GraphQL is not just a query language, it’s a paradigm shift in how we think about APIs and data management
Introduction
So back in 2012, Facebook was having trouble with their mobile app. It was slow and didn’t work well on weak internet connections. They were using a type of technology called REST API, but it wasn’t working well for them.
So they came up with a new idea called GraphQL. It’s a special way of asking for information from a server. Instead of getting a bunch of information all at once, GraphQL lets the app ask for only the specific information it needs at that moment. This makes the app faster and more efficient, especially on weak internet connections.
Think of it like asking a waiter for your order at a restaurant. Instead of getting a whole menu, you can just ask for the specific food you want to eat right now. This way, you don’t waste time looking at things you don’t want, and the waiter can bring you your food faster!

here is another example :
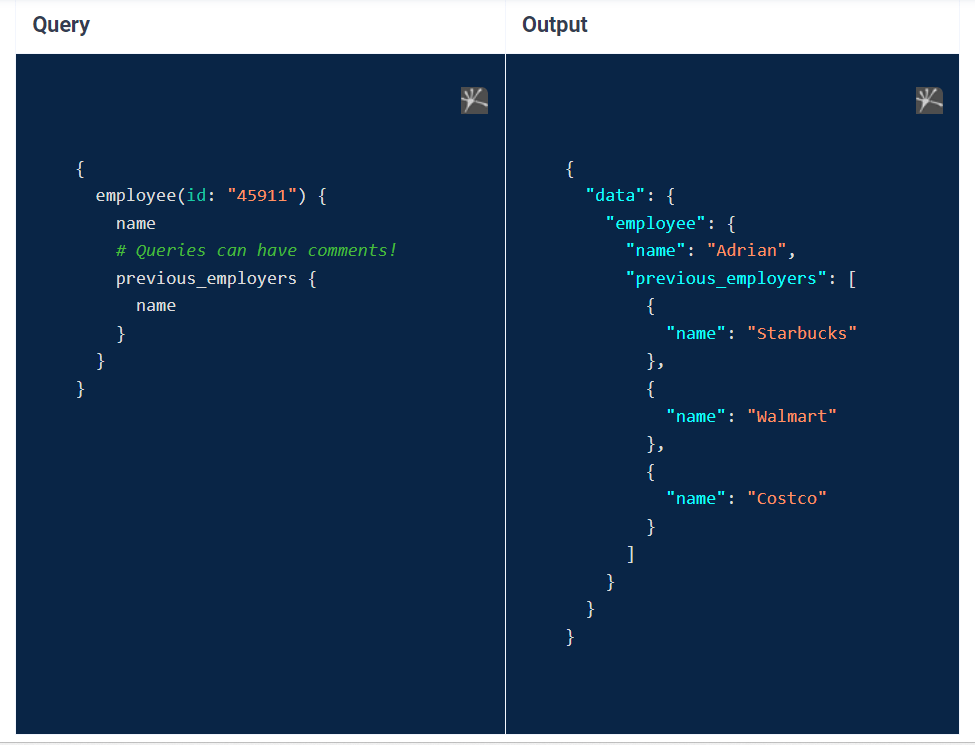
As you can see, the above query and the result have the same form. Using GraphQL queries enables the server to know what the client has asked for. It also returns only the fields specifically requested.
How does GraphQL work?
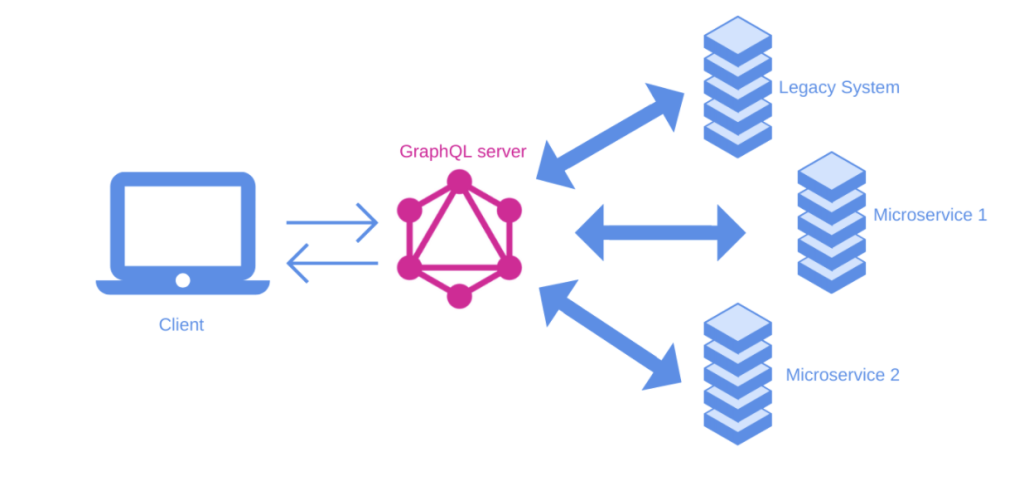
With GraphQL, you don’t need to know all the technical details about how the different sources work or where the data is stored. You just tell GraphQL what you want, and it figures out how to get it for you.
