
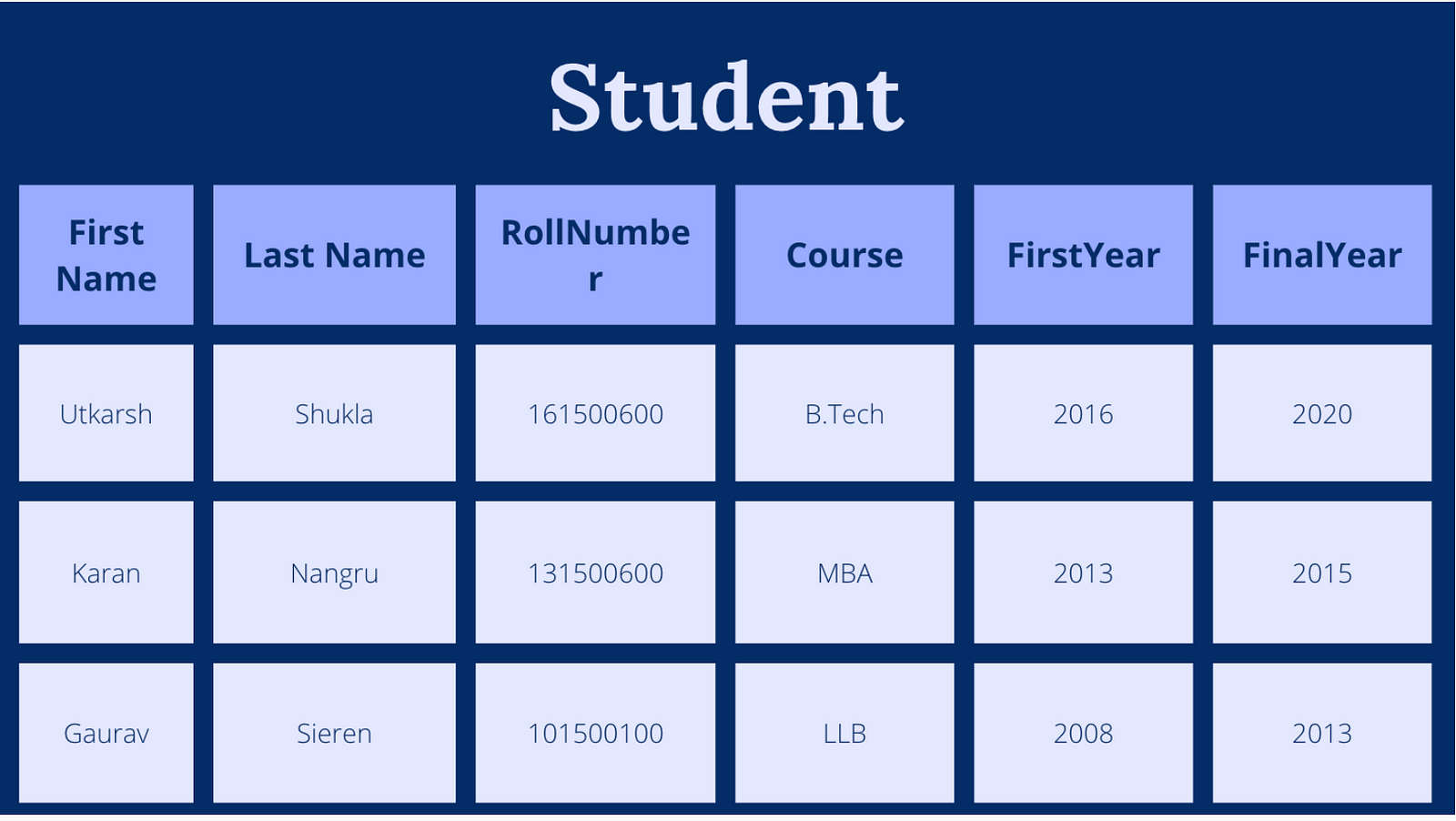
Database Designing
Introduction
In this blog, we are going to cover the database’s design, for which we will learn what a database is. what are the different types of databases available? How and when to prefer what. Different types of theorems and properties. What is the analysis required to design a database? and at the end, we design a database system for a parking application.
What is a Database?
