


Image Captioning with ResNet and LSTM: A Powerful Deep Learning Approach
Image captioning is an exciting and complex task in the realm of artificial intelligence that combines computer vision and natural language processing. It involves generating a textual description for a given image, enabling machines to understand and interpret visual content in a way that is similar to human perception. In this blog, we will explore how to build an image captioning system using ResNet (Residual Networks) for feature extraction and LSTM (Long Short-Term Memory) for generating captions.
Understanding the Components
Before we dive into the implementation, it’s important to understand the two main components we’ll be using: ResNet and LSTM.
ResNet (Residual Network)
ResNet is a type of deep convolutional neural network (CNN) that has residual connections, which are designed to allow the network to learn effectively even as the number of layers increases. In simple terms, ResNet helps to avoid the problem of vanishing gradients, making it easier to train very deep networks. We will use ResNet as a feature extractor, converting images into a set of high-level features that the LSTM model can then interpret.
LSTM (Long Short-Term Memory)
LSTM is a specialized type of recurrent neural network (RNN) capable of learning long-term dependencies. Unlike traditional RNNs, LSTMs are designed to remember information for long durations, making them ideal for sequence-based tasks such as generating captions word-by-word. After extracting features from the image using ResNet, we’ll feed these features into an LSTM to generate a descriptive caption for the image.
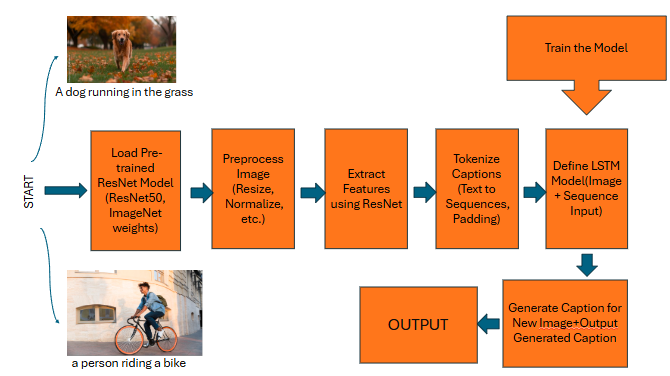
The Image Captioning Workflow
The process of image captioning can be broken down into a few steps:
Image Feature Extraction
First, we need to extract features from an image. For this, we use a pre-trained ResNet model. A popular choice is ResNet50, which is pre-trained on a large dataset like ImageNet. This allows us to leverage its knowledge of visual features without having to train a model from scratch.
Sequence Generation with LSTM
Once we have the image features, the next step is to generate a caption using the LSTM. The LSTM takes in the image features and learns the sequence of words that make up a caption. We’ll train the LSTM on a dataset that pairs images with their respective captions (e.g., Microsoft COCO dataset).
Putting it Together:
In the final step, we combine both the ResNet and LSTM to generate captions for new images.
Steps to Build Image Captioning Model
Now let’s walk through the steps to build an image captioning model using Keras with TensorFlow.
Step 1:- Load Pre-trained ResNet Model
We start by loading the pre-trained ResNet model, excluding the final classification layer, since we are interested only in the features learned by the model.
Python Code
import tensorflow as tf
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.preprocessing import image
import numpy as np>
# Load the ResNet50 model pre-trained on ImageNet
resnet_model = ResNet50(weights='imagenet', include_top=False, pooling='avg')
def preprocess_image(img_path):
img = image.load_img(img_path, target_size=(224, 224))
img_array = image.img_to_array(img)
img_array = np.expand_dims(img_array, axis=0)
img_array = tf.keras.applications.resnet50.preprocess_input(img_array)
return img_arrayStep 2:- Extract Features from Images
We will now use the pre-trained ResNet model to extract image features.
Python Code
def extract_features(img_path):
img = preprocess_image(img_path)
features = resnet_model.predict(img)
return featuresThis function loads an image, preprocesses it, and then passes it through the ResNet model to get the feature vector. These features will serve as the input for the LSTM model.
Step 3:- Prepare Data for LSTM
Next, we prepare a dataset that pairs image features with their corresponding captions. For simplicity, let’s assume we have a dataset ready. Each image will have a corresponding tokenized caption.
Python Code
# Dummy dataset (in practice, this should be a larger dataset)
image_paths = ['image1.jpg', 'image2.jpg']
captions = ['a dog in a field', 'a person riding a bike']
# Tokenization and preprocessing of captions
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
tokenizer = Tokenizer()
tokenizer.fit_on_texts(captions)
# Convert captions to sequences
captions_seq = tokenizer.texts_to_sequences(captions)
captions_seq = pad_sequences(captions_seq, padding='post')
Step 4:- Define the LSTM Model
Next, we define an LSTM model that takes the image features as input and generates a caption.
Python Code
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, LSTM, Embedding, Dense, Add # Define LSTM model architecture image_input = Input(shape=(resnet_model.output.shape[1],)) image_features = Dense(256, activation='relu')(image_input)
caption_input = Input(shape=(captions_seq.shape[1],))
caption_embedding = Embedding(input_dim=len(tokenizer.word_index) + 1, output_dim=256)(caption_input)
caption_lstm = LSTM(256)(caption_embedding)
merged = Add()([image_features, caption_lstm])
output = Dense(len(tokenizer.word_index) + 1, activation='softmax')(merged)
model = Model(inputs=[image_input, caption_input], outputs=output)
model.compile(loss='categorical_crossentropy', optimizer='adam')This architecture consists of two inputs: one for the image features (processed by ResNet) and one for the caption (in sequence form). The LSTM processes the caption sequence, and the image features are merged with the LSTM output to generate the final prediction.
Step 5:- Train the Model
The model is trained on the dataset, using the image features and captions.
Python Code
# Fit the model (using dummy data in this case)
model.fit([image_features, captions_seq], captions_seq, epochs=10, batch_size=32)
Step 6:- Generate Captions for New Images
Once the model is trained, you can generate captions for new images by feeding the extracted image features into the trained LSTM model.
Python Code
def generate_caption(image_path):
features = extract_features(image_path)
sequence = tokenizer.texts_to_sequences(["startseq"])
sequence = pad_sequences(sequence, maxlen=captions_seq.shape[1], padding='post')
caption = model.predict([features, sequence])
caption = np.argmax(caption, axis=1)
return ' '.join([tokenizer.index_word[i] for i in caption if i != 0])
# Generate caption for a new image
generate_caption('new_image.jpg')Conclusion
By combining ResNet and LSTM, we can create an image captioning model capable of generating meaningful textual descriptions for images. ResNet extracts high-level features from images, while LSTM generates the corresponding sequence of words to form a coherent caption.
While this example demonstrates the basics, real-world applications require a much larger dataset and more advanced techniques for training and optimization. However, this approach forms the foundation for building robust image captioning models that bridge the gap between computer vision and natural language processing.
By leveraging the power of pre-trained models like ResNet and LSTM’s capability for sequential learning, we can create models that not only understand visual data but also articulate it in human-readable form.