To help make this process easier, GraphQL uses something called Schema Definition Language (SDL). SDL is like a map that tells GraphQL where to find the information you want. By using SDL, GraphQL knows exactly what you’re looking for and can give you just the data you need, making your app faster and more efficient.
Why is GraphQL replacing Rest API ?
Improved efficiency
Increased Efficiency: With REST APIs, clients receive all the data defined by the server, even if they don’t need all of it. In contrast, GraphQL allows clients to request only the data they need, making the application more efficient and reducing the amount of data transferred over the network.
Reduced over-fetching and under-fetching
By specifying exactly what data is needed, GraphQL reduces the problem of over-fetching (receiving more data than necessary) and under-fetching (not receiving enough data to fully populate the client).
Increased flexibility
With GraphQL, clients can request multiple resources in a single request, and the server can respond with the exact data the client needs, regardless of where it is stored.
Better developer experience
The GraphQL API is strongly typed, meaning that developers can easily understand and interact with the API using tools like GraphQL playgrounds and code editors.
Simplified versioning
Because clients can specify the exact data they need, changes to the API schema can be made without breaking existing clients.
A built in playground/UI to explore and invoke the API
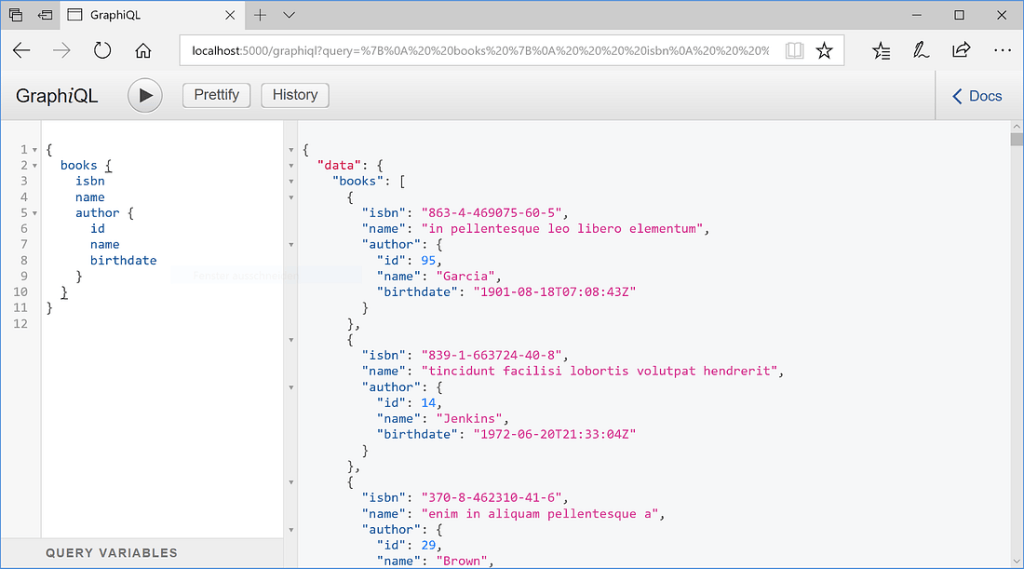
As you can see above even before designing and implementing their user interfaces, front-end engineers can explore and test the backend APIs they need using this interface: A very powerful collaboration mechanism for the team.