A database is a place where data or information is stored. In short, we can say that it is a collection of data. Data can be anything that has a value to it for example any object that you can see around you will fall in the category of data as it has some value associated with it. Storing that data in a computer system is called a database. The database can be on your server-based system or nowadays serverless databases are also becoming very popular that everything will be managed by the cloud provider such as AWS RDS or GCP firestore. In the case of serverless, we are not required to worry about the hardware as it will be managed by the provider. I hope the definition of a database is clear by now, let us look at the different categories of databases.
Categories of Databases
The two most popular databases that are used are –
Relational Databases and RDBMS-
In relational databases, everything is present in the form of tables. Each table will have columns and rows. Every row will have entries for each column. So the common structure is maintained around the database. Let’s take a look at RDBMS also-
- RDBMS stands for the relational database management system.
- RDBMS is based on the relational model introduced by E.F. Codd.
- RDBMS consists of databases, where each database can have multiple tables.
- Every table consists of records or data entries.
- Each entry can be called a row, that consists of columns.
- The organized view of the dataset in the relational table is known as the logical view.
- No two identical entries can be made in a relational table.
- Rows are also called tuples.
- A column is also known as the field of the table.
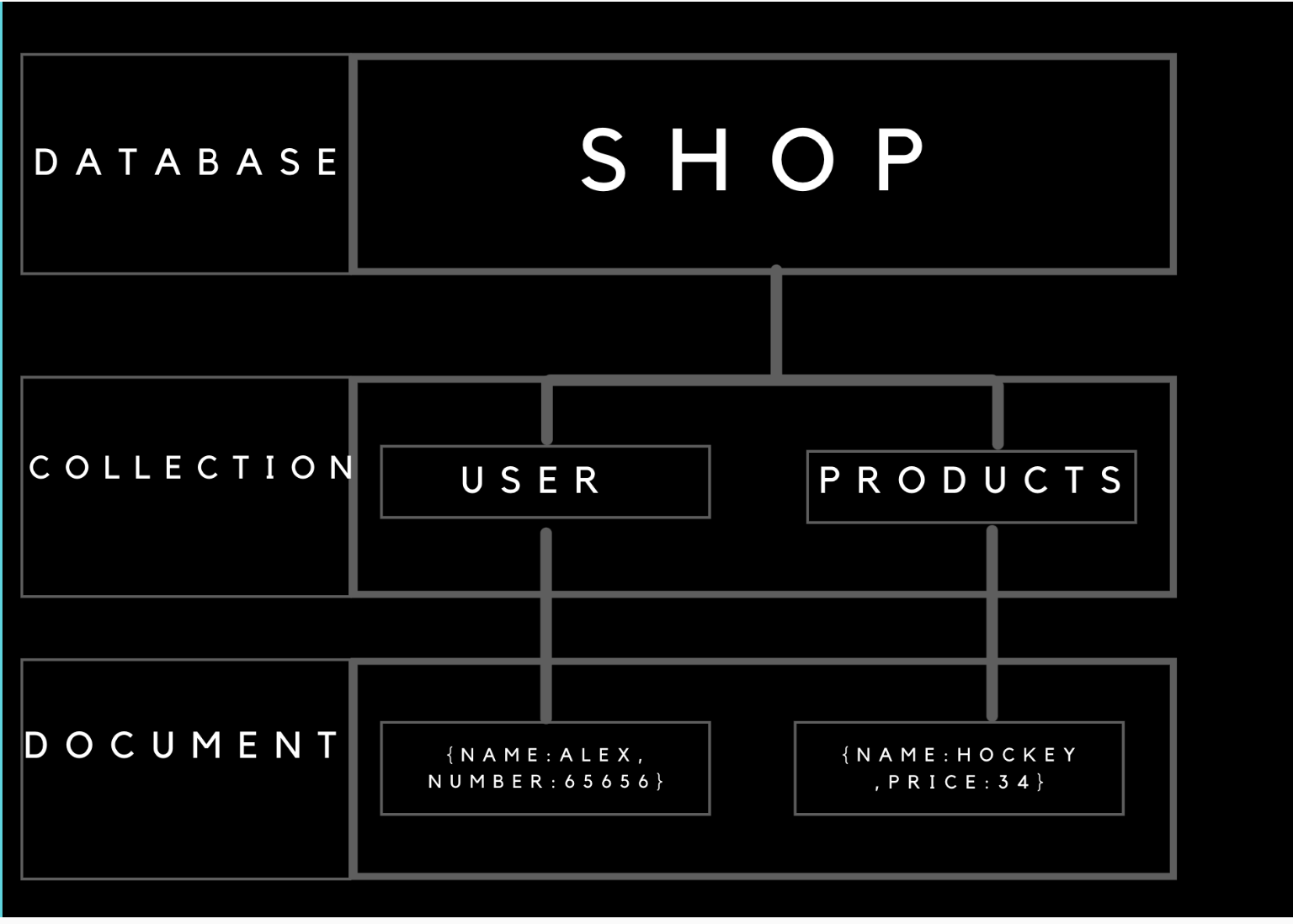
Non-Relational Databases or NoSQL
In a NoSQL database, we have the data stored in an unstructured or semistructured way. Data is stored in the form of documents that is JSON(JavaScript Object Notation). JSON object consists of key-valuepairs, where the key will be of type string and value can be string number or a nested object. inside that database, we have collections, i.e. similar to tables that we have in SQL. In each collection we have a set of documents, documents are the JSON, objects, or dictionary whatever you want to call them. Eg-> {“name”: “Utkarsh”}By having nested objects we can have many sub-documents inside a single document.
