

Redefining Success in Machine Learning: Embracing the Game-Changer – Introducing AdaBoost
Ada boost is a type of supervised machine learning. which is used for both classification and regression. It is also known as the advanced algorithm of decision trees, which is used to avoid decision tree overfitting issues. Ada boost draws a tree, but this tree is not going to grow like a decision tree or like a random forest; instead, it is restricted at some points of nodes, like one root node and two leaf nodes, which are known as stumps.
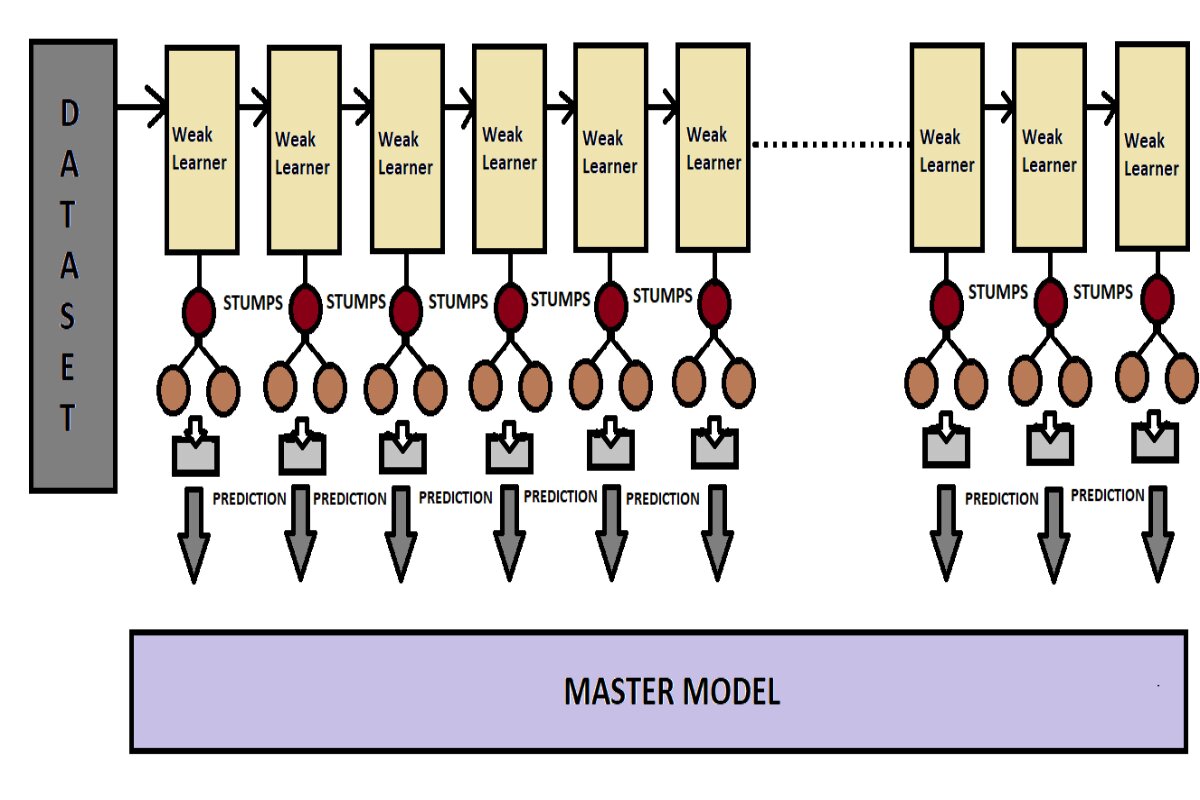
Add boost’s abbreviation is adaptive boosting, which uses the ensemble technique. Where it follows the boosting method, which is nothing but using a sequential approach for data distribution and, in the end, using aggregation to collect all sub-model predictions to create one master model and give predictions. That means Ada boost sequentially bootstraps its data among weak learners; here, weak learners are nothing but the sub-models. These sub-models are simple and relatively less capable on their own compared to more complex models.