| Feature | REST | GRAPHQL |
| Querying data | URL-based queries and parameters | Schema-based queries and fields |
| Response format | Pre-defined data structures | Dynamic response based on query |
| Request flexibility | Limited to pre-defined endpoints | Flexible, can request any data |
| Over-fetching | Can return more data than needed | Requests only needed data |
| Under-fetching | May require multiple requests | Can retrieve multiple resources |
| Versioning | May require versioning of endpoints | Can add fields without breaking clients |
| Client-side complexity | May require multiple API calls and data filtering | Can simplify client requests and data retrieval |
| Caching | Can be easily cached using HTTP caching | Requires a custom caching layer |
| Real-time updates | Requires polling or WebSockets | Supports real-time updates via subscriptions |
Overall, GraphQL can help reduce complexity and improve efficiency in building and consuming APIs, making it a powerful tool for modern application development.
Conclusion
In conclusion, GraphQL is a query language and runtime API that has gained popularity in recent years due to its advantages over traditional REST APIs.
As a result, GraphQL has become a preferred method for building APIs, especially for applications with complex data requirements, mobile applications, and microservices architectures. While REST APIs are still widely used, it’s clear that GraphQL offers a more flexible, efficient, and developer-friendly alternative that is quickly gaining traction in the software development community.
Here are some links to help you getting started and get a deeper insight on GraphQl
https://graphql.org/learn/ (Official documentation)
https://www.howtographql.com/basics/1-graphql-is-the-better-rest/ (Deeper dive on tooling, environment, security etc Frontend/backend)
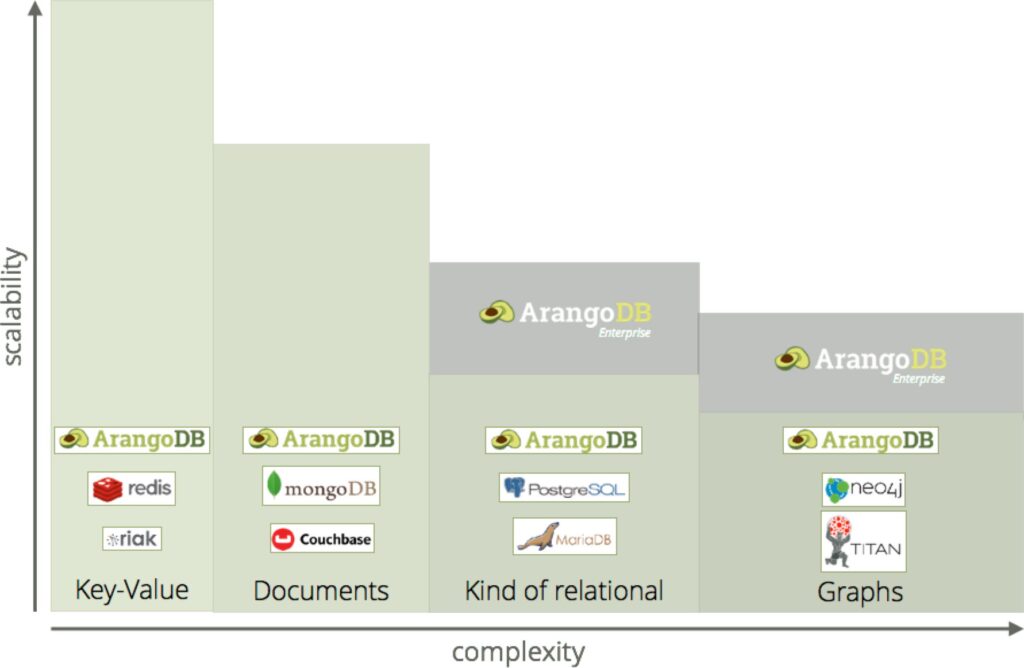
Key Difference :-
| Name | Amazon Neptune | ArangoDB | Cassandra | Microsoft Azure Cosmos DB | Neo4j |
| Description | Fast, reliable graph database built for the cloud | Native multi-model DBMS for graph, document, key/value and search. All in one engine and accessible with one query language. | Wide-column store based on ideas of BigTable and DynamoDB | Globally distributed, horizontally scalable, multi-model database service | Scalable, ACID-compliant graph database designed with a high-performance distributed cluster architecture, available in self-hosted and cloud offerings |
| Primary database model | Graph DBMS RDF store | Document store Graph DBMS Key-value store Search engine | Wide column store | Document store Graph DBMS Key-value store Wide column store | Graph DBMS |
| Cloud-based only | yes | no | no | yes | no |
| DBaaS offerings | ArangoDB Oasis –The Managed Cloud Service of ArangoDB. Oasis provides fully managed, and monitored cluster deployments of any size, with enterprise-grade security. Get started for free and continue for as little as $0,21/hour. | • Aiven for Apache Cassandra: Fully managed, open source NoSQL database specifically designed to be highly available, performant, and scalable. Astra DB: Multi-cloud DBaaS built on Apache Cassandra. | Neo4j Aura: Neo4j’s fully managed cloud service: The zero-admin, always-on graph database for cloud developers. | ||
| Implementation language | C++ | Java | Java, Scala | ||