{‘name’ : ‘Utkarsh’, ‘address’ : { ‘city’ : ‘Kanpur’, ‘post’ : { ‘number’ : 208001 }}}
here you can see in one document we are having many documents.
NoSQL is schemaless, i.e. no two documents are required to have the same fields. That’s what makes it a Non-Relational Database.
What is Normalization?
Normalization is the process of reducing redundancy. By Redundancy, we mean duplication of information in a table. Let’s discuss this with an example, suppose we are creating a table of employees in a company, each employee is associated with a department, so while creating a table for employees, we insert all the department information also in it. like department id, department name, and department manager. So suppose if many employees belong to the same department then we will be inserting the values of the department, again and again, it is called data redundancy. Instead of this we could have a separate table of departments and can link it to the employee table using departmentId.

To overcome this we can have a separate table of departments. We can link it here, with the departmentId, by a lot of writing operations will be prevented, and data updating and deletion can be done easily. No data loss will occur if all the data from employees is deleted, as the department will be having its own table.
Having Normalization in the mind while doing the database designing is very important. It helps in optimized database solutions.
Different Normal forms are-
- First Normal Form(Atomicity should be there)
- Second Normal Form(It should be in first normal form with no partial dependency)
- Third Normal Form(It should be in second normal form with no transitive dependency)
- BCNF (Boyce Codd Normal Form)(Table should be in the third form and every functional dependency is the super key of the table)
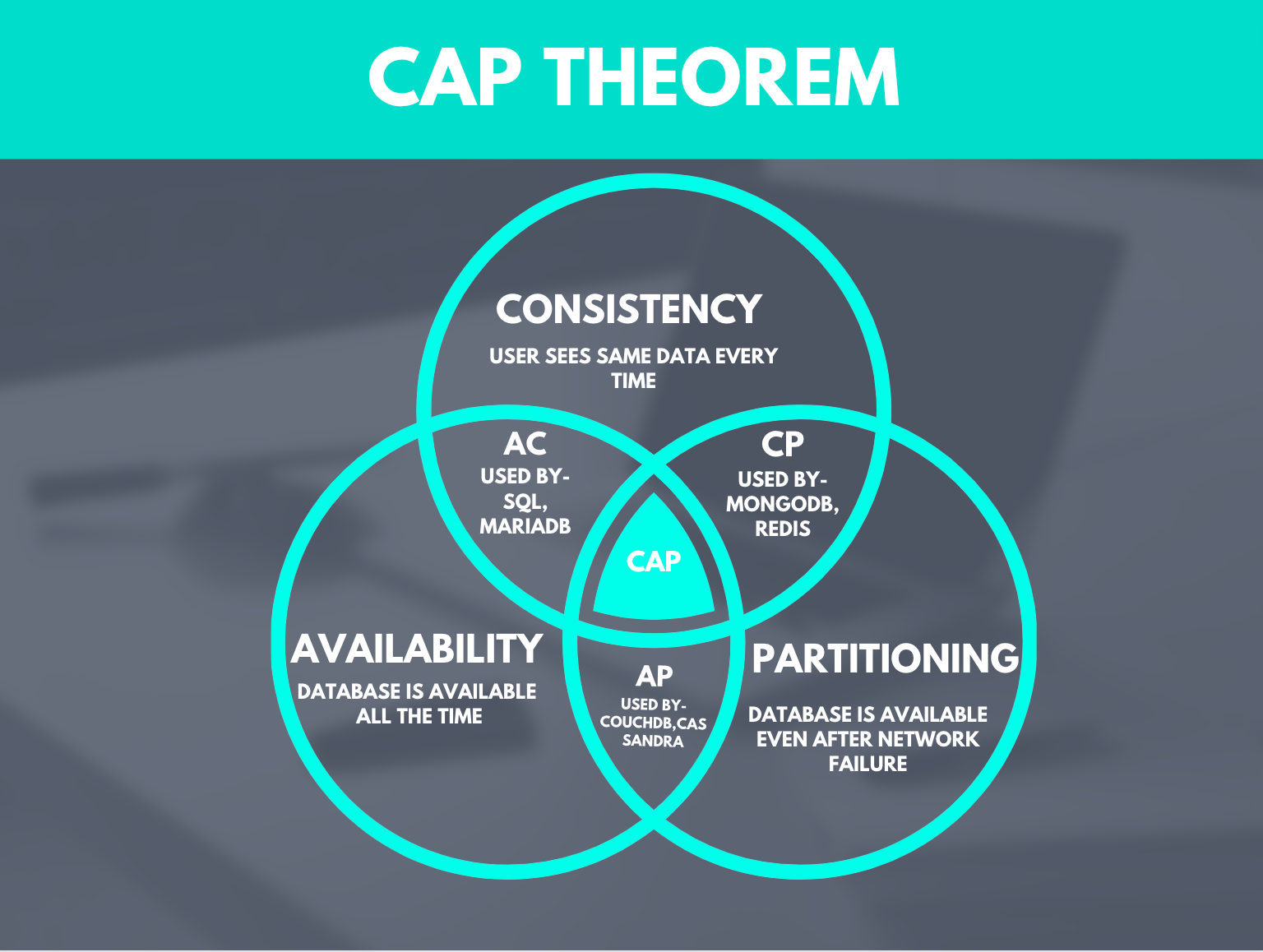
CAP Theorem
CAP stands for Consistency, Availability, and Partitioning.
CAP theorem is one of the most popular theorems in a database or system design. Let us understand each of them one by one.
Consistency- Consistency means data should be consistent or we can say the same around the nodes or racks. In the distributed system, there are many database nodes, so the data should be the same in all of them.
Availability- Availability means data should be available whenever a read request is made. A read request can ask for data from any nodes, so all the nodes should be available.
Partition tolerance- A partition is a communications break within a distributed system, i.e. a lost or a delayed connection between two or more nodes. Partition tolerance means that the cluster must continue to work despite any number of communication breakdowns between nodes in the system.
