
In the world of data science and analysis, the efficiency of data processing tools can significantly impact workflow productivity. This article examines the performance differences between three popular Python dataframe libraries – Pandas, Dask and Polars – focusing specifically on their CSV reading and writing capabilities.
Introduction
When working with large datasets, the time spent reading and writing data can become a bottleneck. Understanding which libraries perform best for these operations can help data analysts make informed decisions about their toolkit.
In this benchmark, I’ll evaluate:
- Pandas: The traditional workhorse of Python data analysis
- Dask: A parallel computing library that extends Pandas for larger-than-memory datasets
- Polars: A newer, Rust-powered dataframe library gaining popularity
Experimental Setup
Hardware and Software environment
The benchmarks were run on a standard development machine with the following specifications:
- CPU: Intel Core i5-8250U
- RAM: 16GB
- OS: Windows
- Python: 3.13.3
- Pandas: 2.2.3
- Dask: 2025.3.0
- Polars: 1.26.0
Test Data generation
To ensure a fair comparison, I generated a synthetic dataset with the following characteristics:
- Size: 10 million rows
- Columns:
- row_id: Sequential integers
- float_col: Random floating-point values
- int_col: Random integers (0 to 1,000,000)
- str_col: Random string values selected from lowercase characters
def generate_test_data(rows):
"""Generate random test data with specified number of rows"""
return pd.DataFrame({
'row_id': range(rows),
'float_col': np.random.randn(rows),
'int_col': np.random.randint(0, 1000000, rows),
'str_col': [''.join(random.choices(string.ascii_lowercase + string.ascii_uppercase, k=10)) for _ in range(rows)]
})Implementation Details
Library-specific approaches
Pandas implementation
# Writing
test_data.to_csv('pandas_data.csv', index=False)
# Reading
pd.read_csv('pandas_data.csv')Dask Implementation
# Writing
ddf = dd.from_pandas(test_data, npartitions=4)
ddf.to_csv(os.path.join(dask_output_dir, 'part-*.csv'), index=False)
# Reading
ddf = dd.read_csv(os.path.join(dask_output_dir, 'part-*.csv'))
len(ddf.compute()) # force computationPolars Implementation
# Writing
pl_df = pl.from_pandas(test_data)
pl_df.write_csv('polars_data.csv')
# Reading
pl.read_csv('polars_data.csv')Results Visualization
The benchmark generates three visualization charts:
- CSV writing performance comparison
- CSV reading performance comparison
- Combined reading and writing performance comparison
These charts provide a clear visual representation of the performance differences between the three libraries.
Results and Analysis
Note: The actual results will vary based on your specific hardware and software environment.
Sample Results
| Library | Write Time(s) | Read Time(s) |
| Pandas | 35.32 | 9.77 |
| Dask | 46.55 | 9.30 |
| Polars | 3.05 | 1.29 |
Performance Analysis
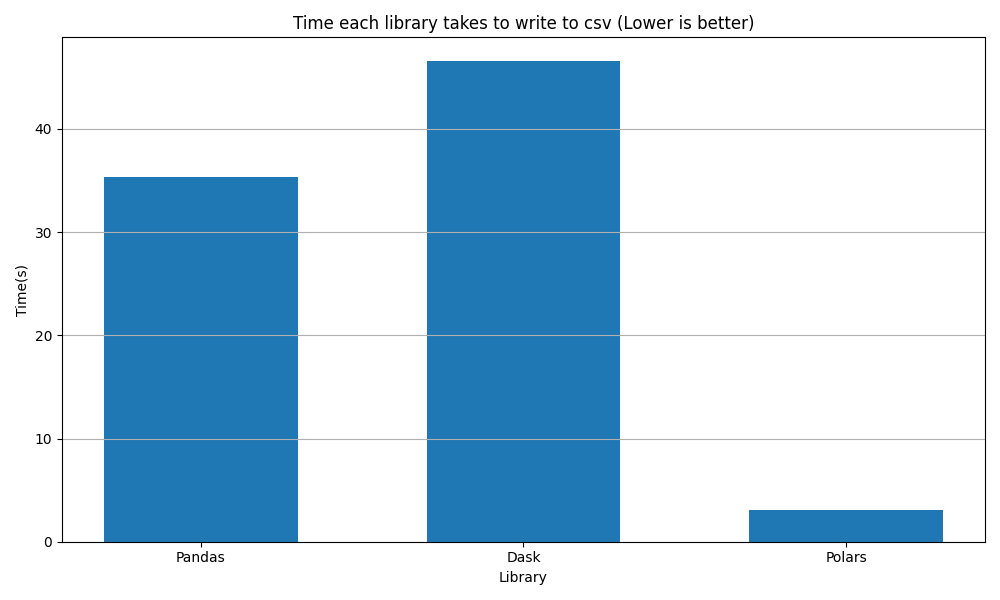
Experiment 1: Time taken to save to the CSV
The plot below depicts the time taken (in seconds) by Pandas, Dask, and Polars to generate a CSV file from a given Pandas DataFrame. The number of rows of CSV is 10 million.
Polars demonstrated the fastest CSV writing capabilities, outperforming Pandas. Dask showed slightly lower performance than Pandas, likely due to the overhead of partitioning.