| Server operating systems | hosted | Linux OS X Windows | BSD Linux OS X Windows | hosted | Linux OS X Solaris Windows |
| Data scheme | schema-free | schema-free | schema-free | schema-free | schema-free and schema-optional |
| SQL | no | no | SQL-like SELECT, DML and DDL statements (CQL) | SQL-like query language | no |
| APIs and other access methods | RDF 1.1 / SPARQL 1.1 TinkerPop Gremlin 3.3 | AQL Foxx Framework Graph API (Gremlin) GraphQL query language HTTP API Java & SpringData JSON style queries VelocyPack/VelocyStream | Proprietary protocol Thrift | DocumentDB API Graph API (Gremlin) MongoDB API RESTful HTTP API Table API | Bolt protocol Cypher query language Java API Neo4j-OGM RESTful HTTP API Spring Data Neo4j TinkerPop 3 |
| Supported programming languages | C# Go Java JavaScript PHP Python Ruby Scala | C# C++ Clojure Elixir Go Java JavaScript (Node.js) PHP Python R Rust | C# C++ Clojure Erlang Go Haskell Java JavaScript Perl PHP Python Ruby Scala | .Net C# Java JavaScript JavaScript (Node.js) MongoDB client drivers written for various programming languages Python | .Net Clojure Elixir Go Groovy Haskell Java JavaScript Perl PHP Python Ruby Scala |
| Server-side scripts | no | JavaScript | no | JavaScript | yes |
| Triggers | no | no | yes | JavaScript | yes |
| Partitioning methods | none | Sharding | Sharding | Sharding | yes using Neo4j Fabric |
| Replication methods | Multi-availability zones high availability, asynchronous replication for up to 15 read replicas | Source-replica replication with configurable replication factor | selectable replication factor | yes | Causal Clustering using Raft protocol |
| MapReduce | no | no | yes | with Hadoop integration | no |
| Consistency concepts | Immediate Consistency | Eventual Consistency Immediate Consistency OneShard (highly available, fault-tolerant deployment mode with ACID semantics) | Eventual Consistency Immediate Consistency | Bounded Staleness Consistent Prefix Eventual Consistency Immediate Consistency Session Consistency | Causal and Eventual Consistency configurable in Causal Cluster setup Immediate Consistency in stand-alone mode |
| Foreign keys | yes | yes | no | no | yes |
| Transaction concepts | ACID | ACID | no | Multi-item ACID transactions with snapshot isolation within a partition | ACID |
| Concurrency | yes | yes | yes | yes | yes |
| Durability | yes | yes | yes | yes | yes |
| In-memory capabilities | no | ||||
| User concepts | Access rights for users and roles can be defined via the AWS Identity and Access Management (IAM) | yes | Access rights for users can be defined per object | Access rights can be defined down to the item level | Users, roles and permissions. Pluggable authentication with supported standards (LDAP, Active Directory, Kerberos) |
What you can’t do with MongoDB
- Multi-model: MongoDB is a single-model document database. It does not support any other data models. If your application requires a graph or key/value store, you would have to use a second database technology to support it. Being multi-model, ArangoDB allows you to not only use one database for both, but run ad-hoc queries on data stored in different models.
- Joins: Using and scaling joins over different collections and instances is not supported by MongoDB (scalability depends on the use case).