It is important for a database to follow the CAP theorem, but it is near impossible to follow all three at once.
Partitioning is the most important part of the CAP, so it is almost mandatory in all the designs. The options that are available are Consistency and Availability. Let’s take a look and decide when to prefer consistency and when to prefer availability.
CP Databases- It delivers consistency and partition tolerance at the expense of availability. When a partition occurs between any two nodes, the system has to shut down the non-consistent node which means that it will be unavailable until the partition is resolved. These types of databases are preferred when transactions are the key requirement. An example of such databases will be ATM or bank databases when data consistency is the top priority. Examples of the databases using CP are- MongoDB, Redis
AP Databases- It delivers availability and portion tolerance at the expense of consistency. In this case, all the nodes will be always available, but the data read operation may result in an old dataset because of the lack of consistency. When the partition is resolved the nodes resync and the data is updated to the latest. Applications such as Hulu and Instagram are using the AP database model. Examples of the databases using AP are- Cassandra and Couch DB.
CA Databases- It delivers consistency and availability at the expense of partitioning. They are not able to handle network breaks or we can say they do not have fault tolerance, so they are preferred very less. Examples of the databases using CA are- MySql, MariaDB
ACID Properties
ACID properties are the key things that are required to be kept in mind while designing a database in which transaction plays a key role.
ACID stands for-
- Atomicity
- Consistency
- Isolation
- Durability
First of all, let us discuss what transaction means. The transaction is a term that is used when all of the queries or statement gets executed on the database or none of them gets executed. Transactions can also be called a set of instructions. Let’s have a look at ACID properties one by one-
Atomicity- Atomicity means either the whole transaction will be executed or none of it will be executed, that means all the instructions should execute or none of them should execute. Transaction Management Component takes care of atomicity.
Consistency- Consistency means whenever a write operation has happened on a node, the value must be updated in all other nodes as well, that is the consistency of data should be there.
