
In the world of artificial intelligence, the development of advanced reasoning models is pushing the boundaries of what machines can achieve. One such breakthrough comes in the form of DeepSeek-R1, a model that stands out for its innovative use of Reinforcement Learning (RL), Chain-of-Thought (CoT) reasoning, and a multi-stage training process. By sidestepping traditional methods of training with labeled data, DeepSeek has managed to develop a powerful model capable of tackling complex reasoning tasks—opening up a new frontier in AI development. In this post, we’ll explore what makes DeepSeek-R1 so unique and why it could be a game-changer for future AI systems.
Reinforcement Learning at the Core of DeepSeek-R1
At its heart, DeepSeek-R1 leverages Reinforcement Learning (RL), an approach that enables models to improve through interaction with their environment. In RL, a model takes actions, receives feedback in the form of rewards or penalties, and uses that feedback to refine its behavior over time. This trial-and-error learning process allows DeepSeek-R1 to enhance its reasoning skills without requiring large, labeled datasets.
Unlike traditional supervised learning, where a model is trained on pre-labeled data, RL eliminates the need for manually curated datasets. Instead, the model learns from its own decisions and adjusts accordingly. In the case of DeepSeek-R1, this means the model learns to reason step by step, improving its output over successive iterations.
Chain-of-Thought Reasoning: A Key to Superior Performance
One of the standout features of DeepSeek-R1 is its ability to use Chain-of-Thought (CoT) reasoning during inference. CoT involves breaking down complex problems into smaller, more manageable steps, allowing the model to arrive at a logical conclusion. This step-by-step process mirrors human reasoning and is crucial for tackling tasks that require multi-step problem-solving.
However, to make CoT work effectively during inference, the model must first be trained with RL methods that encourage step-by-step thinking. This training enables DeepSeek-R1 to generate both reasoning steps and final answers, providing transparency and insight into how it arrived at its conclusions.
This synergy between RL and CoT reasoning is what sets DeepSeek-R1 apart from many other models, enabling it to perform complex reasoning tasks with greater clarity and precision.
The Journey to DeepSeek-R1-Zero: A Bold Experiment in Pure RL
The journey to creating DeepSeek-R1 began with DeepSeek-R1-Zero, a model trained exclusively with pure RL. The objective was to explore whether it’s possible to train a high-performance reasoning model without relying on any labeled data at all. This approach posed a challenge, as training typically requires labeled examples to guide the learning process. But by focusing solely on RL, the team sought to prove that a model could still develop sophisticated reasoning abilities by learning through its own actions and feedback.
DeepSeek-R1-Zero achieved impressive results, even matching OpenAI’s o1 model in performance on benchmarks like the AIME 2024 mathematics competition. However, the model did encounter challenges, particularly with issues like poor readability and language mixing, which are common in RL-based models without structured data.
From R1-Zero to DeepSeek-R1: Overcoming Challenges with Multi-Stage Training
The next phase of the development process brought DeepSeek-R1 into the spotlight, addressing the shortcomings of R1-Zero. By employing a multi-stage training process, the model was able to refine its reasoning capabilities and fix issues like poor readability. The multi-stage training process consisted of five key phases:

Cold-Start Data Fine-Tuning
The first step involved fine-tuning the model on a small dataset of cold-start data, which provided a foundation for improving readability and overall structure. While this dataset was small, it helped improve the model’s initial output quality.
Pure RL Training
Similar to R1-Zero, the next phase used pure RL to improve the model’s reasoning capabilities. This training enabled DeepSeek-R1 to refine its ability to think logically and solve complex tasks without relying on labeled data.
Rejection Sampling and Synthetic Data Generation
As the model neared convergence, rejection sampling was used to generate synthetic data from the model’s previous successful outputs. This allowed the model to select high-quality responses, improving its accuracy and consistency over time.Supervised Data Merging
The next step involved merging the synthetic data with supervised data from the base model, DeepSeek-V3-Base. This diverse set of training data, including domains like writing, Q&A, and self-cognition, helped refine the model’s ability to handle various tasks more effectively.
Final RL Refinement
In the final stage, the model underwent another round of RL, allowing it to generalize its knowledge across a wider range of tasks and prompts. This ensured the model could perform well across diverse real-world scenarios.
This multi-step approach proved highly effective, and DeepSeek-R1 emerged as a far more refined model compared to its predecessor, R1-Zero.
A Unique API Experience: How to Use DeepSeek-R1
For those eager to test out DeepSeek-R1, it’s available via a convenient API. The API allows you to send queries to the model and receive both the reasoning steps and the final answer. Unlike some models that provide just the final output, DeepSeek-R1 reveals the underlying thought process, providing transparency and insight into how the model reached its conclusions.
For instance, here’s a quick example of how you can interact with DeepSeek-R1 through its API:
from openai import OpenAI
client = OpenAI(api_key="<DeepSeek API Key>", base_url="https://api.deepseek.com")
# Round 1: Asking a question
messages = [{"role": "user", "content": "Which is greater, 9.11 or 9.8?"}]
response = client.chat.completions.create(
model="deepseek-reasoner",
messages=messages
)
reasoning_content = response.choices[0].message.reasoning_content
content = response.choices[0].message.content
# Round 2: Continuing the reasoning
messages.append({'role': 'assistant', 'content': content})
messages.append({'role': 'user', 'content': "How many Rs are in the word 'strawberry'?"})
response = client.chat.completions.create(
model="deepseek-reasoner",
messages=messages
)
This API is incredibly versatile, but keep in mind that while it offers great reasoning capabilities, it currently doesn’t support certain parameters like temperature or logprobs, which may limit its use in production environments.
Power of Smaller Models: Distilling Reasoning
Another key takeaway from the DeepSeek research is the ability to distill reasoning patterns from larger models into smaller ones. Smaller models, such as the 14B version, have been shown to outperform larger models in certain reasoning tasks by leveraging the reasoning patterns discovered in larger models. This distillation process allows smaller models to take advantage of the complex learning from bigger systems without the overhead of scaling up.
For example, the distilled 14B model outperformed the QwQ-32B model, and even the 32B and 70B models achieved new benchmarks in reasoning tasks. This process demonstrates how smaller models can still offer powerful performance without needing to rely on massive datasets or excessive computational resources.
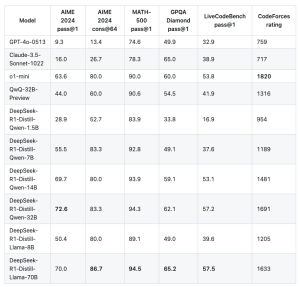
Comparison of DeepSeek-R1 distilled models with other similar models on reasoning-based benchmarks(https://www.vellum.ai/blog/the-training-of-deepseek-r1-and-ways-to-use-it )
Looking Ahead: The Future of AI Reasoning
The success of DeepSeek-R1 represents a major milestone in the development of reasoning AI. By combining pure RL, Chain-of-Thought reasoning, and multi-stage training, DeepSeek has shown that it’s possible to create reasoning models that are faster, more efficient, and scalable.
What’s even more exciting is the potential for future models to take this approach even further, building on the lessons learned from DeepSeek-R1. We can expect a new wave of models capable of solving increasingly complex tasks with greater accuracy and efficiency.
In conclusion, DeepSeek-R1 is a game-changing model that sets the stage for the next generation of reasoning systems. With its unique blend of RL, CoT, and innovative training techniques, DeepSeek is proving that the future of AI reasoning is here—and it’s just getting started.

