
5G is here and set to change our world for the better.
Most people today have heard of 5G, but not everyone understands exactly what it is and the positive impact it could have on businesses and society. Compared to the relatively incremental shift from 3G to 4G, 5G is a game changer.
Yes, it is true that 5G represents the fifth generation of mobile networks, but it is so much more than just another ‘G’. It will entirely change what we can do with mobile connectivity. 5G is an innovation platform, which will only be limited by imagination.
We predict that in 2026, 5G networks will carry more than half of the world’s mobile data traffic (growing by a factor of 4.5 by the end of 2026 compared to today). Due to this there is an urgent need for more efficient network technologies, data capacity and better use of the existing spectrum
What is 5g ?
5G is fifth-generation cellular technology that supports multi-gigabit data rates, likely exceeding traditional wireline network speeds. While 5G’s potential speed of 20 Gbps is a significant draw, its low latency — ultimately five milliseconds or less — is even more attractive for enterprise applications that will encompass augmented reality, IoT, location awareness and branch connectivity. 5G is engineered to be more secure than its cellular service predecessors, thanks to its more comprehensive transport security algorithms and safeguards such as network slicing.
5G runs on the same radio frequencies that are currently being used for your smartphone, on Wi-Fi networks and in satellite communications, but it enables technology to go a lot further.
Beyond being able to download a full-length HD movie to your phone in seconds (even from a crowded stadium), 5G is really about connecting things everywhere – reliably, without lag – so people can measure, understand and manage things in real time.
How does it work?
Whereas 2G, 3G and 4G were primarily radio focused, 5G represents an entire system with radio, a telecom core, and operation systems all transformed to support new requirements. This process will involve new radio technologies, a virtualised cloud-based core, and end-to-end management to facilitate automation and new concepts like network slicing.
Technologies at the
heart of 5G
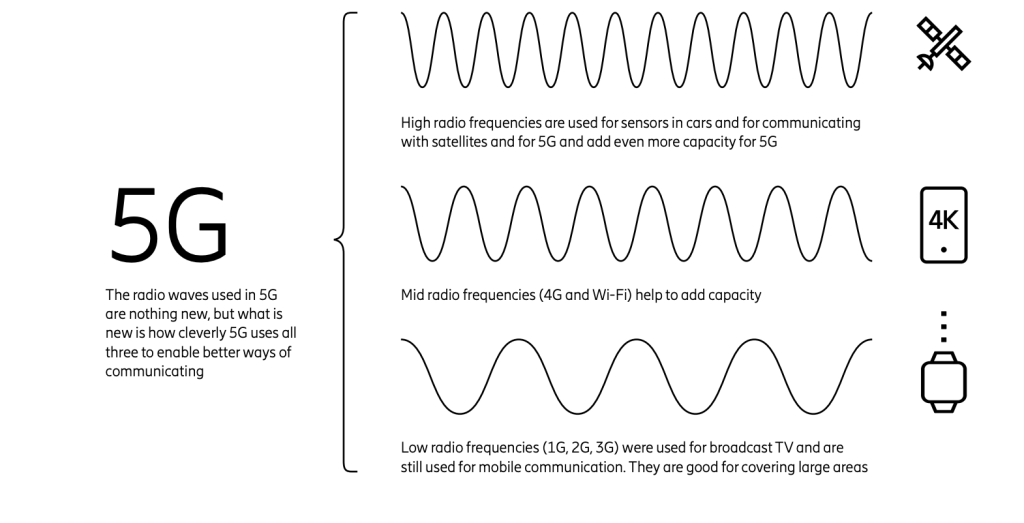
Mobile networks use radio waves to communicate, radio waves have different frequencies and 5G uses three different ranges of radio frequency – low, mid and high.
5G is then deployed to devices and applications through:
The 5G core which is like the brain of the network, where all data is routed in order to get the information to the desired destination.
5G networking technologies which uses radio frequencies and advanced implementations of antennas to provide wireless connectivity to the devices.
Data ingestion architecture for telecom applications
Modern intelligent applications depend on the availability of large amounts of high-quality data. In the telecom industry, where many of them rely on the same data sets, gathering the same data for different purposes is a waste of time and resources. In an increasingly data-driven world, it does not make sense to lock data into a single data pipeline or application. On the contrary, collected data should be available for use in the data pipeline of any application suite that needs it.
Functionality of data pipeline
A data pipeline consists of two main functionality areas: data ingestion and data refinement. One conventional approach to data pipelines has been for each application suite to have its own data pipeline, with its own data ingestion and data refinement functionality. To overcome the inefficiencies of this approach, we’ve created a pipeline which collect all the data from the source and made it available for all the application.
Every data ingestion architecture will have some key functional entities these are data sources, data collectors, data collection architecture and functionality, and the global federated data lake.
A data source is a generic term that refers to any type of entity that exports data, such as a node in a telecom network, cloud infrastructure components, a social media site or a weather site. Data sources may export several types of data – including data about performance management, fault management or configuration management – as well as logs and/or statistics from nodes in a telecom network. Data can be exported either by streaming events, files or both.
The data can either be pushed from the data source to a data collector or pulled from the data sources by data collectors.
Data collectors facilitate data collection from data sources by using their data export capabilities. They are designed to cause minimal impact to the performance of the data sources. The procedures should be optimized from a data source perspective, and data sets should only be collected once instead of repeatedly. Data can be collected as real-time events or as files in batches depending on the type of data and use cases.
Data collection architecture receives the data publications from data collectors and delivering these to the consuming applications that subscribe to them.
federated data lake is the place where the data is stored for future consumption of the application.
Helper applications in Data refinement
Data refinement functionality can be implemented with a set of helper applications that process the raw data available on the data lake. The purpose of having helper applications is to provide supporting functionality for the applications that realize use cases.
Examples of helper applications include:
- security helper applications for de-identification of public data and non-public data
- ETL (extract, transform, load) helper applications for the transformation and preprocessing of raw data into filtered and aggregated data sets
- other repositories to persist structured data for data consumers (applications) with certain needs, such as graph databases for knowledge management.
Tools used to achieve the result :
NiFi: – Get the data from data source and store it as into and HDFS location and publish the message in Kafka
Spark Job: – Consume the message from Kafka and load into the destination tables after transformation
Conclusion
With this data ingestion architecture of data pipelines, it is possible to ensure that the necessary data for all applications, regardless of where they are deployed, is only collected once. We can then make the data available to any application that needs it with the help of a data relay gateway. This secure and efficient solution provides the significant benefit of freeing up application development resources to focus on use-case realizations rather than data management.
6 comments
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
I am an investor of gate io, I have consulted a lot of information, I hope to upgrade my investment strategy with a new model. Your article creation ideas have given me a lot of inspiration, but I still have some doubts. I wonder if you can help me? Thanks.
Your article helped me a lot, is there any more related content? Thanks! https://accounts.binance.com/cs/register?ref=OMM3XK51
The point of view of your article has taught me a lot, and I already know how to improve the paper on gate.oi, thank you. https://www.gate.io/zh-tw/signup/XwNAU