

Fig 1. : AI – generation concept image of RAG Fusion
Before understanding RAG-FUSION , let’s try to understand what RAG is ?
RAG stands for Retrieval Augmented Generation. It is a very popular technique to give long permanent contexts to LLM to hallucinate less and give better and up-to-dateresponses.RAG consists of various components as shown in the below diagram.

Fig 2 : Workflow of Normal RAG
Let’s try to understand the above diagram using an example. Let’s say a user wants to ask a query “ What is the impact of climate change ? ”
This query will be converted into vectors using any embedding model. Few examples are shown in the diagram.Now here let’s take a break and understand the vectorDB part first. VectorDB are used to have permanent access to contexts for our LLM to help him answer the user questions. Let’s say we have a pdf report of climate impact on the world. We will save this pdf report in the vectorDB.We will break down the pdf into smaller chunks and then vectorize these chunks using any embedding model and then store these vector chunks in the vectorDB.
So, now we have vectorized chunks of our climate impact pdf report in vectorDB and also the user asked query’s vectorized form. Using this vectorized query , semantic search operation will be performed on the vectorDB to find the most relevant contexts to the query.These retrieved contexts , the user query and the pre established prompt will go as an input to our LLM and then the LLM will answer it and generate the appropriate response.
This is a normal flow of RAG. Now,how is RAG -FUSION different from this ? Let’s understand this via diagram.
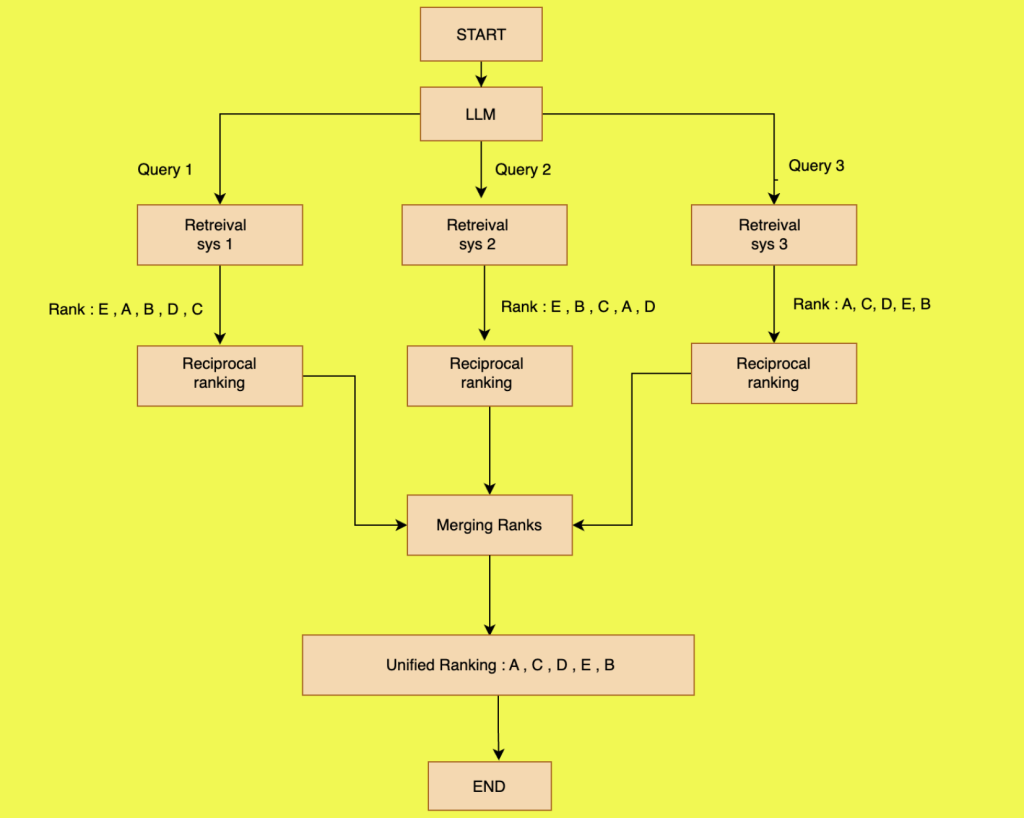
Fig 3 : Workflow of RAG – Fusion
In RAG FUSION , instead of one query , multiple queries are generated.As shown in the figure above,we have three queries generated.For each query , retrieval operation is performed and the results are ranked as per the similarity with the query. As we can see , we have ranking of the documents for each retrieval query.Then we need to merge these results together to give us our final rank.This merging is done using Reciprocal rank fusion algorithm.
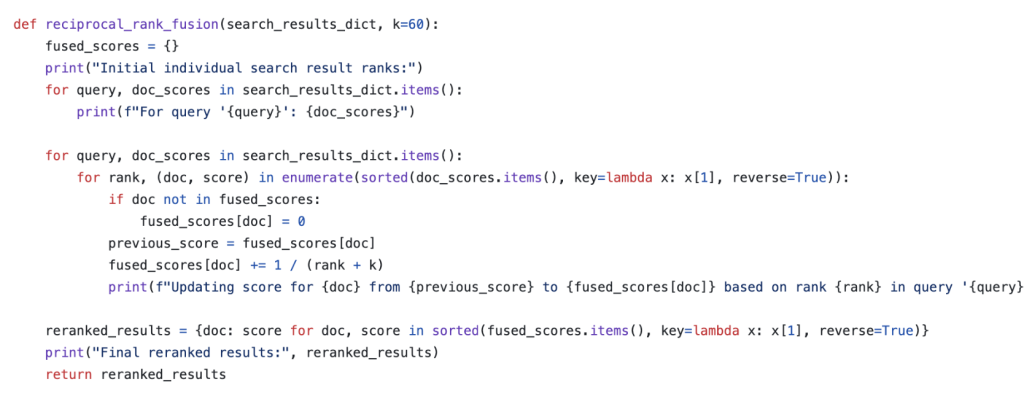
Fig 4 : Reciprocal Rank Fusion Algorithm
Here k is the number of words in the documents. You can refer this github link for the entire code implementation of RAG-FUSION concept.
Github : https://github.com/Raudaschl/rag-fusion
In this way we can capture the different information missed from multiple queries which could have missed via single query retrieval operation.
References :
Github : https://github.com/Raudaschl/rag-fusion
YouTube : https://www.youtube.com/watch?v=ldq05Dbfz9A&t=10s
Medium : https://towardsdatascience.com/forget-rag-the-future-is-rag-fusion-1147298d8ad1


