

Empowering Language Models to Reason and Act
PROMPTING
In in-context learning, we prompt language models to learn from examples.
RAG is an expansion of in-context learning in which we inject information retrieved from a documen-set into the prompt, thus allowing a language model to make inferences on never before seen information.
What we want the language model to do, we prompt it with a prompt. But a single prompt makes the language model hallucinate (it gives us a response that is fabricated for fluency in mind), even if it has now a context in the form of a knowledge source.
REASONING
The idea is to guide the language model to find the answers. That is, make it able to reason. That we do with the help of so-called agents.
An agent allows a language model to break a task into many steps, then execute those steps. One of the first big breakthroughs in this domain was “Chain of Thought Prompting” (proposed in this paper).
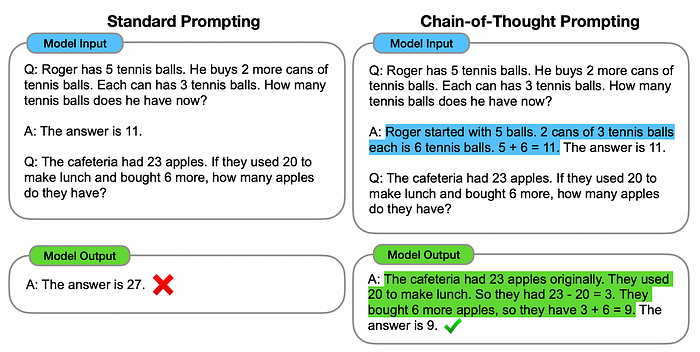
Chain of thought prompting is a form of in-context learning which uses examples of logical reasoning to teach a model how to “think through” a problem. In it, we give a model an example of how a human might break down a problem, and ask the model to answer a question with a similar process.
This is a subtle yet powerful method of prompt engineering that drastically improves their reasoning ability.
Language models use autoregressive generation to probabilistically generate output one word at a time. In a typical autoregressive process, GPT generates output token by token, considering the context provided by the earlier tokens. It allows the model to capture intricate patterns and dependencies in the input data.
But there is an issue. If the language model spits out an incorrect answer in the beginning, then it keeps on outputting information that justify the first answer. This is what hallucination is.
But by requesting a model to formulate a response using chain of thought, we’re asking the language model to fundamentally change the way it comes to conclusions about complex questions.
side: Now, we have an even more advanced prompting method called tree-of-thoughts prompting. Tree of Thought Prompting generates multiple lines of thought, resembling a decision tree, to explore different possibilities and ideas. Unlike traditional linear approaches, this technique allows the AI model to evaluate and pursue multiple paths simultaneously.
In any case, a problem still remains. What if we want to know something that language didn’t see during its training?
Then no amount of careful reasoning can help it.
So sometimes, reasoning is not enough. And we require ACTION.
ACTION
The idea is to empower language models to interface with tools that allow them to understand the world. Let’s briefly discuss the paper that originated tools.
SayCan
The “Do As I Can, Not As I Say” paper introduced “SayCan” architecture.
Imagine we are trying to use a language model to control a robot, and we ask the model to help clean a spilled drink. Most language models would suggest reasonable narratives. These naratives are great, but they present two big problems for controlling a robot:
- The responses have to correspond to something a robot is capable of doing. Without some sort of “call” function, a robot can’t call a cleaner.
- The response might be completely infeasible given the current environment the robot is in. A robot might have a vacuum cleaner attachment, but the robot might not be anywhere near the spill, and thus can’t use the vacuum cleaner to clean the spill.
To deal with these problems, the SayCan architecture uses two systems in parallel, commonly referred to as the “Say” and “Can” systems.
In a real-world setting, robots can only do a fixed number of operations. The “Say” System uses a language model to decide which of the various predefined operations (set in terms of probability collections in the model’s weights) is most likely to be appropriate. The most probable action is suggested by the ‘Say’ part.
A certain action might be linguistically reasonable, but might not be feasible for an agent like a robot.
For instance, a language model might say to “pick up an apple”, but if there’s no apple to pick up, then “find an apple” is a more reasonable action to take. the “Can” portion of the SayCan architecture is designed to deal with this issue.