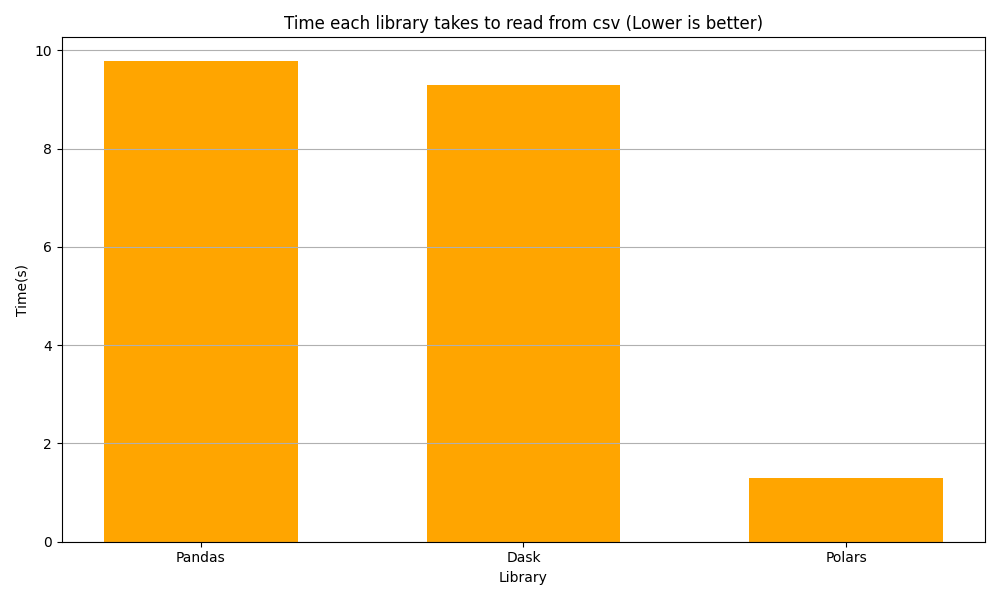
Experiment 2: Time taken to read the CSV
The bar chart below depicts the time taken (in seconds) by Pandas, Dask, and Polars to read a CSV file and generate a Pandas DataFrame. The number of rows of CSV is 10 million.
Polars again excelled in reading performance, showing faster reading times than Pandas. Dask showed a modest improvement over Pandas in reading operations.
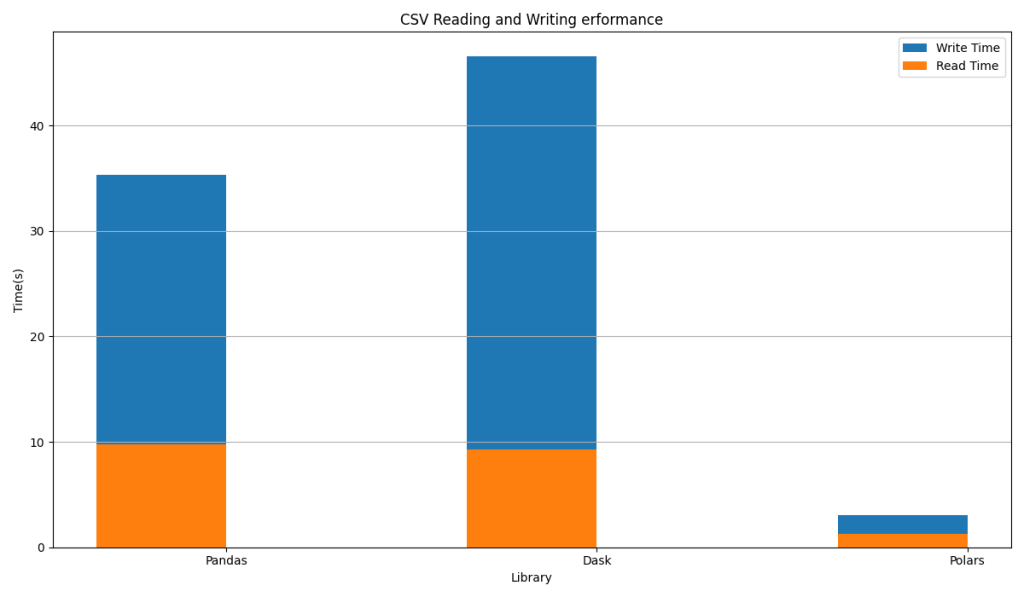
Combined chart
The bar chart below depicts the total time taken (in seconds) by Pandas, Dask, and Polars to read and write a CSV file. The number of rows is 10 million
Discussion
Key Takeaways
- Polars Dominance: Polars demonstrated superior performance in both reading and writing operations, highlighting the benefits of its Rust implementation and column-oriented design
- Dask’s Role: While Dask didn’t outperform Polars, its ability to handle larger-than-memory datasets makes it valuable for big data scenarios where performance isn’t the only consideration
- Pandas Reliability: Despite not being the fastest, Pandas remains a solid choice for many workflows due to its extensive ecosystem and feature set
When to choose each library
- Choose Pandas when working with smaller datasets and when compatibility with the broader data science ecosystem is important
- Choose Polars when performance is critical and datasets fits in memory
- Choose Dask when performing with datasets larger than available memory or when distributed computing is needed
Conclusion
The choice of DataFrame library can significantly impact the efficiency of data processing pipelines. While Polars demonstrated impressive performance advantages in this benchmark, the best choice depends on specific use cases and requirements.
For I/O-intensive workflows with datasets that fit in memory. Polars appears to be the clear performance winner. For larger-than-memory datasets, Dask offers a good balance of functionality and speed. Pandas remain the versatile standard with the richest ecosystem, despite not being the fastest option.


