Self-Supervised Learning — A Comprehensive Introduction
Notes: For more articles on Generative AI, LLMs, RAG etc, one can visit the “Generative AI Series.”
For such library of articles on Medium by me, one can check: <GENERATIVE AI READLIST>
—–
I wanted to touch upon something that makes the core of generative learning. Self-supervised is the most basic concept of them all. A must for those who do not like just tapping keys and using methods without knowing the underlying mechanism.
————————
Let’s start with a definition of self supervised learning.
“It is a learning technique which obtains supervisory signals from the data itself.”
It works on the hypothesis that data itself has a lot of information. So if we can leverage the underlying structure in data, we can create a supervised learning task in an automated manner from that unlabeled data in order to learn representations for that data.
Most of the data in the world is unlabelled. And labelling is very very resource intensive. Also, if we limit learning of ML models to labelled data, we are giving up lots of opportunities.
That’s we need alternate labeling processes. Now, there are labels that are automatically available along with the data such as hashtags for social media posts, GPS location for images etc. We also have ML techniques that can automate the labeling process. The Snorkel model from Stanford is an example.
But, why can’t you learn from the data itself?
And this is exactly why we have self-supervised learning.
Self-supervised learning can learn representations from unlabeled data, and these learned representations can be used in a number of different machine learning tasks.
Let’s understand the basic idea of self-suprvised learning.
- The input to a self-supervised model is data with no labels.
- The model then splits this input into two parts. One is the observed part that it can see that makes up the X variables. The second is the hidden part. This is the Y variable that the model has to predict.
- The self-supervised model is set up in such a way that it uses the data available, the observed portion of the data to predict the hidden portion of the data.
- And in the process of trying to predict the hidden part from the observed part, self-supervised learning learns latent representations of the underlying data.

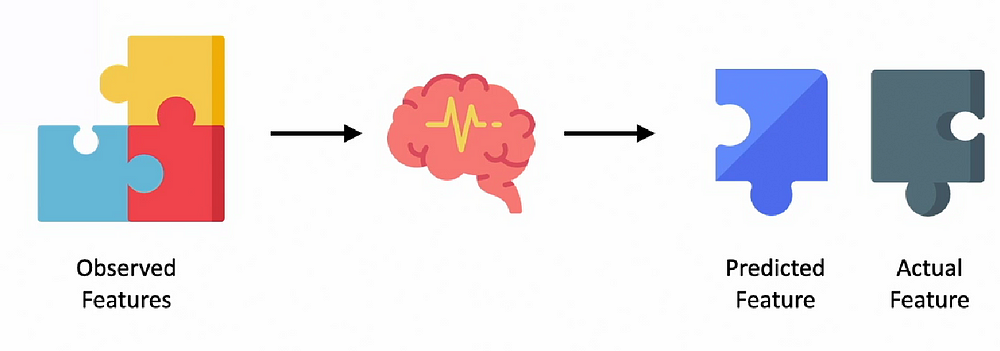
Thus self-supervised learning converts unlabeled data to labeled data by automating the process of generating labels.
We start off at some input that is known. We feed it into the self-supervised model. The self-supervised model then masks out or hides a part of the input and then trains itself to use to known portion of the input to try and predict the unknown or masked out portion.
So whatever the input is, the model looks at features it has available, the observed features and tries to predict the unknown feature using these observed features. The masked out portion will be available to us, that’s the actual feature, the predicted feature can be compared with the actual, we can set up some kind of loss function and use that to improve the prediction from our self-supervised model. Thus we automate data labeling will use supervised learning techniques starting with unlabeled data.
For example, in NLP, let’s say we have the entire sentence available in the raw form. And then we mask out a word and try and predict the word in the future from the words we have from the past sequence. Or we can use the same sentence, and mask out the word early in the sequence, and use the later words of the sequence to predict the missing word, to predict the past from the present.
How do these tasks actually help? This takes us to the core idea behind self-supervised learning.
A model that is trained to predict hidden features from observed features can learn generalized representations of the underlying data. And these generalized representations will then be useful in other downstream tasks.
Creating generalized representations are pretext tasks.
These representations on latent features can then be used in other downstream tasks, such as regression or classification. These latent representations actually capture important semantic information about the input, and this semantic information can be used in other tasks.
And we’ve been doing this forever when we’ve used word vector embeddings in NLP. If you’ve ever built and trained NLP models, you’ve likely used either Word2Vec or GloVe.
These are word vector embeddings where ….
….the embeddings capture the meaning and context of the individual words in the vocabulary.
Using these embeddings in our NLP tasks, whether it’s sentiment analysis, autocomplete, language translation, these embeddings greatly improve the performance of all of these NLP models, and that’s exactly the same idea that we are trying to capture with self-supervised learning.
Now, the pretext task in silo is of no use to us. Any pipeline that uses self-supervised learning usually has two kinds of tasks within the pipeline. There is the pretext task, and there is the downstream task.
