
Spark is currently a backbone tool for processing large datasets and it is said to be lightning-fast for large scale data processing. Because it saves and load data from distributed system over a cluster machines. We all know the importance of optimizing the Spark execution plan, and we all know how difficult it to achieve the best workflow. Recently I got a chance to work on an ETL pipeline project where we wrote many pySpark jobs and deployed it on EMR. In our journey we encountered some performance issues and fixed them out accordingly. So in this article, I will be sharing few Spark optimization tips , best practices, and multiple performance tuning methodologies.
A quick Spark Recall
Apache Spark is a data processing framework that can quickly perform processing tasks on very large data sets, and can also distribute data processing tasks across multiple computers, either on its own or in tandem with other distributed computing tools. It provides an interface for programming entire clusters with implicit data parallelism and fault tolerance and stores intermediate result in memory(RAM and DISK).
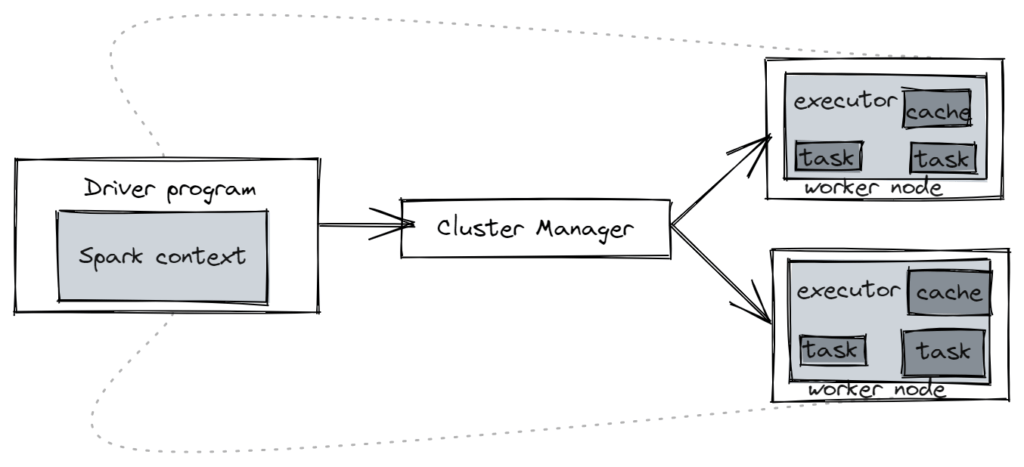
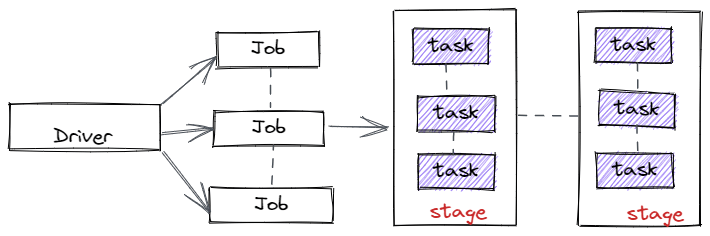
Most of the spark source code is written in Scala. However, spark offers API’s in Python,Java,R and SQL. A spark job is a sequence of stages that are composed of tasks, it can be represented by a Directed Acyclic Graph(DAG).
Lazy Evaluation in Sparks means, Spark will not start the execution of the process until an ACTION is called. This allows spark to prepare a logical and physical execution plan to perform the action effectively.
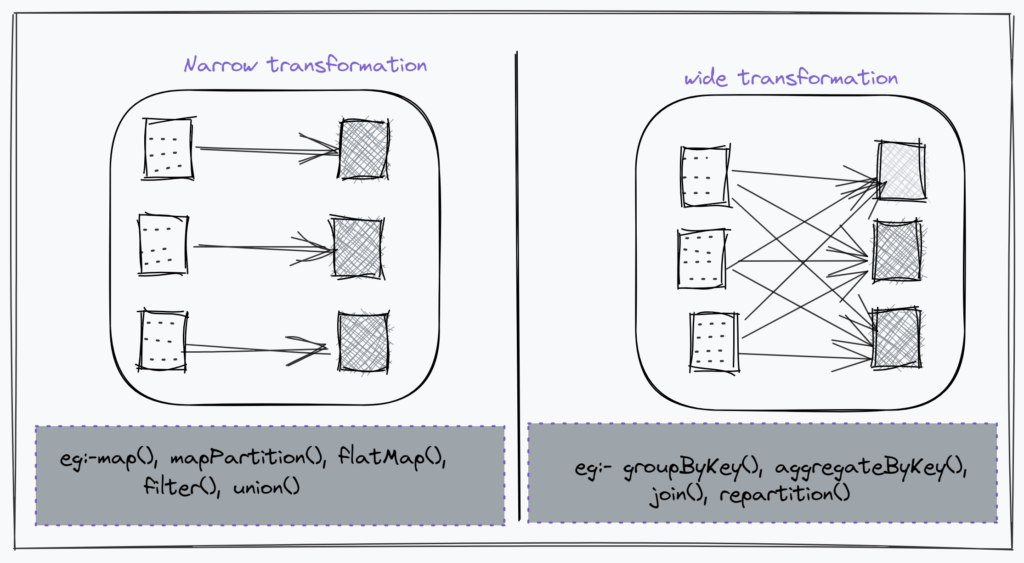
Wide and Narrow transformation
Transformations are the core of how you will be expressing your business logic using Spark. There are two types of transformations ; these are specifying narrow dependencies and wide dependencies. Narrow Transformations consisting of narrow dependencies, where each input partition will contribute to one output partition. Wide Transformation will have input partitions contributing to many output partitions. You will often hear this referred to as a shuffle where Spark will exchange partitions across the cluster. Along with narrow transformations, Spark will automatically perform an operation called pipelining on narrow dependencies, this means that if we specify multiple filters on DataFrames they’ll all be performed in-memory. The same cannot be said for shuffles. When we perform a shuffle, Spark will write the results to disk.
