
Introduction
In this blog, we are going to cover, what is Cache and whether caching is really important for an application or not. After that, we will discuss various types of applications where caching is acting as a boon and where it is not necessary. In the end, we will have a demo on how to implement Redis Cache in a Python Flask application.
What is Caching?
Caching is the technique of storing the data in the cache and serving or returning the data at a very fast rate whenever a request is made.
The cache is the storage where the result is stored and is near to the requester so that it can be served at a faster rate.
For example- Suppose you are a student who loves to make notes(or thoughts), for making notes you require a pen/pencil. The right place for a pen/pencil is the pencil box, so every time you want to write a note you are going to find the pencil box and take out the pen/pencil, this can take a time and you might lose the note(thought), so to overcome this what you do is to have that pen/pencil inside your pocket so every time you want to make a note you know you have that pen/pencil inside your pocket, so you can take it out and write without losing much time. In this example, your pocket is acting as a cache, while the pencil box is the permanent storage. This process is known as caching.
Is Caching necessary for all types of Applications?
The answer is No. Caching is not required in all applications, as caching has its own merits and demerits. Let’s first discuss various types of applications.
Let’s divide the applications into 3 different types-
- Big Data Applications(Data Updates in24 hours or more)
- IoT Applications (Data updates every second or more)
- Dynamic Applications (No defined time)
Caching in Big Data Applications
Caching can play a key role in big data applications as the amount of data that is fetched is huge and the data refresh policy is in days. An example of such a type of application is the covid cases tracking application, where data gets updated every 24 hours. and the amount of data is large as almost all of the world data is shown in such type of application. APIs might take more than 10 seconds or more to load the data, to overcome this delay caching can be introduced to reduce the API response time to milliseconds. We can conclude that caching can act as a boon to Big Data or data-driven applications.
Caching in IoT Application
In IoT applications, the data refresh rate is in seconds. So caching will not be a good choice for the API that are showing the real-time data, so it is generally not preferred to implement Cache in IoT Applications, but for the visualization of past datasets or a history of records Cache can be used and it will be a good choice in case of IoT Applications also because IoT devices generate data almost every second so for the history of records using cache will be a great choice.
Caching in Dynamic Applications
With a proper configuration, the cache can be easily used in dynamic applications such as Amazon or Flipkart, by clearing the cache whenever a new item is added or removed or with an update on an existing item. Clearing the cache of a particular item or set with the update of that item will result in no data mismatch, and results can be fruitful.
Different Terminologies in Caching
Purge Strategy– Purge Strategy means the time till which the data will remain in the cache after that it will be flushed automatically. In the pencil box example, we can say that at the end of the day the pen/pencil will go back to the pencil box and will be removed from the pocket, this end of the day will be called the purge time. Purge Strategy plays a key role in caching, as it helps to show the latest data.
Cache Size- Cache size is also very important to choose as the memory is limited up to a certain extent. We need to keep in mind when the cache is full and when not to further cache the data so that no error can occur.
TTL(Time to Live)- TTL is similar to the purge strategy, that is time/duration the data will remain in the cache, TTL plays a key role while planning the strategy around caching, as it helps in data refreshing and cache cleaning.
Cache Hit and Miss– Cache Hit means when the request is served from the cache, while cache miss means that the data is not present in the cache so the main source will be used to serve the request.
Lazy Loading– Lazy loading means that data will retrieve only from the cache until or unless it is not present in the cache, i.e. no cache miss.
Redis Cache and MemCache
These two are the most popular cache techniques getting used. Let’s dive deeper into them and see the merits and demerits of both of them.
Redis comes with a lot of features and advancements while the Memcache is quite simple.
The main differences between the two are-
Memcache is a distributed cache technique, while Redis is not.
Memcache doesn’t support advanced data structures, while Redis does.
Memcache supports multi-threading, while Redis doesn’t.
Replication, Snapshots, and pub-sub are not supported in Memcache, while Redis supports them.