Some reasons behind using weak learners:
- They are simple models with lower complexity. With some restricted depth (a tree with only a few nodes).
- They have limited powers since they might not be able to fit in all the training data.
- Instead of weak learners, if you use strong learners (Highly complex sub-models), models could be the reason for overfitting.
- Weak learners, with their high bias, are less likely to overfit.
By combining all learners in the model, the model gets complementary strengths, which will help to remove the weaknesses of all weak learners. That means single weak learners are not that capable of giving an optimal performance, but combining all weak learners solves any difficult problems and creates a strong, accurate, and optimal model.
In AdaBoost, each weak learner is connected, which means that while building a sub-model, sub-model 2 has a dependency on sub-model 1. And each one is getting whole data for training sequentially but couldn’t be able to learn all patterns from the data due to some restriction on their growth. As I earlier mentioned, each weak learner is limited to one root node and two leaf nodes. In Adaboost, the tree is taking up only stumps; therefore, none of the weak learners can learn over the entire pattern of training data, but in another way, using such a weak model together, that is, combining all these weak learners, we could get leverages of complementary strength. This approach helps achieve better overall performance than the decision tree or random forest algorithms.
Let’s understand the workings of AdaBoost with a simple example:
Everyone knows about the relay race. It consists of at least 4 players, each of whom has to run an equal distance but has to run with an iron rod in that race, and after each player has run his part, he has to pass the rod to the other so that he will finish the same race with that rod.

Now suppose there is a distance of 1 km and a team of 4 players. Now each player is given 250 meters to run. The team that completes the race fastest with four such people will be the winner. Now these four people have decided on a time for everyone: if everyone completes the target in 2 minutes, then their team will be the winner. Everyone agreed to this.

Suppose the race starts and the first player takes 10 seconds more than the allotted time; now the next player has to change his speed because the extra 10 seconds have to be covered. .

The second player increased his running speed and covered the earliest delay by up to 6 seconds. because, the first player was delayed by 10 seconds, which the second player had to cover. He tried to reduce the time and succeeded for up to 4 seconds. So here, the earlier damage was avoided by 4 seconds by the second player.

Now the third player also wanted to reduce the 6-second loss by increasing her running speed in the same way, so she also ran faster, bringing the 6-second loss to 2.5 seconds. So it started with a 10-second deficit, which was reduced to 6 seconds by the other player. The same 6-second loss was brought down to 2.5 seconds by the third player. That is, the loss is decreasing step by step.

Now it was time for the last player; if this player could make up the 2.5-second deficit, that player’s team would win. So the latter raced with all his might, and he reduced his 2.5-second time to 0 and won the event.

So what happened was that the initial time loss gradually decreased until the end, and finally, it brought the time loss to zero and won the competition.
This is how Ada Boost works. Ada Boost works on ensemble techniques.
When this algorithm meets the data, it sends the entire data sequentially to each sub-model. It is called a weak learner. Here the initial weak learner takes the entire data and constructs a tree, but as read earlier, this tree has a fixed shape, so it does not grow like all other normal trees. Ada Boost can only grow a tree up to one root node and two leaf nodes. It is also known as a stump. Now, when a weak learner is fed this data in the first stage, it draws a stump and gives the output, and next, it predicts which data points are truly classified and which are not. In the next stage, the weak learner sends all this information to his next weak learner.
In this second stage, the weak learner observes the mistakes of the previous weak learner and tries to avoid the same mistakes made by the previous weak learner. Now, after making the stump of this second weak learner too, this prediction is done. And sends the truly classified and misclassified data points to the next weak learner. And back here, it works in the same way. The third weak learner observes the mistakes of the second weak learner and tries to avoid them. In this way, one weak learner after another learns and finally makes a beautiful, optimal, accurate, and strong model. Because this model is learned by making mistakes, He knows how to correct mistakes. And on the strength of this, this model can easily solve any difficult data.
Let’s see how AdaBoost works in the background.