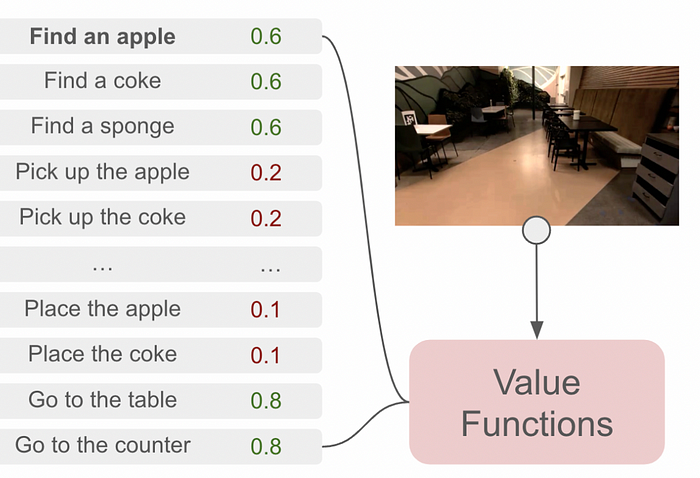
The SayCan architecture requires each possible action to be paired with a value function. The value function outputs a probability of an action being performed successfully, thus defining what a robot “Can” do.
In the above example, “pick up the apple” is unlikely to be successful, presumably because there is no apple in view of the robot. And thus “find an apple” is much more feasible.
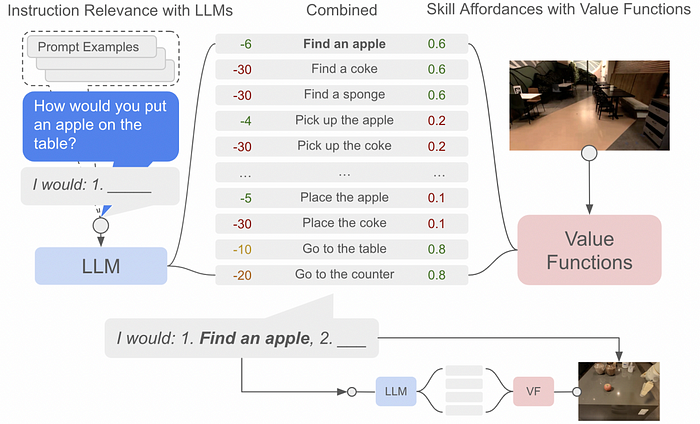
The SayCan architecture uses what a language model says is a relevant step, paired with what a value function deems possible, to choose the next step an agent should take. It repeats this process, over and over, until the given task is complete.
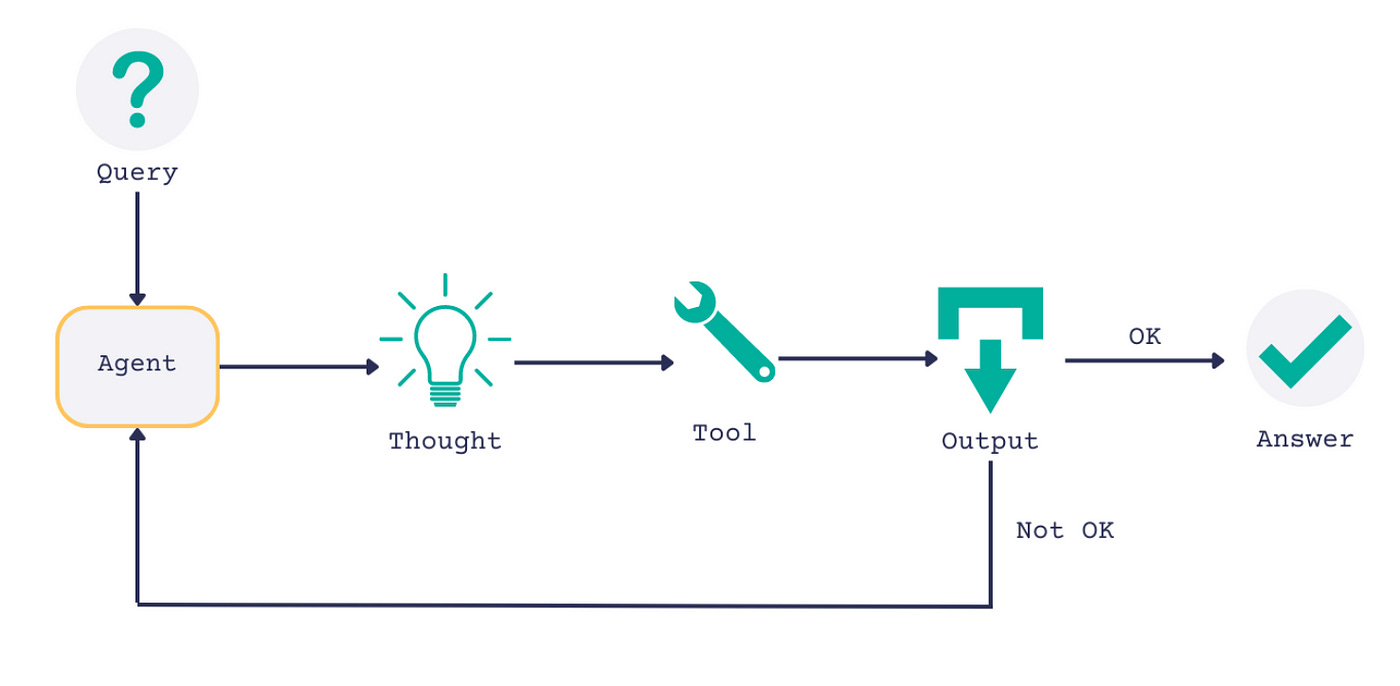
REASONING AND ACTING: ReAct AGENTS
The ReAct Agent framework, as proposed in ReAct: Synergizing Reasoning and Acting in Language Models, combines reasoning and acting agents in an attempt to create better agents that are capable of more complex tasks.