Geospatial and transaction support is not in Memcache while Redis supports them.
We can conclude that Redis is highly rich in features and has that advantage over Memcache.
Caching Architecture
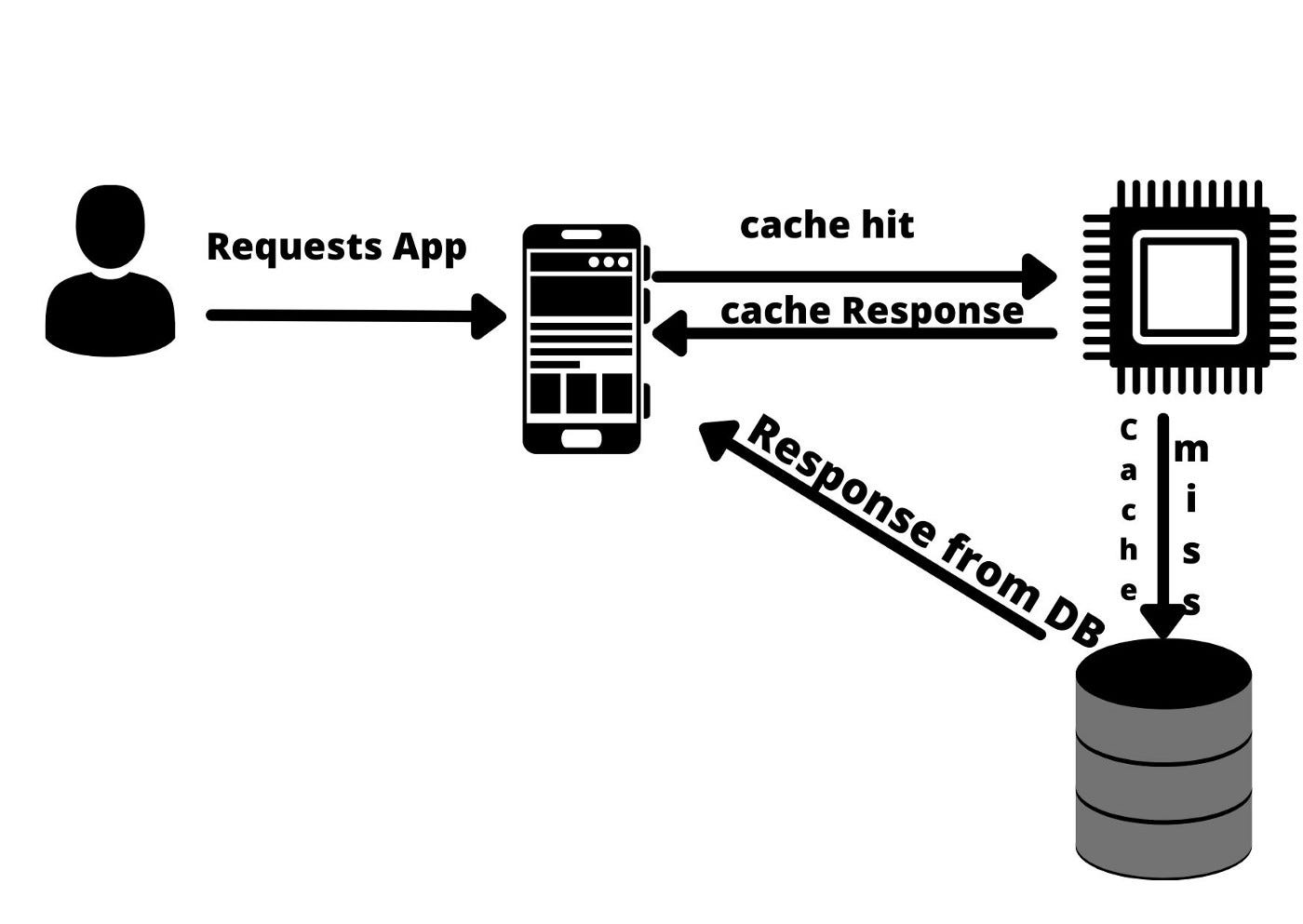
Caching Workflow
Whenever a cache miss will occur a write will happen in the cache so that next it can be served from the cache only.