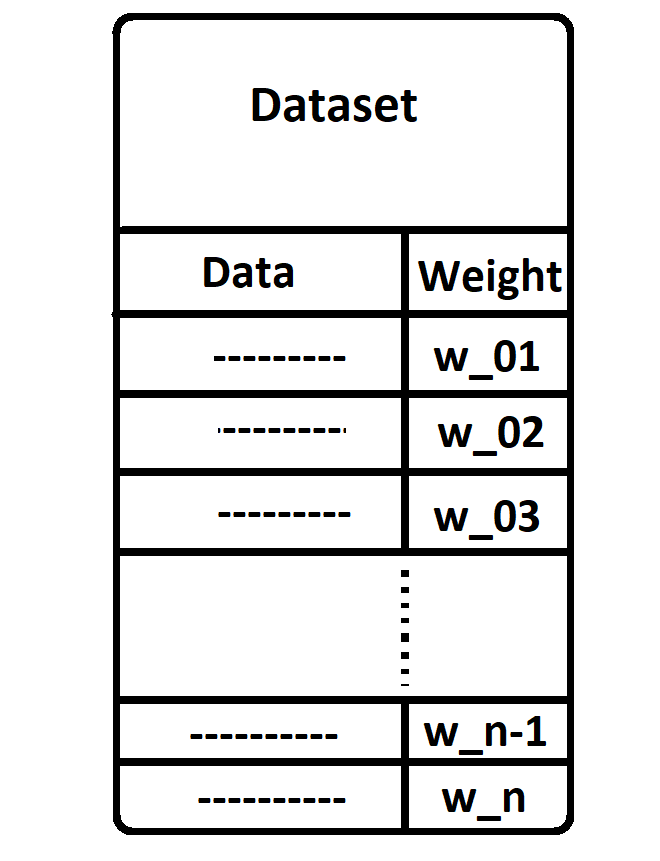
Suppose we have a data set containing 100 entries. Now, in the initial phase, whatever weight is applied to all the data points is the same for all. Each data point is weighted by 0.01, i.e., 1/100.
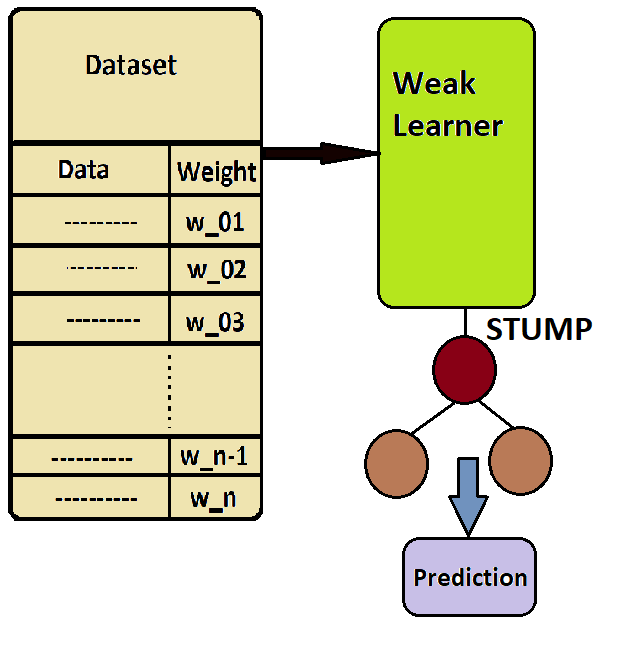
Data is now sent to the first weak learner for training. During training, this weak learner constructs a tree. But the resulting tree is not like a decision tree. It is simply a stump consisting of one root node and two leaf nodes. This first weak learner model produced a tree and gave some output as predictions. So far, the work of the first weak learner is over.