Isolation- Isolation means every transaction should be isolated from one another, and none of them should affect each other. The concurrency component takes care of isolation.
Durability- If any write operation that is any database change has occurred it must remain irrespective of the software or hardware failure. Recovery Management Component takes care of it.
Sharding
Sharding is the process of dividing the dataset and storing it into different nodes called shards. Same data can be replicated around different nodes to make a better availability of the dataset.
Horizontal Scaling
Horizontal scaling means adding more resources to our database, that is adding more clusters or in short, we can say adding more structure to our database machines.
Vertical Scaling
Vertical scaling means increasing the performance of the machines by adding more power to them, such as by adding more processors. Adding more memory, or increasing the network speed also falls in the category of vertical scaling.
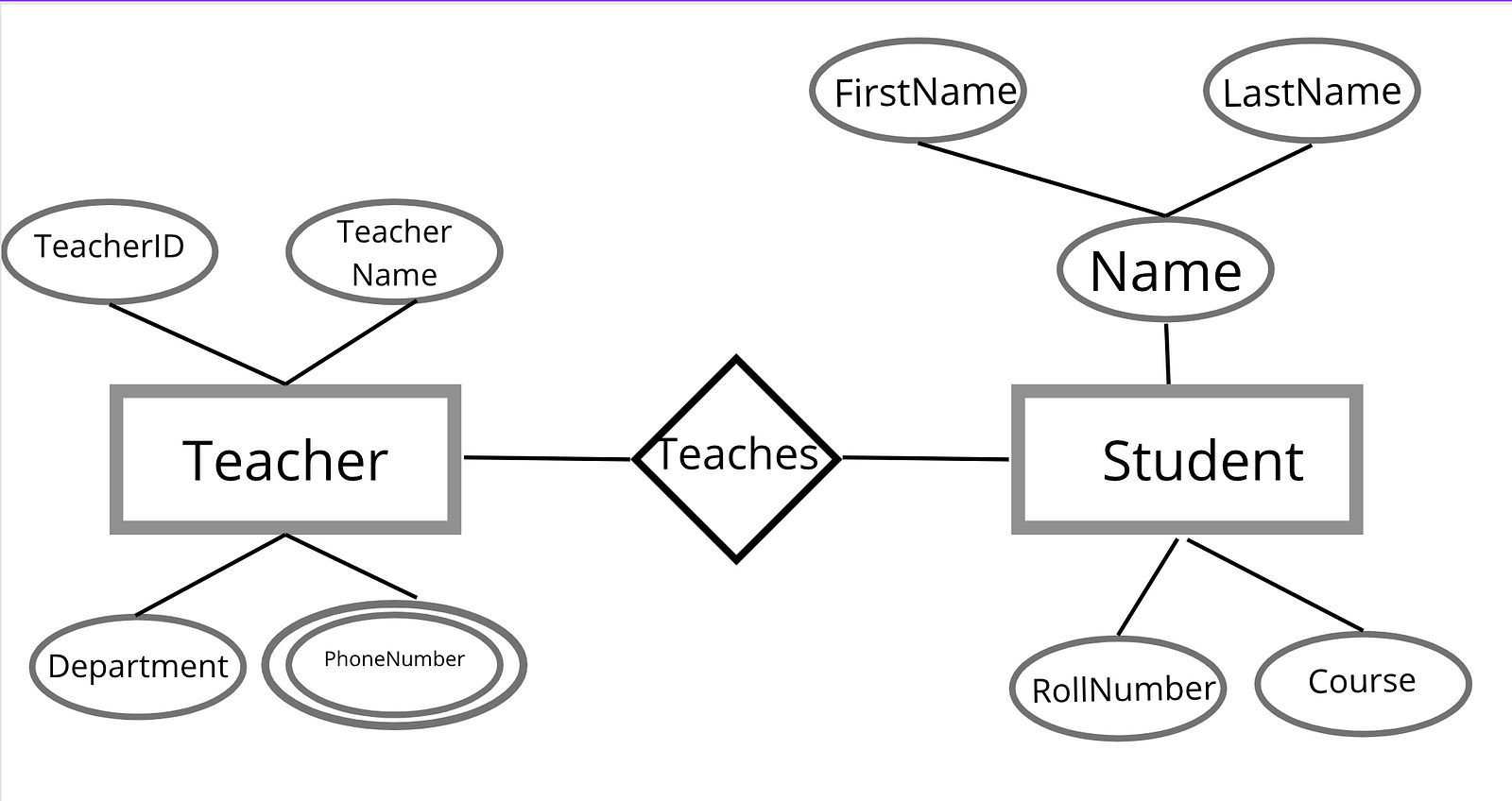
Entity Relation (ER) Diagram
ER diagram was firstly introduced by Dr. Peter Chen in1976. It is a diagrammatic representation of the designing of the entities and forming a relationship between them that can be easily understood by the non-technical person as well. In ER diagram every entity or an object is represented with its fields and its relation with other entities is defined so that while creating a database or schema it will be easy to understand it. Every entity is unique in its own way no two entities can be the same, they must be distinguishable from other entities. Examples of entities are pen, car, student, employee, etc. There are two types of entities-
- Tangible Entities- Tangible entities are those entities that exist in the real world, such as cars, bikes, and pens.