Optimization Tips
Filter the data at the earliest
One of the most effective and simplest technique, that we can apply in the data processing are as below;
- column level filtering :- Selecting only the required columns for processing
- Row level filtering:– Filtering out the data that are not needed for further processing
File format selection
File format plays a major role in processing time, as the reading and writing time is also counted as part of this process. Hence we have to choose the file format based on the use case
- Parquet:- Parquet is a columnar format, It consumes less space and it support compression like snappy, gzip. But reading record from a parquet is a expensive operation and writing to a parquet file takes more time as compared to other file formats.
- Avro:- Avro has a schema based system and it have two components
- Binary data : Data is stored in binary format and serialized the data avro schema
- Avro schema : Json formatted string/file used to serialize and deserialize the data
- CSV/TSV/Delimited file : Data stored in tabular format and its human-readable which contain column information as header. But this required more storage space, also the implementation of structured and array data types are slightly difficult as there are poor support for special characters.
- Json/XML : These are semi-structured data represented in key-value pairs. Json is widely used since it uses less memory as compared to XML. Json supports complex data structures. Handling data in Json is simple, since Json parser is available in almost all major programming languages.
API Selection
Spark has 3 types of API to work upon data we should choose the right API by observing the data
- RDD (Resilient distributive dataset) : It will be useful for the low-level computations and operations. There will not be any default optimization provided by spark. Hence we have to implement the logic very precisely and optimize the code as our own.
- Data Frame : Data frames looks similar to a SQL table or 2 dimensions array capable of storing complex data types. It is the best choice when we have to deal with tabular data. It uses catalyst optimizer that has a process for optimization.

3. Data Set : Data sets are highly type-safe and it uses the encoder as part of their serialization. We needs to define a schema before using the data, at the time of data reading/ transformation we will not face any issue with datatypes. It requires less memory as compared to data frames. Use cases in which we have to stick to a schema and do not want to generate schema at the time of reading, we should go for datasets.
Spark Advanced Variables
Spark provides two advanced variables: Accumulator and Broadcast variable
- Accumulator Variables : Accumulators are used for sharing operations on a variable on all executors, such as implementing counters or aggregating functions. These variables are defined and assigned initial values on the Driver side. The accumulator can only read the last value on the driver side and update it on the executor side after the action is triggered.
- Broadcast variables : Read-only variable and it is broadcasted to all the executors. These variables are cached in each node in the cluster, instead of being passed to each task a copy. This can only be defined/modified on the Driver side, not on the executor. This help to make our data set (small) available in each node. Broadcast join used to join two tables in which one table is smaller and it can be fit in the memory of each node, this will make the join operation faster as compared to Sort-merge Join.