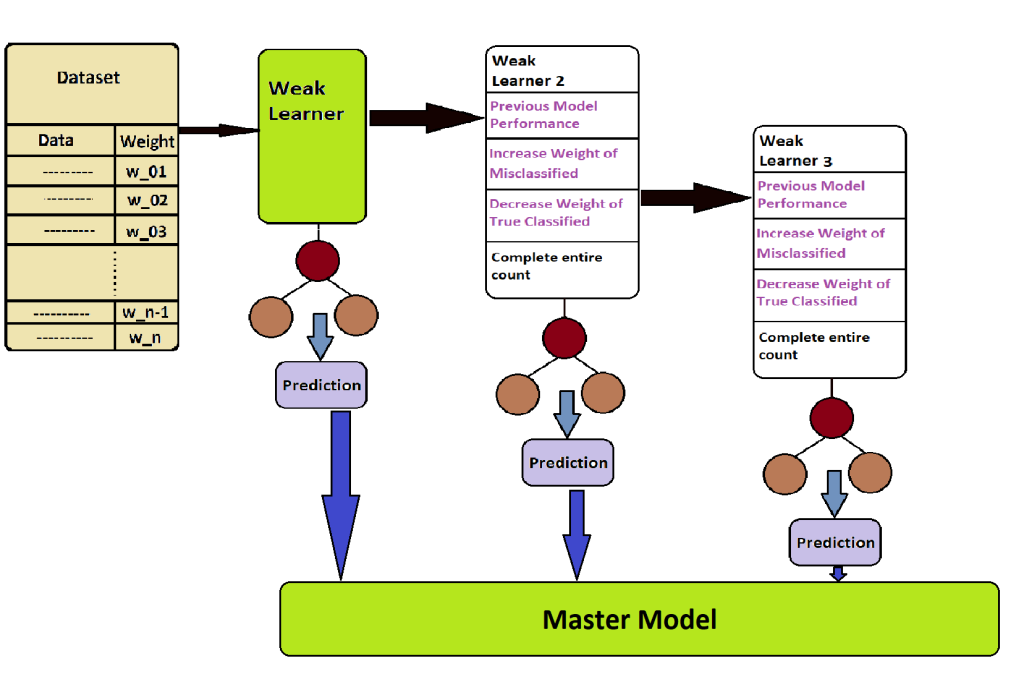
As we read earlier, Ada Boost passes the data sequentially, meaning that the data will now go to the second weak learner, but wait, it’s not all that straightforward. When the second weak learner is created, it has to find out all the model performances of the first model. In this, the previous weak learner has to find out how many data points are correctly classified and how many are not. And from this obtained data, the weight applied to the correctly classified data has to be reduced, while the weight applied to the incorrectly classified data has to be increased. Along with this, among the data coming in from the second weak learner, this wrongly classified data is taken first, and then randomly selected data is taken from the rest of the correctly classified data to complete the remaining number. And this weak learner is trained, and then it becomes a stump, and output is given in prediction.
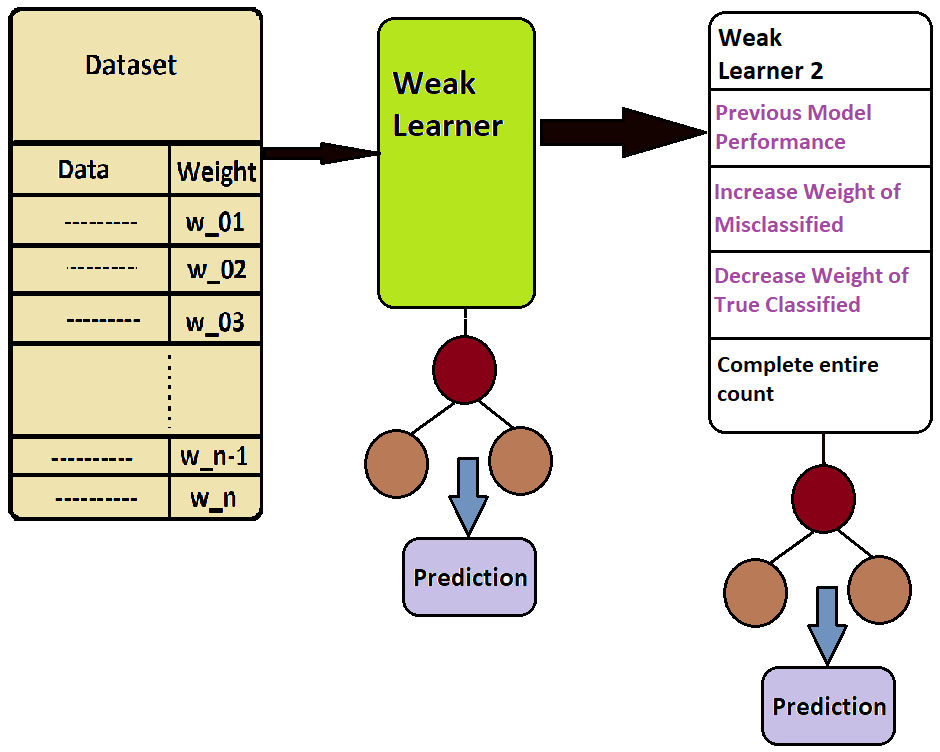
Again, the same method is used for the next weak learner. By default, 50 stumps or 50 weak learners are used, but we can increase or decrease this number.