- InTangible Entities- InTangible entities are those entities that do not exist in the real world, such as accounts, and employees.
The collection of the same type of entities is called entities set.
The entity set is represented in the rectangle bracket.
Attributes are the units that describe the characteristic of the entity. For example, if a student is an entity then the attribute of it will be the student name, roll number, and class all these are the attributes of the entity. Every attribute has a domain that is the type of value it stores like the name will be a string, roll number will be an integer. Every attribute is represented in the form of an oval or ellipse, they are connected with the entities with a line. Every attribute that can be further divided is known as a composite attribute like a name can be divided into first name, last name, and middle name. Whenever an oval shape is connected to an oval shape that is not connected to an entity then it is known as a composite attribute.
Similarly, if an attribute can have multiple values then it is represented in the form of a double circle or double ellipse. Examples of the multivalued attribute are email and phone numbers.
Derived attributes are those attributes that are derived from some other attribute. An example of it is age, which is derived from DateOfBirth, here DOB is referred to as a stored attribute. The derived attribute is represented in the form of a dotted oval.
Relationships are the relation between two or more entities, for example, the relation between student and teacher, is teaching. so they will be connected to each other with a diamond symbol. Relationship can be-
- One to one
- One to many
- Many to one
- Many to many
Designing a database for a parking lot software
How the parking lot is constructed?
Let us assume that there are multiple blocks of parking available. Every block will consist of floors. Every floor consists of some parking spots with a number. Every floor might not be containable for all types of vehicles, as vehicles can be small, medium, or large.
How does the parking system work?
A customer can book the slot on-spot.
A customer can have a pass(weekly, monthly, or yearly)
A customer can book the spot online.
For the customers having the pass, a floor or multiple floors are reserved and no slips are generated for them, they either have a card or a sticker on their windshield to identify them.
Let us identify the entities-
- Block
- Floor
- Slots
- Customer
- Pass
- ReservationSlip
- ParkingSlip
Now we will create attributes for each entity.
Attributes for Block-
- BlockId (PrimaryKey, will always be unique)
- BlockName (String)
- NumberOfFloors (Integer)
- IsFull (Boolean- True or False)
Atttributes for Floor-
- FloorId (PrimaryKey, will always be unique)
- BlockId(ForeignKey to block)
- IsFull (Boolean- True or False)
- IsReserved (For permanent Customer, Boolean True or False)
- NumberOfSlots (Integer, total number of parking available in it)
- SmallVehicleSupport(Boolean True or False)
- MediumVehicleSupport(Boolean True or False)
- LargeVehicleSupport(Boolean True or False)
Attributes for Slots-
- SlotId(PrimaryKey, will always be unique)
- FloorId(Foreign Key to the floor table)
- IsFull (Boolean- True or False)
Attributes for Customer
- CustomerId (PrimaryKey, will always be unique)
- MobileNum (Integer)
- VehicleNumber(String)
- IsPermanent (Boolean- True or False)
- RegDate (Date of the registration)
Attributes for Pass
- PassId (PrimaryKey, will always be unique)
- CustomerId (Foreign key to customer table)
- StartDate (Date from which pass was created or is valid)
- EndDate (Date on which pass will expire)
- Amount (Amount of the pass )
Attributes for ReservationSlip
- Id (PrimaryKey, will always be unique)
- CustomerId (Foreign key to customer table)
- StartDate (Date from which pass was created or is valid)
- EndDate (Date on which pass will expire)
- Amount (Amount of the pass )
Attributes for ParkingSlip
- Id (PrimaryKey, will always be unique)
- ReservationId (Foreign key to reservation table)
- StartDate (Date from which pass was created or is valid)
- EndDate (Date on which pass will expire)
- Amount (Amount of the pass )
We haven’t covered the edge cases such as penalty and specific timing that can be added by adding more keys, just to keep it simple and easy to understand we have kept only the basic cases.