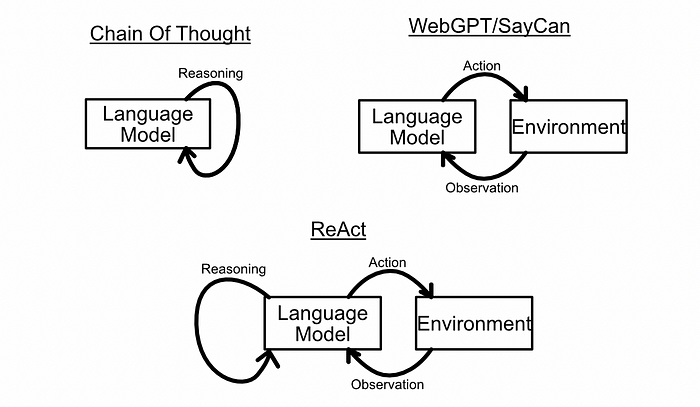
ReAct combines the reasoning concepts from Chain of Thought, action concepts from SayCan, and combines them into one wholistic system.
The idea is to provide a language model with a set of tools that allow that agent to take actions, then use in-context learning to encourage the model to use a chain of thought to reason about when and how those tools should be used.
By creating plans step by step, and using tools as necessary, ReAct agents can do some very complex tasks.
So, we just need three components:
- Context — with examples of how ReAct prompting should be done
- Tools — which the model can decide to use as necessary
- Parsing — which monitors the output of the model and triggers actions.
Tools: A Tool, from LangChain’s perspective, is a function that an agent can use to interact with the world in some way.
ReAct is a framework from an academic perspective. It’s not a straight-up, prescriptive set of steps, but rather a method of approach to promoting a language model.
As a result, when implementing ReAct, some aspects are left up to interpretation. For instance, one of the core ideas of ReAct is that actions, and the tools those actions trigger, might output a large amount of otherwise useless information.
It’s the job of “observations” to extract and distill relevant information, so as to not pollute the reasoning continuum of the agent.
Exactly how that gets done, though, is loosely defined.
Defining Context: To get the model to do what we want it to do, ReAct uses chain-of-thought prompting. By giving the model examples of working through problems, we can encourage the model to work through the model and use our tools.
ReAct has two states, the “working” state and the “act and observe” state. So provide context, we need two sets of examples for how the model should behave in each of these states.
When the agent is initialized, some important things happen.
- First, we set a state variable to help us keep track of if the agent “thought”, “acted”, or “observed”. We initialize the agent to “Question” at the beginning.
- Next, we define our contexts.To our context examples, we add a bit more by providing information about the tools, instruction to the model, and stuff like that.
In the working state (which is any time the model outputs anything other than an action), we can just ask the model to continue its current chain of thought.
When the working state prompt triggers an action (by the model outputting that it wants to perform an action), the act and observe function state takes the centerstage. It does a few things:
- It parses out the action. So it gets the tool name and the input to the tool. And executes it, based on the parsed-out input.
- It then constructs a context of “thought”, “action”, and “action result” which are relevant to the action, as well as examples of actions and observations from “action_observation_examples”, which we previously defined.
- Using that context, it asks the LLM to generate a prompt.
The resulting Observation gets added to the working context.
So, inconclusion every “step” in ReAct accounts for these two things —
- First, we decide whether to trigger a working prompt or act and observe, based on the most recent state of the agent
- Next we, update the state of the agent.





