ViT- Vision Transformers (An Introduction)
So-called generative AI is not just about large language models (LLMs). Processing and understanding other formats like Images, and videos are equally important.
In this article, I will try to give a non-technical overview of ViT (Vision Transformers), that have emerged as successors of CNN in Computer Applications like image classification, object detection, and semantic image segmentation.
ViT model architecture was introduced in “An Image is Worth 16*16 Words: Transformers for Image Recognition at Scale”. If you want, you can give it a try: [https://arxiv.org/abs/2010.11929]. Here, I intend to touch upon it. It is a researchers work to go deep, and I am currently not a researcher. My role is to understand and apply. And always remembering that new technologies will come.
But let me begin from the beginning. The Transformer Architecture.
The key idea behind the success of transformers is attention. It helps us consider the context of words and focus attention on the key relationships between different tokens.
Attention is about comparing ‘token embeddings’ and calculating a sort of alignment score that encapsulates how similar two tokens are based on their contextual and semantic meaning.
In the layers preceding the attention layer, each word embedding is encoded into a “vector space”. In this vector space, similar tokens share a similar location (a key idea behind the success of embeddings). Mathematically, dot product of two similar embeddings will result in higher alignment score compared to embeddings that are not aligned.
Before attention, our tokens’ initial positions are based purely on a “general meaning” of a particular word or sub-word token. But as we go through several encoder blocks (these include the attention mechanism), the position of these embeddings is updated to better reflect the meaning of a token with respect to its context. The context being all of the other words within that specific sentence.
In other words, the tokens are pushed towards its context-based meaning through many attention encoder blocks.
This is what pretraining language models essentially is.
Now, we can apply attention in CNNs. But attention in CNNs is computationally limited. It is a heavy operation and does not scale to large sequences. Therefore, it can only be used in later CNN layers — where the number of pixels are less. This limits the potential benefit of attention as it cannot be applied across the complete set of network layers.
Transformer models do not have this limitation and instead apply attention over many layers.
So, what is ViT about?
As I see it, it is just (preprocessing image into a suitable format) + (pushing it toseries of transformers blocks).
The high-level process for doing this is as follows:
- Split the image into image patches.
- Process patches through the linear projection layer to get initial patch embeddings.
- Preappend trainable “class” embedding to patch embeddings.
- Sum patch embeddings and learned positional embeddings.
After these steps, we process the patch embeddings like token embeddings in a typical transformer. Let’s dive into each of these components in more detail.
1. To Image patches: Our first step is the transformation of images into image patches. In NLP, we do the same thing — we transform the sentences into tokens. It is not very hard to imagine if you know LLMs. Images are sentences and patches are word or sub-word tokens.
NLP transformers and ViT both split larger sequences (sentences or images) into tokens or patches.
2. Linear Projection: After building the image patches, a linear projection layer is used to map the image patch “arrays” to patch embedding “vectors”.
The linear projection layer attempts to transform arrays into vectors while maintaining their “physical dimensions”. Meaning similar image patches should be mapped to similar patch embeddings.
By mapping the patches to embeddings, we now have the correct dimensionality for input into the transformer.
3. Learnable Embeddings: One feature introduced to transformers with the popular BERT models was the use of a [CLS] (or “classification”) token. The [CLS] token was a “special token” prepended to every sentence fed into BERT.
This [CLS] token is converted into a token embedding and passed through several encoding layers.
Two things make [CLS] embeddings special.
- First, it does not represent an actual token, meaning it begins as a “blank slate” for each sentence.
- Second, the final output from the [CLS] embedding is used as the input into a classification head during pretraining.
Using a “blank slate” token as the sole input to a classification head pushes the transformer to learn to encode a “general representation” of the entire sentence into that embedding. The model must do this to enable accurate classifier predictions.
ViT applies the same logic by adding a “learnable embedding”. This learnable embedding is the same as the [CLS] token used by BERT.
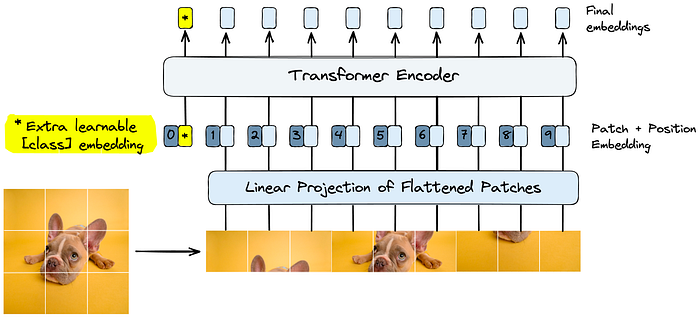
The preferred pretraining function of ViT is based solely on classification, unlike BERT, which uses masked language modeling. Based on that, this learning embedding is even more important to the successful pretraining of ViT.
4. Positional Embeddings: Positional embeddings enable the model to infer the order or position of the puzzle pieces. For ViT, these positional embeddings are learned vectors with the same dimensionality as our patch embeddings.
After creating the patch embeddings and prepending the “class” embedding, we sum them all with positional embeddings.
These positional embeddings are learned during pretraining and (sometimes) during fine-tuning. During training, these embeddings converge into vector spaces where they show high similarity to their neighboring position embeddings — particularly those sharing the same column and row.
After adding the positional embeddings, our patch embeddings are complete. From here, we process the embeddings into a typical transformer model.