Now, let us design an ER diagram or data model for the same. We will be breaking our ER diagram into two parts, in one we will consider block, floor, slot, and reservation slip, while in the another we will form a relationship with the customer so that it can be easy to understand.
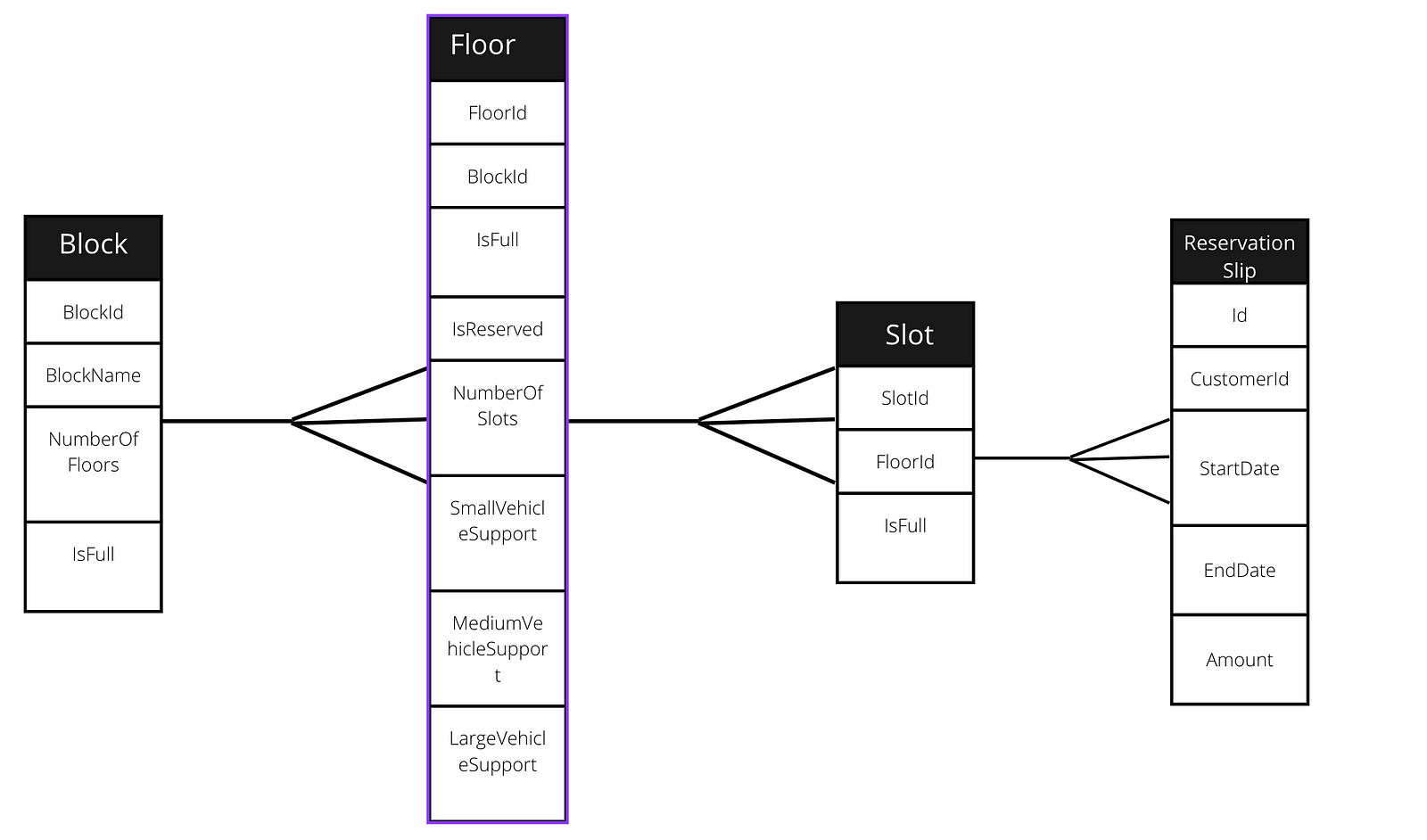
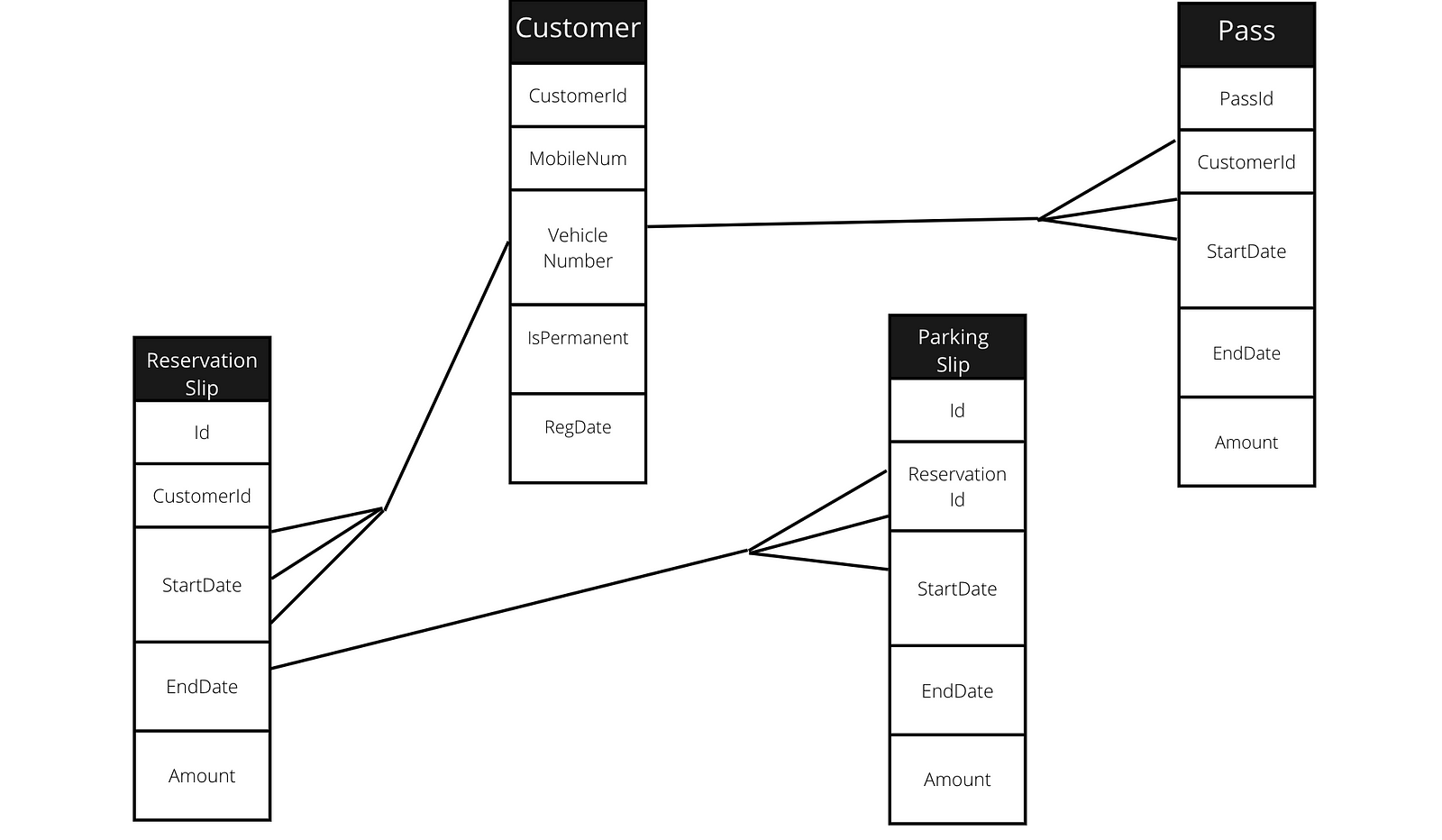
In the end we have created a basic database design of our parking system, in terms of CAP theorem we can follow CP here, that is consistency and partitioning because the consistency of data is the key thing here, for the databases we can go with Redis or MongoDB as both them uses CP very well.
Conclusion
That’s it for this time, in our next blog we will try to cover the System design and its basics. Please feel free to ping me in case of any suggestions or queries. For more blogs checkout-
Still Curious? Visit my website to know more!
For more interesting Blogs Visit- Utkarsh Shukla Author
References are taken from the Internet.