- Declarative Query Language: MongoDB uses JSON syntax for queries. It does not support a declarative query language. By contrast, ArangoDB developed its own SQL-like query language (AQL) for complex queries, allowing the combination of access patterns in a single query
- Complex Transactions: Use complex transactions to span multiple documents and collections, or to run aggregations. Complete Isolation in the cluster available
- Extensibility: Additionally, ArangoDB allows you to use existing or run your own data-centric microservices in a dedicated JavaScript framework: Foxx.
ArangoDB is cluster ready for document, key/value and even for graph-models. With ArangoDB 3.x releases further improvements are being made for performant cluster usage with graphs.
ArangoDB is perfectly suitable for high-availability, high-performance or any other use case a document store might be challenged with.
By reducing development effort and enabling data-model flexibility, ArangoDB is designed for fast development and easy scaling. With the Foxx Microservices Framework, you can build production-ready session services within minutes.
What you can’t do with Neo4j
ArangoDB offers the same functionality as Neo4j with more than competitive performance, plus several additional features:
- Multi-Model: Neo4j is a single-model graph database. It does not support any other data models. If your application requires a document or key/value store, you would have to use a second database technology to support it. Being multi-model, ArangoDB allows you to not only use one database for everything,but run ad hoc queries on data stored in different models.
- Scalability: Scaling graph collections over many instances is technically a hard task. But with ArangoDB it is possible to minimize the network-hop problem and run queries highly efficient even against distributed graph data. Neo4j does not support this.
- Extensibility:Use existing data-centric microservices or run your own in a dedicated JavaScript framework within ArangoDB, providing a single API call for complex graph traversals.
- Performance: In ArangoDB you can use the same collection for a graph and for a document query without performance losses. ArangoDB showed competitive or even better performance.
- Operational costs: ArangoDB can be used for a broad range of use cases and reduces the number of storage products in your technology stack.
Scalability needs and ArangoDB
ArangoDB is cluster ready for graphs, documents and key/values. ArangoDB is suitable for e.g. recommendation engines, personalization, Knowledge Graphs or other graph-related use cases. ArangoDB provides special features for scale-up (Vertex-centric indices) and scale-out (SmartGraphs).
What you can’t do with Cassandra
- Multi-model: Cassandra is a partitioned row-store database. It does not support any other data model. If your application requires a graph or key/value store, you would have to use a second database technology like Titan or DataStax Enterprise Graph to support graphs, thereby adding complexity and costs. Being native multi-model, ArangoDB allows you to use one database for both and also run queries efficiently on data stored in different models.
- Unified Query Language: ArangoDB Query Language (AQL) supports all three data models (k/v, document, graph) with their respective data access patterns (Projections, Joins, Traversals, more). In addition, querying special data types like text or geo-spatial is natively supported by AQL. All data models and data types can be freely combined in a single AQL query. To do the same in Cassandra, one would have to learn CQL and Gremlin for graphs.
- Joins: Also various join operations are supported natively in AQL. ArangoDB even supports join operations at scale with the Satellite Collection feature. With Cassandra, these operations are not possible natively and have to be done client-side with all its security and performance impacts.
- Complex Transactions: Cassandra does not support ACID transactions. With ArangoDB, developers can use complex transactions to span multiple documents and collections, or to run aggregations. ArangoDB supports multi-document & multi-collection transactions (single instance; single document transactions in cluster setting).
- Scalability needs and ArangoDB: ArangoDB is cluster-ready for each model and multi-model usage. Unlimited scale-up capabilities thanks to C++ core balanced with scale-out. ArangoDB cluster architecture supporting independent scaling for serving high read/writes volumes and data storage, if needed.
- Extensibility: Use existing data-centric microservices or run your own in a dedicated JavaScript framework Foxx within ArangoDB, providing e.g. a single API call for complex graph traversals.
- Lower TCO: Knowing a multi-model database means applying the same knowledge to diverse use cases and lets developers move much faster. ArangoDB can be used for a broad range of different use cases with native multi-model approach and thereby simplify the needed tech stack and operational footprint.
SQL / AQL – Comparison
The ArangoDB Query Language (AQL) is similar to the Structured Query Language (SQL) in its purpose. Both support reading and modifying collection data, however AQL does not support data definition operations, such as creating and dropping databases, collections and indexes.
