techniques.
- Hyperparameter Tuning: Fine-tuning the model’s hyperparameters to optimize its performance.
- Model Deployment: Deploying the trained model in production to make predictions on new, unseen data.
- Monitoring and Maintenance: Continuously monitoring the model’s performance in production, detecting drift, and updating the model as needed.
- The creation, setup, and management of a machine learning pipeline involve multiple roles and responsibilities within a data-driven organization:
- Data Scientists: Data scientists design and develop the machine learning pipeline, from data preprocessing and feature engineering to model selection and tuning. They ensure that the pipeline is efficient, accurate, and aligned with the business objectives.
- Machine Learning Engineers: These professionals focus on implementing machine learning models, building scalable and efficient pipelines, and optimizing the model for deployment. They work closely with data scientists to bridge the gap between research and production.
- Data Engineers: Data engineers manage the infrastructure required for data storage, processing, and movement. They ensure that the data flows smoothly through the pipeline and is available for analysis and modeling.
- DevOps Engineers: DevOps engineers are responsible for automating the deployment, monitoring, and scaling of machine learning models in production. They set up the necessary infrastructure and CI/CD pipelines.
- Business Analysts: Business analysts collaborate with data scientists to define the business goals, success criteria, and evaluation metrics for the machine learning pipeline. They help translate technical outcomes into actionable insights for the organization.
- Domain Experts: Domain experts provide subject matter expertise to guide feature engineering, model interpretation, and evaluation. They ensure that the machine learning pipeline reflects the nuances of the specific domain.
- The machine learning pipeline can be set up at different positions within the organization’s workflow:
- Exploratory Data Analysis Phase: The pipeline can start during the exploratory data analysis phase to preprocess and clean data for initial model prototyping.
- Model Development and Testing Phase: The pipeline can encompass model development, hyperparameter tuning, and model evaluation in a controlled environment.
- Production Deployment Phase: The pipeline can extend to production deployment, where models are deployed and managed in real-world scenarios.
- Continuous Monitoring and Updating Phase: The pipeline continues to operate in the monitoring and maintenance phase, ensuring that models remain accurate and relevant over time.
Hybrid and Multi-Cloud Deployment:
Cloud platforms offer options for hybrid and multi-cloud deployments, allowing organizations to leverage the best features of different cloud providers and maintain flexibility. Cloud platforms provide the infrastructure, tools, and services needed to implement MLOps practices effectively. They enable collaboration, automation, scalability, security, and efficient management of machine learning models and pipelines throughout their lifecycle.
Conclusion:
MLOps aims to bridge the gap between DevOps and ML, enabling the efficient and reliable deployment of machine learning models in production environments.