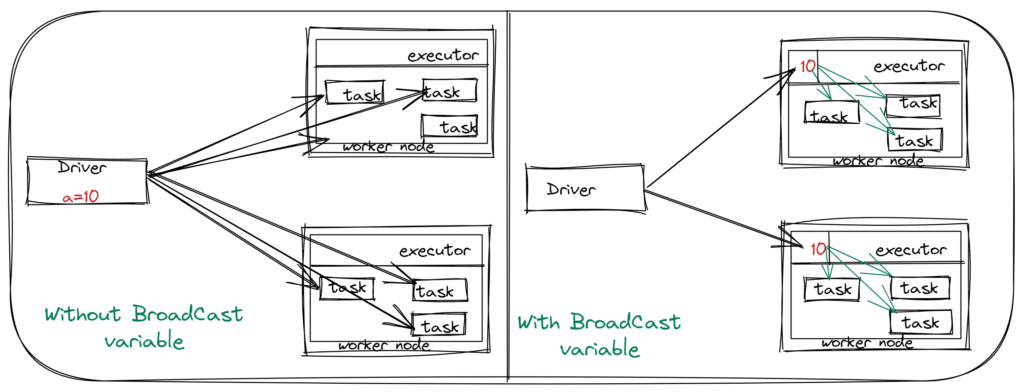
Maximize parallelism
Optimizing a spark job often means reading and processing as much data as possible in parallel and to achieve this we have to split a dataset into multiple partitions. When we submit a job it creates an operator graph. When we call on action, this operator graph is submitted to DAG scheduler and it divides the operator into various task stages. These stages will be passed on to the task scheduler. Through the cluster manager the tasks are executed on worker nodes. when we increase the partitions in our code, the Parallelism at the executor level increases but at the same time the executor passes result to driver node. Then the driver nodes needs to combine all the results which again takes time, which can impact the overall timing of execution.
Spark organizes one thread per task and per CPU core. All cores should be occupied most of the time during the execution of spark job. If one of them available at anytime, it should be able to process a job associated with a remaining partition.
Partitions can be created :
- When reading the data by setting the spark.sql.files.maxPartiotionBytes parameter
- Increasing the number of partitions may leads to the small file problem.
- In the Spark application code using the dataframe API
- Coalesce
- Repartition
- Coalesce decreases the number of partition while avoiding a shuffle in network.
Data Serialization
When we work on any type on computation, the data gets get converted into bytes and get transferred over the network. Serialization help to convert the objects into stream of bytes. If the data transferred in the network is less , the tame taken for the job execution would be less. PySpark supports custom serializers for transferring data; this can improve performance.
By default, PySpark uses PickleSerializer to serialize objects using Python’s cPickle serializer, which can serialize nearly any Python object. Other serializers, like MarshalSerializer, support fewer datatypes but can be faster.
Saving the intermediate results [Caching and persistence]
Spark uses Lazy Evaluation and a DAG to describe the job. Every time an action is called, all the process would be called in and the data would be processed from the start. To save time we can save the intermediate results on memory/Disk.
- Cache : Will store as many of the partitions read in memory across spark executors as memory allows
- Persistence : It gives control over how your data is cached via Storage level
- List of storage options are available here
Minimize shuffle
There is a specific type of partition in spark called as Shuffle partition, it created during the stages of a job involving shuffling. Spark shuffle is an expensive operation since it involves the following
- Disk I/O
- Involves data serialization and deserialization
- Network I/O
The value of the spark.sql.shuffle.partitions can be modified to control the number of partitions (default is 200). This parameter should be adjusted according to the size of the data.
formula for the best result is
spark.sql.shuffle.partitions= ([shuffle stage input size / target size]/total cores) * total cores
In spark 3.0, the AQE framework is shipped with 3 features
- Dynamically coalescing shuffle partitions
- Dynamically switching join strategies
- Dynamically optimizing skew joins
AQE can be enabled by setting SQL config spark.sql.adaptive.enabled to True and spark.sql.adaptive.coalescePartitions.enabled set as True then the shuffle partition can be updated by spark dynamically. We can adjust spark.sql.adaptive.advisoryPartitionSizeInBytes for better results.
Tackle Skew Data
When one partition has more data to process as compared to others it result into performance bottleneck due to this even distribution of data. AQE automatically balances the skewness across the partitions. Other two separate ways to handle skew in data as follows:
- Salting : Adding randomization to the data to help it to be distributed more uniformly.
- Repartition : It does a full shuffle, creates new partitions and increases the level of parallelism in the application.
Setting up limit for broadcast Join
The default value is set to 10MB. we can increase it by setting up spark.sql.autoBroadcastJoinThreshold
Compressing data
- It helps to prevent the out of memory issue.
- Compress data at the time of execution
This can be done enabled by setting spark.sql.inMemoryColumnarStorage.compressed to True
Memory and resource allocation
The most important thing is to allocate only the required amount of memory and cores to the application.
Avoid using UDF’s
Try to avoid UDF functions at any cost and use when existing Spark built-in functions are not available to use.
UDF’s de-serialize each row to object, apply the lambda functions and re-serialize it resulting in slower execution and more garbage collection time.
Conclusion
In this article,we have seen how “Spark helps in processing data”. We also learned about how to optimize the execution time and few best practices that you can accommodate in your project. I hope, this would be helpful for you while working on Spark. You can also suggest and add best practice to improve the performance. Feedback is always appreciated !
Thanks for reading 🙂