Though some of the keywords overlap, AQL syntax differs from SQL. For instance, the SQL WHERE and AQL FILTER clauses are equivalent in that they both define conditions for returning results. But, SQL uses predefined sequence to determine where the WHERE clause must occur in the statement. In AQL, clauses execute from left to right, so the position of a FILTER clause in the query determines its precedence.
Despite such differences, anyone with an SQL background should have no difficulty in learning AQL. If you run into any problems, we have a table below showing SQL functions and commands with their AQL equivalents.Comparing Relational DBs to multi-model ArangoDB. Get the White Paper
Below is a table with the terms of both systems.
| SQL | AQL |
| database | database |
| table | collection |
| row | document |
| column | attribute |
| table joins | collection joins |
| primary key | primary key (automatically present on _key attribute) |
| index | index |
What is GraphQL
A Spec that describes a declarative query language that your client can use to ask an API for the exact data they need. and it’s done by creating a strongly typed schema for your API.
It provides ultimate flexibility in how your API can resolve data and client queries validated against your schema.
The Problems that are solved by GraphQL for An API Developer at the Server Side Are :
The GraphQL Solving the following problems :
- Over-Fetching
- Under-Fetching
What Is Over-Fetching :
In REST API unlike GraphQL We have to pass the GET request to multiple endpoints to get the data that we need. and it’s a fixed data structure that returns more files of data than the data that we exactly need.
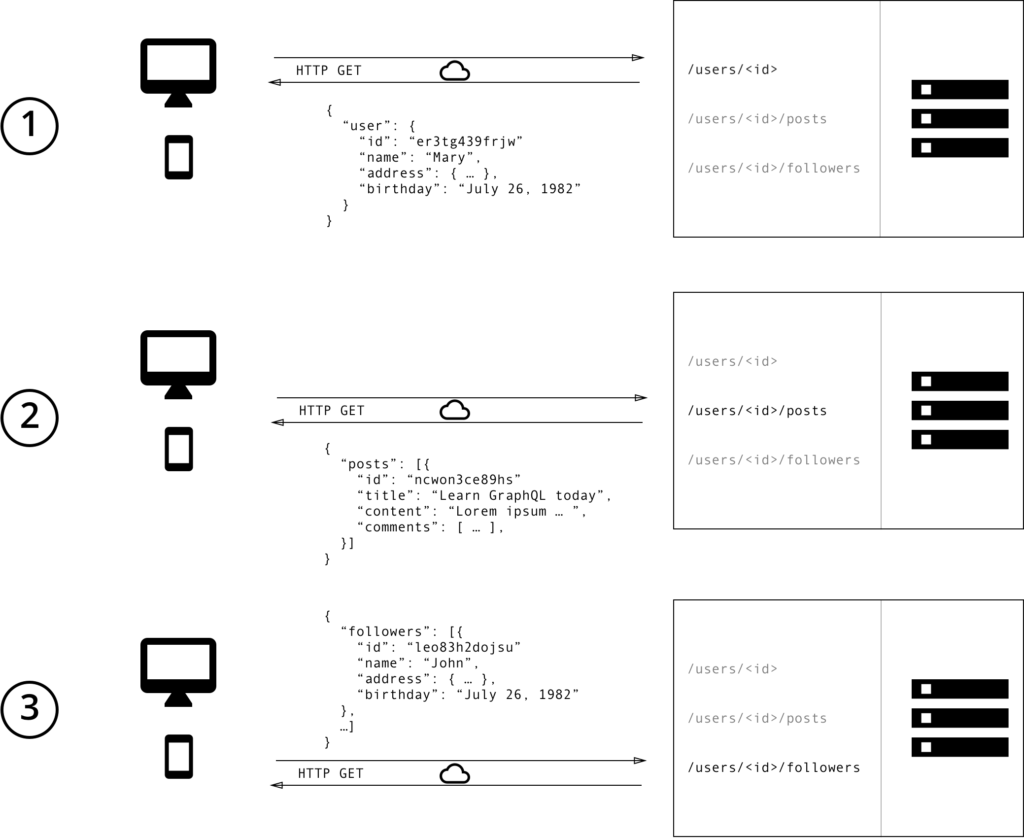
As you can see above to fetch the user’s Id and User post and followers of that particular user we have to reach multiple endpoints to get the required data and we are facing the issue of over-fetching by receiving data that we do not even need.