Now, let’s talk about the downstream task first. That is more intuitive. That is the actual model that we want to build on our data. Whether it’s a regression model, or a classification model, or some other kind of model, it’s quite possible that we do not have enough labelled data to build the downstream model. So, we need a pretext task — that is the self-supervised learning model.
The pretext task is applied first to unlabeled data, and it’s used to learn good representations, or latent features of input data, that can then be used to improve the performance of the downstream task.
The weights of the self-supervised model that we’ve trained on huge amounts of unlabeled data can be used to improve the performance of our downstream taslks, So, self-supervised learning is often used with transfer learning.
In Transfer learning, we leverage models that have already been trained on a similar task. We repurpose and reuse a pre-trained model trained on one task as a starting point for a model on a different, but related task.
Note: Transfer learning only works where the source model, which we’re reusing, and our target model work on the same kind of problem.
So if the source model has been trained on some kind of image classification, the target model should also be some kind of image classification problem. We can’t take a language translation source model and use it for image classification.
MAKING TRANSFER LEARNING EFFICIENT WITH SELF-SUPERVISED LEARNING
Transfer learning can be made even more efficient and even more widespread if we can eliminate the ever threatening bottleneck of labelled data. And we can do this by using unsupervised learning.
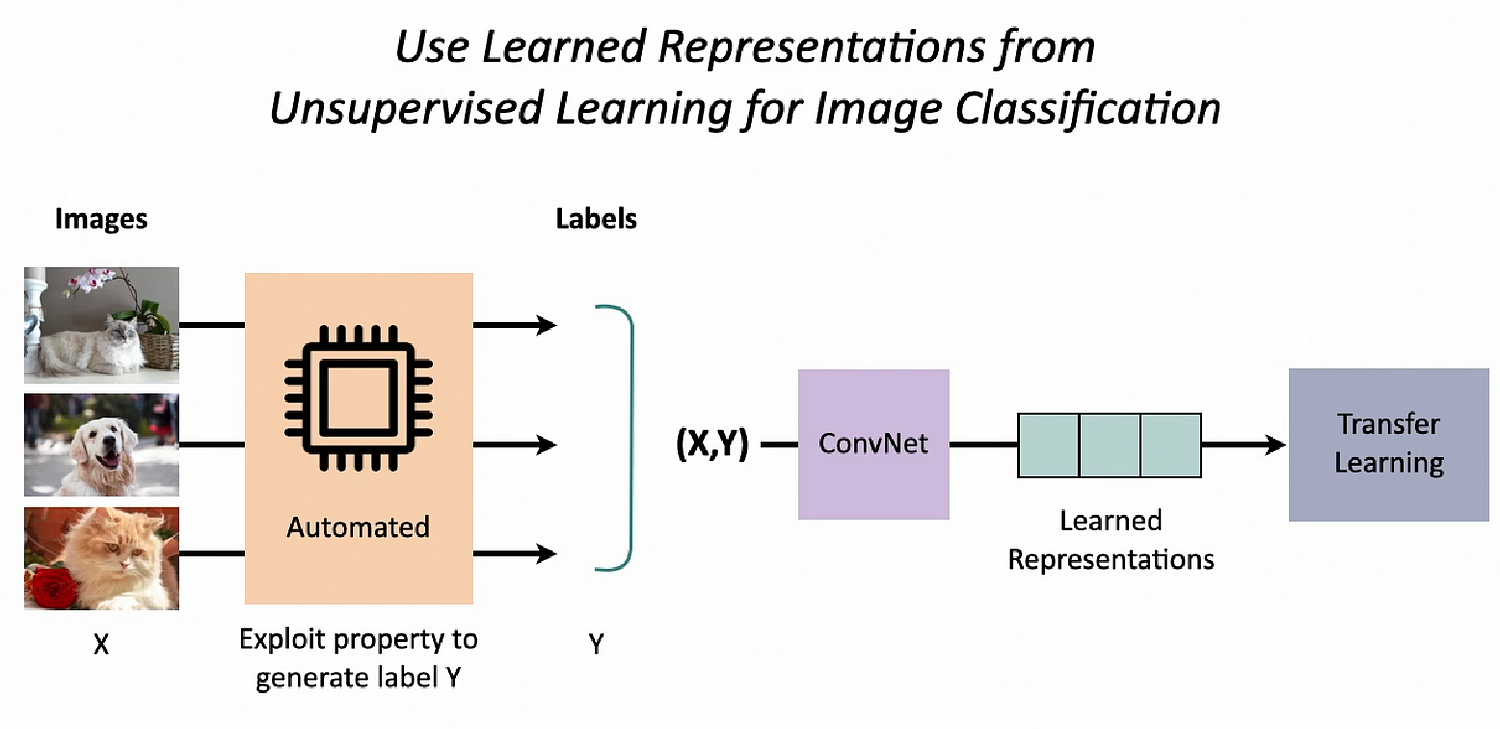
First we learn latent features in images. Then we use these learned representations from unsupervised learning in our image classification problem. That is our downstream task. This is how we could improve transfer learning.