

Why Data Engineering is the Backbone of Digital Transformation
Data engineering makes data available and usable for data scientists, analysts, BI developers, and other specialists. It takes dedicated experts – data engineers – to design and build systems for gathering and storing data at scale; moreover, they prepare it for further analysis.
- Within a large organization, many different types of operations management software (e.g., ERP, CRM, production systems, etc.) usually manage databases with varied information.
- Additionally, separate files often store data, or external sources — such as IoT devices — provide it in real time.
- Scattering data in different formats prevents the organization from gaining a clear picture of its business state and running analytics effectively.
Data engineering is the process of designing and building systems that let people collect and analyze raw data from multiple sources and formats. These systems empower people to find practical applications of the data, which businesses can use to thrive.
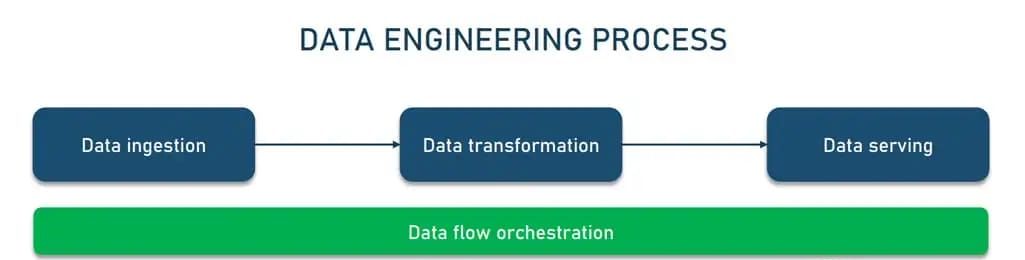
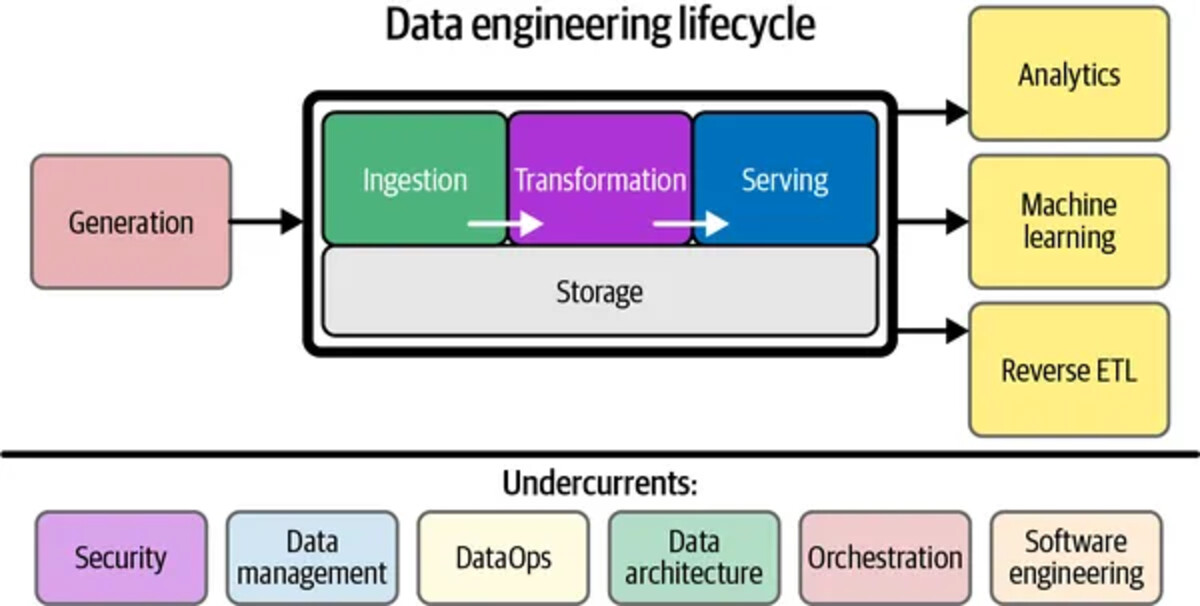
Data Ingestion
The process moves data from multiple sources into a target system to transform it for further analysis. Data comes from various sources like SQL, NoSQL, and files (JSON, XML); furthermore, it exists in various forms and can be both structured and unstructured.
Data Transformation
The process cleans, filters, validates; and applies extracted data to meet the needs of users. It involves removing errors and duplicates from data, normalizing it, and converting it into the required format.
Data Serving
It involves making data available and accessible to users, applications, and systems efficiently and promptly. Data serving delivers transformed data to end users — a BI platform, dashboard, or data science team.
Data Flow Orchestration
It provides visibility into the data engineering process, ensuring that all tasks are successfully completed. It coordinates and continuously tracks data workflows to detect and fix data quality and performance issues.
The mechanism that automates ingestion, transformation, and serving steps of the data engineering process is known as a data pipeline.
Data engineering pipeline
A data pipeline uses tools and operations to move data from one system to another for storage and further handling. Data engineers, therefore, construct and maintain data pipelines as their core responsibility. In addition, they write scripts to automate repetitive tasks and jobs.
Organizations commonly use pipelines to migrate data between systems or environments (such as from on-premises to cloud databases). Moreover, they wrangle data by converting raw data into a usable format for analytics, BI, and machine learning projects. Additionally, they integrate data from various systems and IoT devices, and finally, copy tables from one database to another.
“As the backbone of modern data-driven decision-making, data engineering continues to evolve—empowering businesses to harness the full potential of their data. Stay curious, keep learning, and embrace the challenges to build robust, scalable, and efficient data systems.”