Demo(Flask Application using Redis Cache)
Let’s first download the Redis on our local system, you can also use Redis cloud or AWS ElatiCache Redis if you want. For this demo, we are going to install the Redis on our local system.
Redis can be downloaded from- https://redis.io/download
After downloading Redis, let’s start the server, we are going to do this using terminal, so open the Redis folder go into src then run redis-server file.
Redis Server started
Once the server is started it will look something like this.
Now we are going to create our python Flask project using Pycharm IDE.
Let’s name our project as CacheDemo.
Create three files in it, one is main.py, the other one is requirements.txt and the last one is config.py
In the main.py file, we are going to create our API.
In the requirements.txt file, we are going to have the dependency required for this project.
In the config.py file, we are going to store our Redis config.
The dependencies for this project are-
- Flask
- Redis
- Requests
- flask_caching
Let’s mention them in the requirements.txt file and install the dependencies by running-
pip install -r requirements.txt

Installing the dependencies
You can also mention a specific version of the package in the requirements.txt file.
Now let’s write the code in our main.py, firstly we will not use the cache and see the response time without it.

Flask code that invokes a covid dataset API
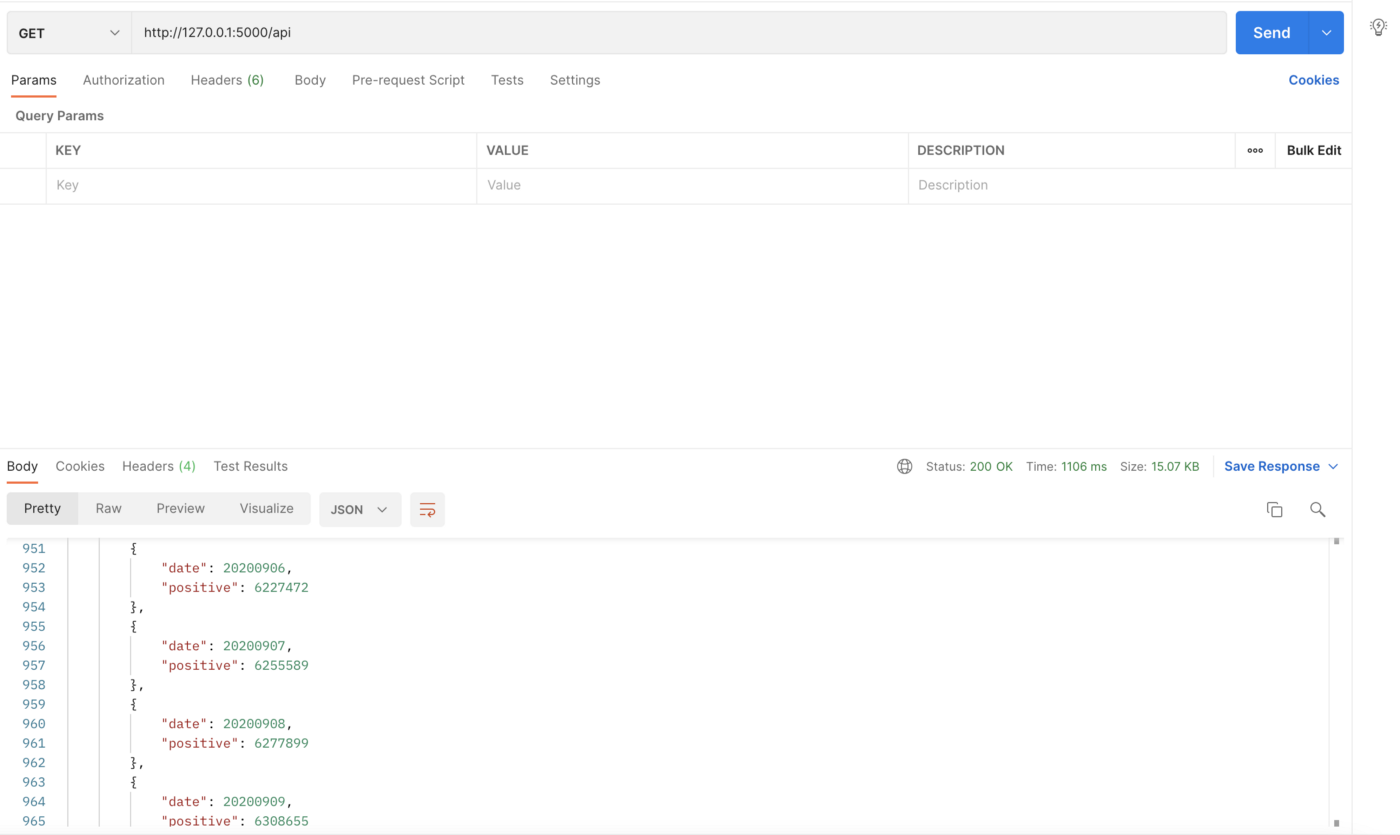
API Invoked through postman
Here we can see that the API is taking around 1 second to invoke, now let’s add our Redis caching code and see how much time it will take after that.
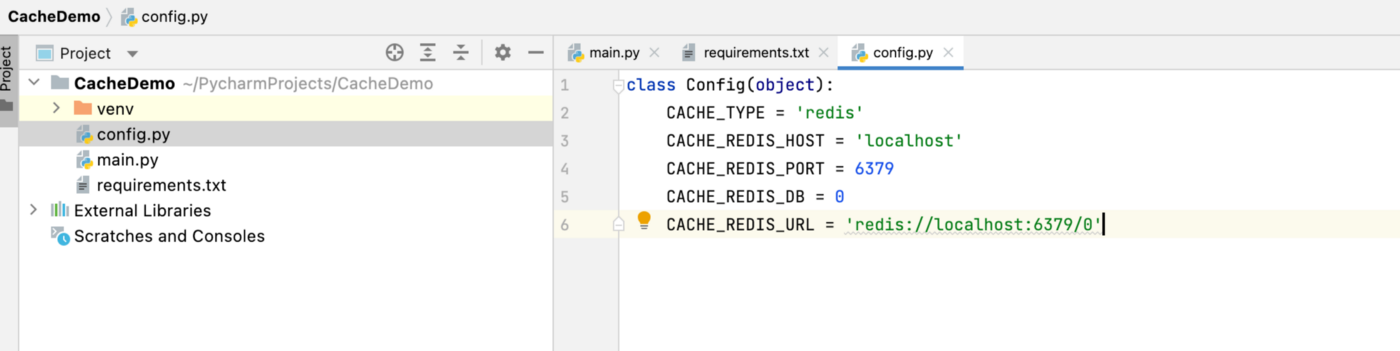
Redis config for localhost

main code with caching implementation
API triggered after implementing cache
The impact can be seen after the first invocation, that is because the first call will be cache miss so the response time will not be affected at the very first call, the impact can be seen after it.
timeout means the TTL time, while query string true means the whole URL will be used as a key, if the same parameters are going to appear in a different order, then also it will be treated as one.
Let’s see the Redis database and cache data there.

Hashed key value
Here we can see the cached key and value of the API.
Conclusion
It’s a wrap-up, for now, we can say that cache plays a very key role in optimizing an application and improving the response time up to a great extent.
For any queries feel free to ping me.
Github link to the code- https://github.com/Utkarsh731/flaskCaching
Still Curious? Visit my website to know more!
For more interesting Blogs Visit- Utkarsh Shukla Author


