
New to LLMOps? Don’t worry — we’ve got you.
Welcome to this beginner-friendly guide to understanding LLMOps — what it is, why it matters, and how it helps manage powerful AI systems like ChatGPT, Claude, or LLaMA.
To make things easier (and a lot more fun), we’ll be explaining LLMOps using a simple analogy:
Running a restaurant.
Because honestly, managing large language models is a lot like managing a busy kitchen — and we’ll show you how.
Bonus: This blog also includes an animated diagram to help you visualize how everything fits together — from prompts to fine-tuning to deployment and beyond.
LLMOPS Explained with Analogy
Imagine you’re running a restaurant.
Not just any restaurant, but one where your chefs are incredibly skilled — capable of whipping up anything you ask for: custom desserts, fusion recipes, perfectly brewed coffee, or even molecular gastronomy experiments. These chefs are like Large Language Models (LLMs) — advanced AI systems like ChatGPT, Claude, or LLaMA that can generate everything from poems to emails, summaries, and even functional code.
But talent alone doesn’t guarantee smooth operations.
If your kitchen is disorganized…
–> Ingredients are hard to find
–> Orders are misunderstood
–> Mistakes happen repeatedly
–> Service slows down
–> And customers leave unhappy
This is exactly what happens when you run LLMs without the right operational processes in place. Enter LLMOps — the strategic and technical framework that ensures LLMs operate efficiently, reliably, and at scale.
MLOps vs. LLMOps
You may already be familiar with MLOps, short for Machine Learning Operations. MLOps provides the infrastructure and processes to
