How do RAG based Chatbots Work
Notes: For more articles on Generative AI, LLMs, RAG etc, one can visit the “Generative AI Series.”
For such library of articles on Medium by me, one can check: <GENERATIVE AI READLIST>
I thought it is an interesting topic to cover. So, I am dealing with it from a layman’s perspective who has some IT experience. The idea was to be as intuitive as possible. Though in the end, I have also added a famous framework ‘LangChain’ for the sake of completion.
Retrieval augmented generation is the process of supplementing a user’s input to a large language model with additional information that we have retrieved from somewhere else. The LLM can then use that information to augment the response that it generates.
It starts with a user’s question. The first thing that happens is the retrieval step. In it, we take the user’s question and search for the most relevant content from a knowledge base that might answer it. It is by far the most important, and most complex part of the RAG chain. Essentially it’s about pulling out the best chunks of relevant information related to the user’s query.
Now, we cannot send the knowledge base to the LLM. Models have built-in limits on how much text they can consume at a time (though these are quickly increasing). Another reason is cost. Sending huge amounts of text gets quite expensive. And there is evidence suggesting that sending small amounts of relevant information results in better answers.
Once we’ve gotten the relevant information out of our knowledge base, we send it, along with the user’s question, to the LLM, which then “reads” the provided information and answers the question. This is the augmented generation step.
PROMPT
Let’s start from the prompt level, because as I see it, we are augmenting the prompt with the retrieval step. So, let’s assume we already have the relevant information pulled from our knowledge base that we think answers the question. How do we use that to generate an answer?
We give the LLM custom instructions with the system prompt.
SYSTEM PROMPT
The first component is the system prompt. The system prompt gives the language model its guidance. For ChatGPT, the system prompt is something like “You are a helpful assistant.”
We use system prompt because we want the LLM to do something more specific. And, since it’s a language model, we can just tell it what we want it to do. Here’s an example short system prompt that gives the LLM more detailed instructions:
“You are a Knowledge Bot. You will be given the extracted parts of a knowledge base (labeled with DOCUMENT) and a question. Answer the question using information from the knowledge base.”
We’re basically saying, “Hey AI, we’re gonna give you some stuff to read. Read it and then answer our question, k? Thx.” And, because AIs are great at following our instructions, it kind of just… works.
KNOWLEDGE SOURCE
Then we give the LLM our specific knowledge sources. In essence we are just giving the AI its reading material. And again — the latest AIs are really good at just figuring stuff out. But, we can help it a bit with a bit of structure and formatting. Having some consistent formatting becomes important in more advanced use-cases, for example, if you want the LLM to cite its sources.
Once we’ve formatted the documents we just send it as a normal chat message to the LLM. Remember, in the system prompt we told it we were gonna give it some documents, and that’s all we’re doing here. Then we put everything together and ask the question.
Once we’ve got our system prompt and our “documents” message, we just send the user’s question to the LLM alongside them. Here’s how that looks in Python code, using the OpenAI ChatCompletion API:
openai_response = openai.ChatCompletion.create(
model=”gpt-3.5-turbo”,
messages=[
{
“role”: “system”,
“content”: get_system_prompt(), # the system prompt as per above
},
{
“role”: “system”,
“content”: get_sources_prompt(), # the formatted documents as per above
},
{
“role”: “user”,
“content”: user_question, # the question we want to answer
},
],
)
A custom system prompt, two messages, and we have context-specific answers!
Above is a simple use case, and it can be expanded and improved on. One thing we haven’t done is told the AI what to do if it can’t find an answer in the sources. We can add these instructions to the system prompt — typically either telling it to refuse to answer, or to use its general knowledge, depending on our bot’s desired behavior. We can also get the LLM to cite the specific sources it used to answer the question.
RETRIEVAL
Now let’s get back to the retrieval step.
The retrieval is about getting the right information out of the knowledge base. Now, above we assumed we had the right knowledge snippets to send to the LLM. But how do we actually get these from the user’s question? This is the retrieval step, and it is the core piece of infrastructure in any “chat with your data” system.
At its core, retrieval is a search operation.
We want to look up the most relevant information based on a user’s input. And just like search, there are two main pieces:
1. Indexing: Turning the knowledge base into something that can be searched/queried.
2. Querying: Pulling out the most relevant bits of knowledge from a search term.
Now, any search process could be used for retrieval. Anything that takes a user input and returns some results would work. So, for example, we could just try to find text that matches the user’s question and send that to the LLM, or we can Google the question and send the top results across — which, incidentally, is approximately how Bing’s chatbot works.
