A Comprehensive Guide to Understanding Machine Learning and its Algorithms.
Data Science is a process of extracting knowledgeable insights from data by using some of scientific methods. These scientific method are listed below.

- Machine Learning: work on structured data.
- Deep Learning: work on semi-structured or un-structured data.
- Natural Language Processing: work on textual data.
- Data Visualization: works using various library, tools. Usually show the relationship among the data.
Here we are going to see what machine learning is and what types they have.
Machine Learning
Machine Learning is subset of artificial intelligence, which focus on developing algorithms and statistical models to enable computer system, to learn and make prediction without being explicitly programmed. Machine learning relates with study of design, development and algorithms which gives capability of learning to computers. The term machine learning was first introduced in 1959 by Arthur Samuel. In simple word we can say, machine learning build a predictive model which is also known as mathematical model, and that is combination of computer science and statistics.
Machine learning broadly categorized in main 3 category.
- Supervised Machine Learning.
- Un-Supervised Machine Learning.
- Reinforcement Machine Learning.
In machine learning we have two types of variable which is:
- Input variables/ Predictors/ Independent Variables.
- Output Variables/ Targets/ Dependent Variables/ Labels.
Supervised Machine Learning:
This type of machine learning works under supervision since known as supervised. Supervision by labels, that’s why it is also known as Labeled Machine Learning. That mean in this model whatever dataset is received comes with labels, and label is nothing but target variable/ output variable (Input variables + output variables = Dataset). Individual operation is taken place in this type of machine learning.
How it works..?
As human beings, we guess about something, but how? The answer is that we have seen, read, heard something related to those things in our brain till now, and this is all a form of data matching for our brain. Once this data is collected, our brain make predictions about the future related to that particular thing. For a simple example, we can predict who will win a cricket match, or a student studies more than 8 hours a day, we can predict whether he will pass or fail.This is how supervised machine learning works.
Whatever data the model receives, the data comes with supervision, that mean particular output for particular input, and model learns all these patterns which input corresponds to which output and accordingly the model educates itself and adapts itself so that from now, if any input comes for testing, it will use similar inputs based study, and it will give prediction for that input.
Supervised Machine Learning have 2 types of algorithms.
- Regression based algorithms.
- Classification based algorithms.
(Algorithms – is set of rules, must be followed for solving particular problem)
I) Regression:
In regression we deal with those kind of dataset which target or labels in form of continuous value. Here we are trying to regress the value of targets with the help of predictors. That mean, we are trying to understand how the value of dependent variable changes with respect to independent variables. This statistical model use in various industries where continuous value in prediction is important. Suppose SBI SIP calculator calculate the return amount basis on our credentials like years, monthly EMI. Examples: Financial Industry, Marketing Industry, manufacturing Industry, and Medicine Industry.
Most Used Regression Algorithms:
- Linear Regression.
- K-NN (Nearest Neighbor).
- Decision Tree.
- Support Vector Machine.
II) Classification:
In classification we just classify the probabilities about the classes, like class A or class B, class True or class False, class 0 or class 1. Classification in machine learning is the most common and widely used model. Which is used to identify the categories of independent variables. Dataset comes with labels which is in category labels. In this predictive modelling task is mapping the function from input variables to discrete variables, next classification algorithm generate a probability score, and depend on this score class will decide. For example: categorizing the pass and failed students, spam mail or non-spam mail, product categorizing.
Classification algorithms contain two types of algorithms.
- Binary Classification: targets comes with only two possible category. For example – True/False, 0/1, Yes/NO, Spam/Non-Spam.
- Multiclass Classification: targets comes with more than two categories, each category is assigned with one label. For Example – {Bad, Average, Good, Better, Best }, { High, Medium, Low}.
Most Used Classification algorithms:
- Logistic Regression.
- K-NN.
- Decision Tree.
- Support Vector Machine.
- Ada boost.
- Naïve Bayes.
In algorithms there is two types of learners: Lazy Learner and Eager Learner. In lazy learner (like K-NN) model store the training data in stationary mode in his memory and wait until testing input come for prediction, and once we ask for prediction for that test case, algorithms take comparatively less time for training and more time for predicting since it known as Lazy Learner. While Eager Learner (remaining all) construct architecture before introducing the input for testing, so what happen here eager learner build an explicit description of training from training data and using this description model take out the prediction for that particular input which came for testing. Therefore Eager learner takes more time for training and less time for testing. Actually Lazy learner is useful on such data which is continuously changing, and data size is too large. Due to continuously changing training data, data goes outdated frequently, thus training fast comparatively Eager.