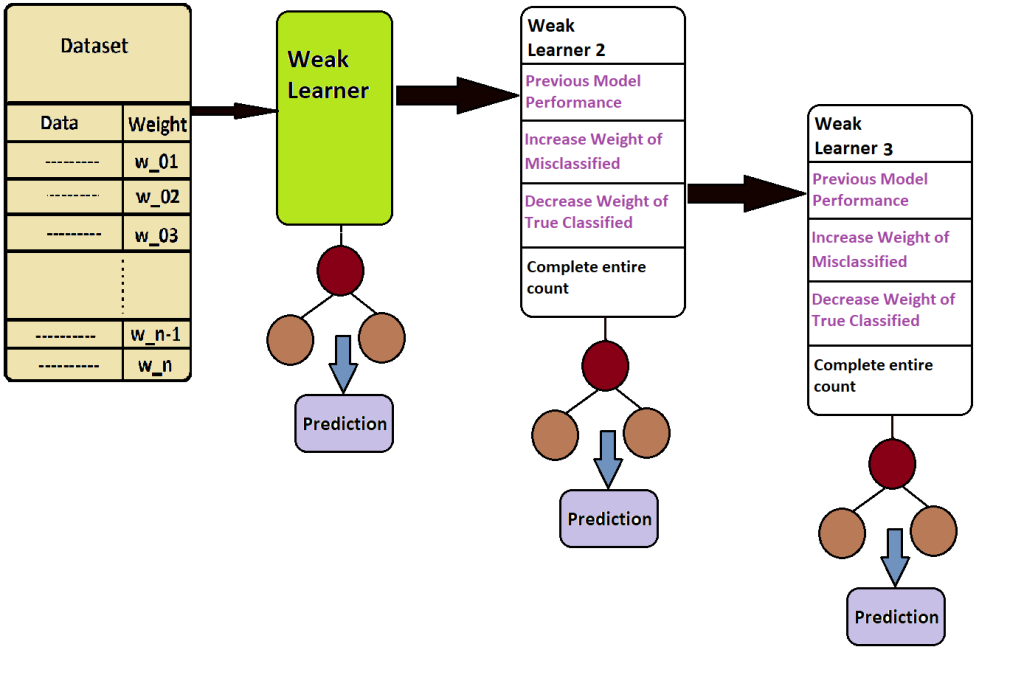
Now in the last stage, the prediction of all these is combined, and if it is classification, the class to which the majority belongs is selected by voting, and if it is regression, the answer obtained by taking the mean of all of them is called model prediction.
Advantages:
- AdaBoost can improve the performance of weak learners significantly, leading to higher accuracy in predictions.
- It handles complex datasets and can capture intricate decision boundaries.
- The algorithm is versatile and can be applied to various classification and regression problems.
Limitations:
- AdaBoost is sensitive to noisy data and outliers, which may negatively affect its performance.
- Training can be computationally expensive, especially when dealing with a large number of weak learners or iterations.
- If weak learners are too complex, AdaBoost may become prone to overfitting.





