


How Tungsten in Apache Spark Helps Tackle Big Data with Ease
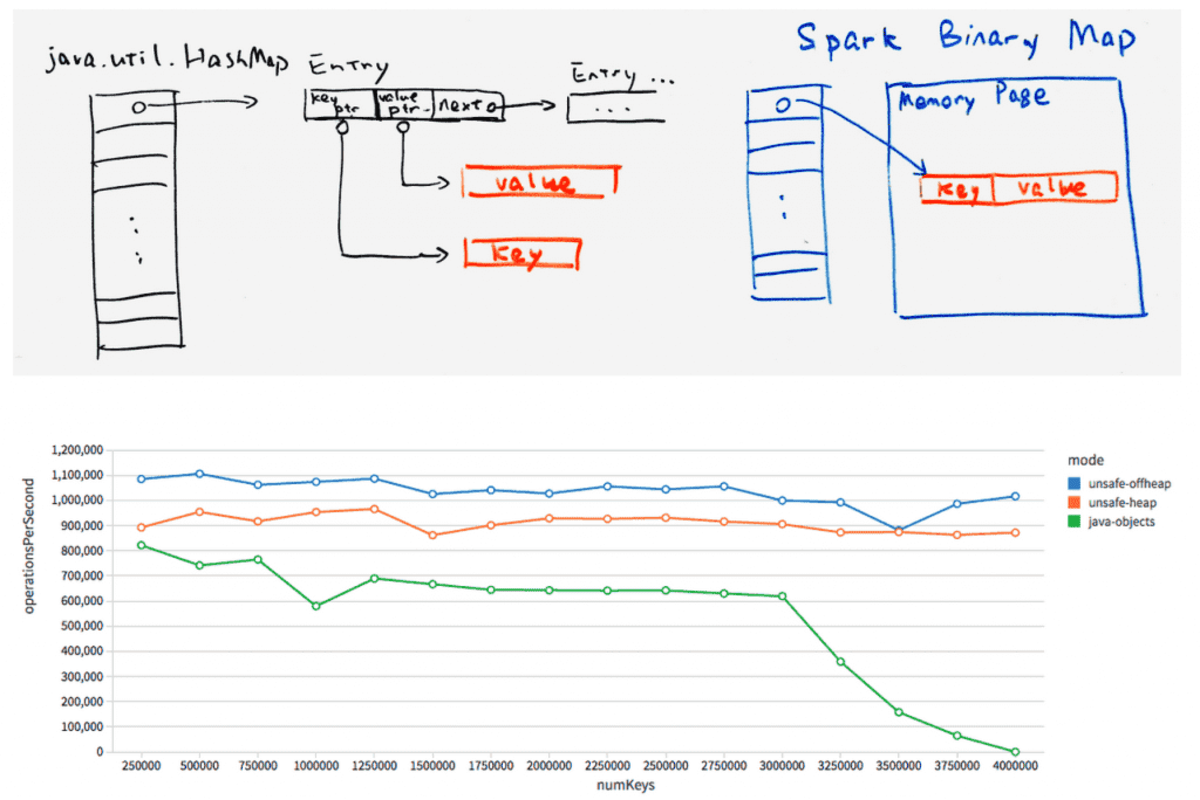
Tungsten is an advanced optimization framework introduced in Apache Spark 1.5 to significantly enhance performance. It focuses on improving memory management, boosting execution efficiency, and optimizing overall system performance. By targeting low-level memory control and leveraging code generation techniques, Tungsten helps reduce the performance challenges often faced in large-scale data processing.
Core Features of Tungsten Optimization in Spark:
1 Memory Management (Off- Heap)
- Uses binary formats and off-heap storage to minimize garbage collection overhead.
- Reduces reliance on Java objects by using direct memory buffers for efficient data handling.
2 Vectorized Processing for Performance
- Implements SIMD (Single Instruction Multiple Data) technique to process data in batches rather than row by row.
- Enhances the efficiency of operations such as aggregations and joins by leveraging columnar execution.
3 Enhanced Query Execution Plan
- Generates an optimized execution plan to improve performance and reduce computational overhead.
- Merges multiple Spark operations into a single optimized execution path, which results in reducing CPU-intensive calls.
4 Optimized Data Representation
- Uses custom memory layouts like UnsafeRow and Encoders to store data compactly.
- Eliminates Java serialization overhead by working with binary format.
5 Adaptive Query Execution (AQE) Support
- Spark 3.0, AQE (Adaptive Query Execution) further leverages Tungsten’s optimizations to adjust the execution plan dynamically based on the data properties at runtime.
- This makes Spark jobs more adaptable to data skew and improves performance when running on heterogeneous data sources
6 Physical Execution Engine
- Tungsten improves the physical execution engine in Spark by enabling more efficient code generation, reducing the overhead of interpreted code.
- Spark’s Catalyst optimizer, in combination with Tungsten, generates more optimized JVM bytecode for execution, leading to faster query execution.
Conclusion
Tungsten plays a crucial role in boosting Spark’s execution speed, often delivering performance improvements of up to 10 times in specific workloads. By optimizing memory usage, reducing CPU inefficiencies, and minimizing garbage collection, it helps Spark provide high-performance solutions for processing large datasets.