Un-Supervised Machine Learning
In un-supervised machine learning we get dataset without any target or labels. We need to build a model, on independent variables only. This type of model mainly build for getting pattern from dataset, extract meaningful insights which is useful to understand what actually data is. The main objective is finding the underlying hidden pattern, structure of data and make groups of similar contents according to their similarities. Generally unsupervised machine learning use for complex problem because, here dataset comes without any labels, supervision.
In un-supervised machine learning, there is two types of algorithms:
- Clustering Algorithms – collecting all similar data objects in one single group.
- Association Algorithms – use to find relationship between variables. It determines the set of items that occur in the dataset which is mostly connected to another. For example who buy shoes, tend to purchase pair of socks.
Un-Supervised Algorithms:
- K-Mean.
- Hierarchical Clustering.
- Neural Network.
- Principal Component Analysis (PCA).
- Apriori Algorithm.
Reinforcement Machine Learning:
In this very interesting type, the model learns everything itself. Model enables itself to make decisions by differentiate between reward and punishment, and this process is continuously goes on. Now if we want to give an example, the online game of chess beats the world champion Garry Kasparov. Now you might have one question like, where did that game have so much knowledge..? The answer is knowledge came to that game through his own mistakes and successes. That game has enabled himself to give such result where even the world champion will not beat him. Nowadays, it is becoming difficult to beat playing robots in any online game.
I will explain this analysis with the example of a small child so that you will understand in very easily. Suppose a small kid touches a hot object, he quickly pulls his hand back, because his hand gets burnt. Now he has got this thing in his mind and he will not touch any hot object knowingly in future. This knowledge gained from punishment. Now suppose the same kid is praised or given some reward by the teacher in his school for some good work, now kid has also got in his mind that if he does this work, he gets reward and appreciation. So he tries to do the things that will reward him, and this knowledge gained from the reward.
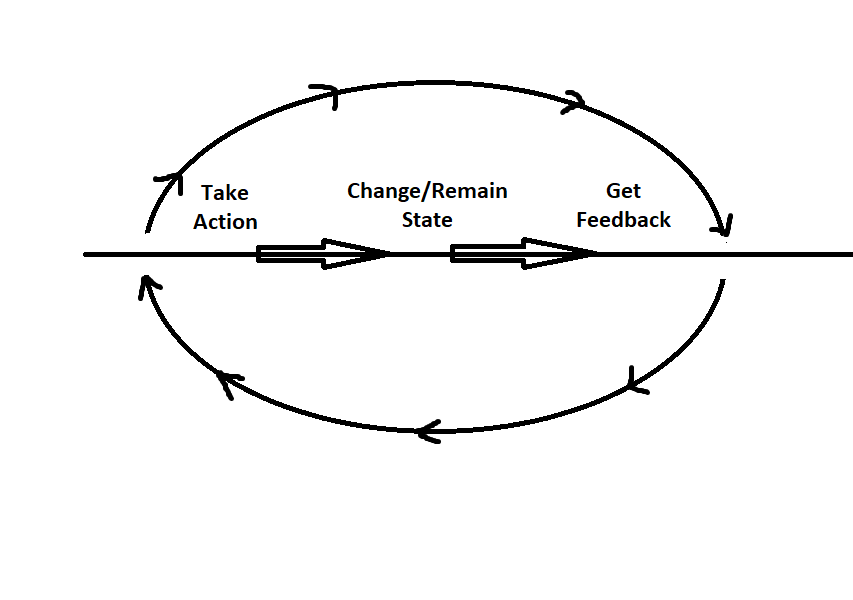
The reinforcement works on same line. Reinforcement agents receive positive feedback for good things and negative feedback for bad things, and learns on this feedback. The steps taken place in this is shown below.
- Take action
- Change / Remain State
- Get feedback
Reinforcement Algorithms:
- Q- Learning
- State Action Reward State Action (SARSA)
- Deep Q Neural Network (DQN)
Reinforcement learning learn from environment not from data like supervised and unsupervised. It works like human brain while taking any decision. Its decision is takes place in sequentially manner.
Conclusion:
Machine Learning can handle complex task which cannot been handled by human, because human has some limitations like, keeping huge data in mind and memorize as per requirement is simply impossible to human, since human invented machine learning who does same task with speed and efficiently.