train, deploy, and maintain machine learning models like classifiers (e.g., spam detection, recommendation systems).
But LLMs are a different kind of beast.
They’re not just making binary decisions or numerical predictions. They’re generating content, simulating conversation, writing essays, summarizing documents, and more. They operate with natural language, and that introduces unique challenges — from prompt engineering and hallucinations to latency and context management.
Thus, LLMOps emerged as a specialization within MLOps — tailored specifically to the workflows and quirks of large-scale language models.
Architecture for LLMOps
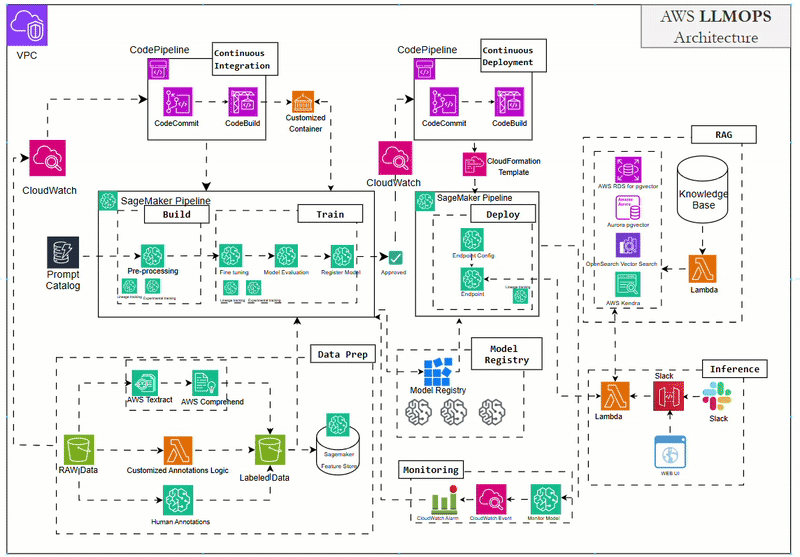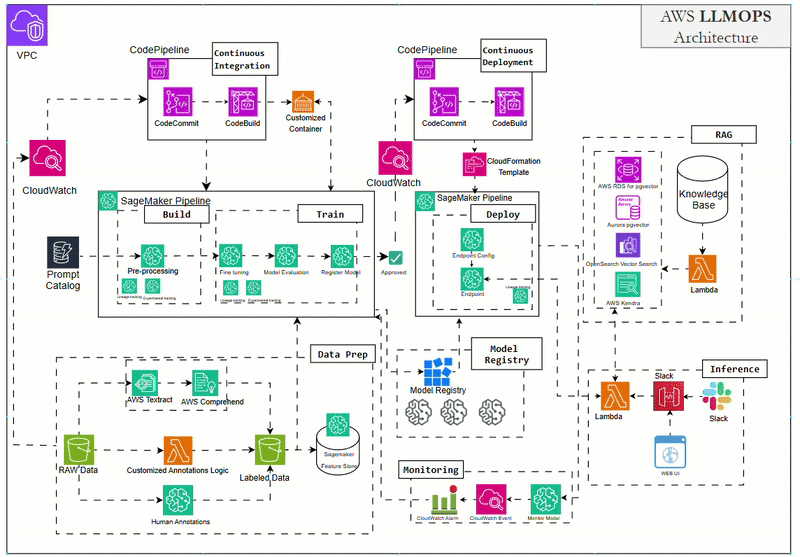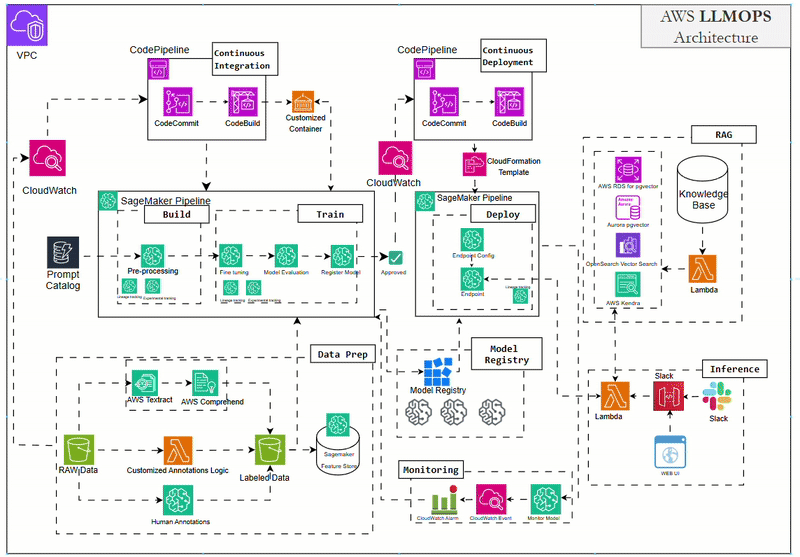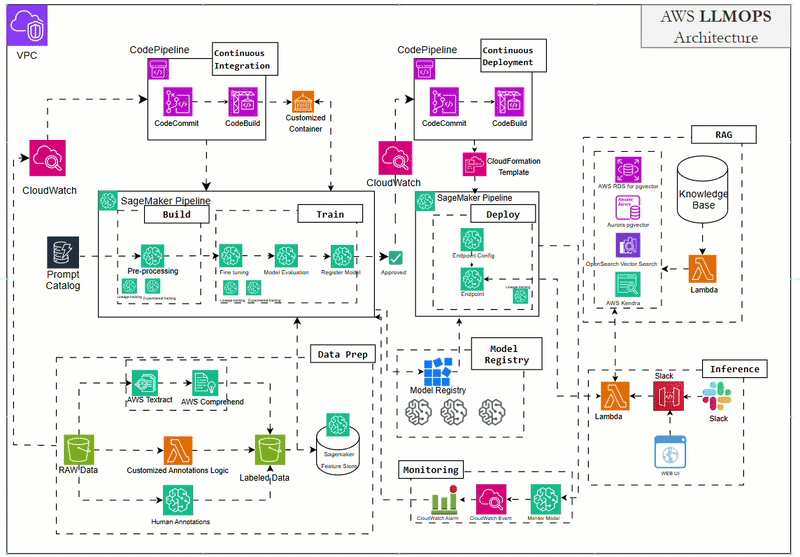
Restaurant Analogy for the Architecture
1. Prompt Management = Taking the Order Properly
In a restaurant, everything starts with a customer’s order.
“One spicy paneer tikka, medium spice, no onions, extra coriander.”
A good waiter records this correctly, communicates it clearly to the kitchen, and ensures the final dish reflects the customer’s request.
In the world of LLMs, the prompt is your customer order.
It’s the instruction you give to the model, and just like in the restaurant, the clarity of the prompt heavily influences the quality of the output.
With LLMOps, prompt management includes:
–> Prompt templates and libraries for reuse
–> Version control of prompts to experiment and iterate
–> A/B testing different prompt styles
–> Documentation and best practices
Imagine being able to say: “Last time we added a phrase about empathy, and the chatbot’s tone improved by 30%.” That’s what proper prompt management enables — data-driven creativity.