That said, most RAG systems today rely on semantic search, which uses another core piece of AI technology: embeddings. In an LLM’s world, any piece of human language can be represented as a vector of numbers. This vector of numbers is an embedding.
To get an idea of embeddings and vector stores, read the following. I am not populating the current article with additional information I have covered before: Embeddings Models and Vector Stores: Basics
Essentially, we find the best pieces of knowledge using embeddings.
With embeddings in mind, let’s construct a high-level picture of the retrieval step. On the indexing side, first we have to break up our knowledge base into chunks of text. This process is an entire optimization problem in and of itself. Once we’ve done that, we pass each knowledge snippet through the embedding machine and get back our embedding representation of that text. Then we save the snippet, along with the embedding in a vector database — a database that is optimized for working with vectors of numbers. Now we have a database with the embeddings of all our content in it. Conceptually, we can think of it as a plot of our entire knowledge base on our “language” graph.
Once we have this graph, on the query side, we do a similar process. First we get the embedding for the user’s input. The magic embedding machine thinks these are the most related answers to the question that was asked, so these are the snippets that we pull out to send to the LLM! In practice, this “what are the closest points” question is done via a query into our vector database. The query itself usually uses cosine distance, though there are other ways of computing it.
Onto LangChain
In our LangChain example from the beginning, we have now covered everything done by this single line of code. That little function call is hiding a whole lot of complexity!
index.query(“What should I work on?”)
INDEXING THE KNOWLEDGE BASE
Let’s understand how we create an initial index from our knowledge base. Perhaps surprisingly, indexing the knowledge base is usually the hardest and most important part of the whole thing. And unfortunately, it’s more art than science and involves lots of trial and error. Big picture, the indexing process comes down to two high-level steps.
1. Loading: Getting the contents of your knowledge base out of wherever it is normally stored.
2. Splitting: Splitting up the knowledge into snippet-sized chunks that work well with embedding searches.
Technically, the distinction between “loaders” and “splitters” is somewhat arbitrary. We can imagine a single component that does all the work at the same time, or break the loading stage into multiple sub-components.
That said, “loaders” and “splitters” are how it is done in LangChain, and they provide a useful abstraction on top of the underlying concepts.
LOADERS
Inside the loader a lot happens. We need to crawl all the pages, scrape each one’s content, and then format the files into usable text. There’s also parallelization, error handling, and so on to figure out. Again — this is a topic of nearly infinite complexity, but one that we mostly offload to a library when we use LangChain. Loader is like magic box where a “knowledge base” goes in, and individual “documents” come out. That makes built in loaders one of the most useful pieces of LangChain. They provide a long list of built-in loaders that can be used to extract content from anything from a Microsoft Word doc to an entire Notion site.
SPLITTERS
Coming out of the loader, we’ll have a collection of documents corresponding to each page in the documentation site. Also, ideally at this point the extra markup has been removed and just the underlying structure and text remains. Now, we could just pass these whole webpages to our embedding machine and use those as our knowledge snippets. But, each page might cover a lot of ground! And, the more content in the page, the more “unspecific” the embedding of that page becomes. This means that our “closeness” search algorithm may not work so well. What’s more likely is that the topic of a user’s question matches some piece of text inside the page. This is where splitting enters the picture.
With splitting, we take any single document, and split it up into bite-size, embeddable chunks, better-suited for searches. Once more, there’s an entire art to splitting up your documents, including how big to make the snippets on average (too big and they don’t match queries well, too small and they don’t have enough useful context to generate answers), how to split things up (usually by headings, if you have them), and so on. But — a few sensible defaults are good enough to start playing with and refining your data.
Splitters in LangChain
In LangChain, splitters fall under a larger category of things called “document transformers”. In addition to providing various strategies for splitting up documents, they also have tools for removing redundant content, translation, adding metadata, and so on. We only focus on splitters here as they represent the overwhelming majority of document transformations. Once we have the document snippets, we save them into our vector database. And we’re finally done!
Now, in LangChain, the entire indexing process is encapsulated in two lines of code. First we initialize our website loader and tell it what content we want to use:
loader = WebBaseLoader(“http://www.paulgraham.com/greatwork.html”)
Then we build the entire index from the loader and save it to our vector database:
index = VectorstoreIndexCreator().from_loaders([loader])
The loading, splitting, embedding, and saving is all happening behind the scenes.
RECAP
At last we can fully flesh out the entire RAG pipeline. Here’s how it looks: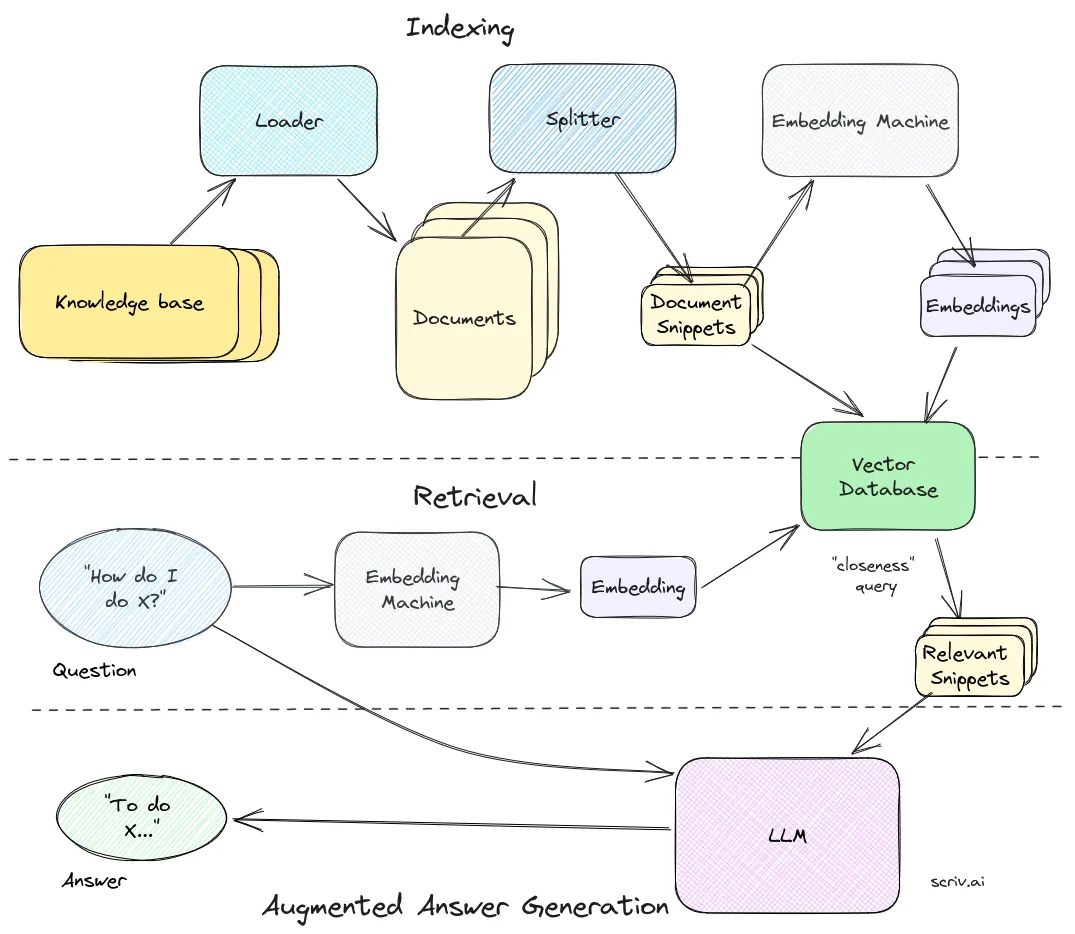
1. INDEXING — First we index our knowledge base. We get the knowledge and turn into individual documents using a loader, and then use a splitter to turn it into bite-size chunks or snippets. Once we have those, we pass them to our embedding machine, which turns them into vectors that can be used for semantic searching. We save these embeddings, alongside their text snippets in our vector database.
2. RETRIEVAL–Next comes retrieval. It starts with the question, which is then sent through the same embedding machine and passed into our vector database to determine the closest matched snippets, which we’ll use to answer the question.
3. GENERATION–Finally, augmented answer generation. We take the snippets of knowledge, format them alongside a custom system prompt and our question, and, finally, get our context-specific answer.