2. RAGOps = Access to the Right Ingredients
Even the best chef can’t make every dish from memory. Sometimes, they need to:
–> Check a recipe
–> Look up an ingredient
–> Grab items from the pantry
That’s where RAG (Retrieval-Augmented Generation) comes in.
It allows your LLM to fetch relevant information from external data sources — company wikis, product catalogs, CRM systems, databases, or policy documents — and use that to enhance its responses.
LLMOps in this layer ensures:
–> Indexed, organized document stores
–> Semantic search to match questions with relevant data
–> Real-time updates to reflect current knowledge
–> Feedback loops to improve relevance over time
This is critical for enterprise use cases where answers must be accurate and grounded in business-specific context — not just generic responses.
3. Fine-Tuning = Chef Specialization
Your chefs might be culinary school graduates — brilliant generalists.
But if your restaurant specializes in Gujarati cuisine, Japanese street food, or keto-friendly desserts, you’ll want to train them on your signature recipes.
That’s what fine-tuning is: taking a base model and adapting it to your domain, tone, and preferred outputs using specialized data.
LLMOps here handles:
–> Curating clean, relevant datasets
–> Running fine-tuning jobs safely and efficiently
–> Evaluating performance before and after fine-tuning
–> Managing multiple versions of the model
Fine-tuned models are like chefs who not only understand cooking, but understand your kitchen, your diners, and your expectations.
4. Deployment = Running Multiple Kitchens
Once your restaurant is successful, you open new locations — across cities or online platforms. You might serve dine-in customers, offer delivery, or sell frozen meal kits.
In AI, deployment is similar:
–> Your LLM could serve users in a chatbot on your website
–> Be embedded in a mobile app
–> Power internal tools or Slack bots
–> Generate daily reports via backend scripts
LLMOps takes care of:
–> Deployment pipelines with CI/CD
–> Configurations and infra setup for different environments
–> API endpoints and access control
–> Model rollbacks and version selection
The goal? Same quality, same consistency, no matter where the AI “meal” is served.
5. Monitoring = Quality Control & Feedback Loop
Great restaurants thrive on feedback:
–> Is the food too salty?
–> Are orders taking too long?
–> Did someone find a hair in their soup?
For LLMs, monitoring serves the same purpose:
Are outputs accurate and on-topic?
Is the latency acceptable?
Are responses safe and ethical?
Are users satisfied?
LLMOps enables:
–> Performance dashboards (latency, cost, usage)
–> Detection of hallucinations and toxic outputs
–> Human-in-the-loop (HITL) review workflows
–> Sentiment and behavior analytics
–> Feedback for continual learning and improvement
Without monitoring, things can spiral quickly — just like an unsupervised kitchen during a Saturday night dinner rush.
Enterprise Example: An AI Helpdesk Assistant
Imagine you’re deploying an internal AI assistant for employee support at a mid-size tech firm.
Here’s what LLMOps brings:
–> Prompt management: Templates for IT issues, HR questions, travel policies
–> RAG integration: Connects to Confluence and SharePoint to fetch company documents
–> Fine-tuning: Customized to respond in your internal tone and jargon
–> Deployment: Works via Slack bot, email interface, and internal dashboard
–>Monitoring: Tracks usage, identifies common failure points, and improves responses with human feedback
Without LLMOps, this assistant might seem smart at first — but quickly become unreliable, inconsistent, and even risky. With LLMOps, it scales as a trusted productivity tool.
Beyond the Tech: LLMOps as Strategy
It’s important to remember: LLMOps isn’t just a set of tools — it’s a mindset.
It encourages cross-functional collaboration between:
–> AI Engineers
–> Prompt Designers
–> Product Managers
–> DevOps
–> Legal and Compliance
–> UX and Content Writers
It helps align technical capability with real-world use cases, ensuring the AI adds value, not chaos.
LLMOps = Smart Kitchen Management
You wouldn’t run a Michelin-star restaurant without systems, staff, and workflows. So why treat your LLMs any differently?
LLMOps is your kitchen management layer for AI.
It ensures your models are:
–> Well-fed (with good data)
–> Well-trained (for your domain)
–> Well-monitored (for quality)
–> Well-behaved (for safety)
–> And well-deployed (for scale)
Whether you’re building customer support bots, content generation tools, document analyzers, or coding copilots — LLMOps is the glue that turns potential into production.
So next time your LLM whips up a brilliant response, remember: there’s a disciplined kitchen behind that creative genius.
Bon appétit, AI builders.