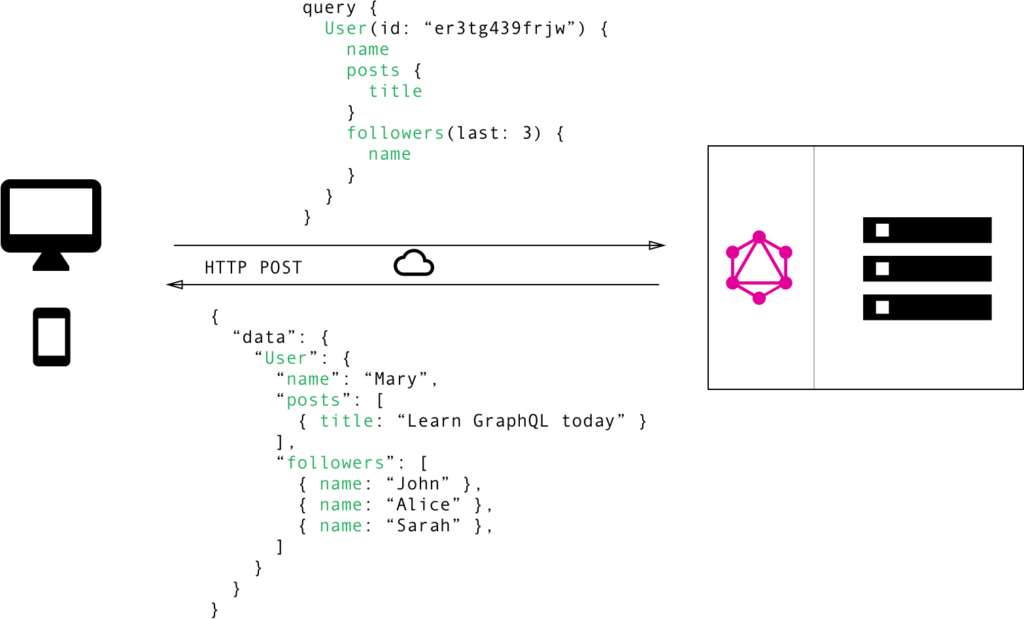
with GraphQL since it’s a single endpoint we can retrieve the exact data that we need. That is why GraphQL is very effective when fetching data. Notice that even though the structure of the data has more fields its will only return according to the query request from a client-side.
Under-Fetching:
Under-Fetching generally means that the specific endpoint didn’t provide the sufficient data that we need and again we have to reach out to more endpoints in order to get the required data.
Various Building Blocks that we should know in order to develop a GraphQL API
- Type Definitions
As I mentioned earlier it’s a strongly typed language and it is important to define the data type for each field.
- Query Types
A Query type on a schema that defines operations where clients can perform to access data that resembles the shape of the other type in schema. and it defines how clients can access data.
- Resolvers
It is a function that is responsible for returning values for fields that exist on types in a scheme. and resolvers execution depends on the incoming client query.
- Mutation Definition
A Mutation is used to Create, Delete, and Modify the data.
- Composition
It combines more than one API to compose it in a single GraphQL Umbrella.
- Schema
A schema that contains a type definition, resolvers, query definition, and mutation definition. A scheme is defined using Schema Definition Language (SDL). And programmatically creating a schema using language construct.
Where does the GraphQL Fit in :
- A GrapgQL Server With a connected DB.
- A GraphQL server as a layer in front of many 3rd party services and connect with all in one GraphQL API
- A Hybrid approach where a GraphQL server has a connected DB and also communicate with 3rd party Services
Introduction to Apollo Server
Apollo Server is an open-source tool that allows connecting with any kind of GraphQL client to develop GraphQL API. and its self-documented which means it provides basic information about schema types and fields suggestions which is very helpful while developing queries for a client including Apollo Client.
We can use Apollo Server as :
- A stand-alone GraphQL server, including in a serverless environment.
- An add-on to your application’s existing Node.js middleware most likely Express.js
- A gateway for a federated graph.
Enough for theory let’s get our hands dirty with implementing it.
Environment Setup
To create a GraphQL API with apollo server we need to install the required packages from npm follow the steps given below
After that create a javascript file and import the GrapgQL package called “graphql-tag” and “ApolloServer” from the apollo-server package. and define a typedef and the query and types. as shown below
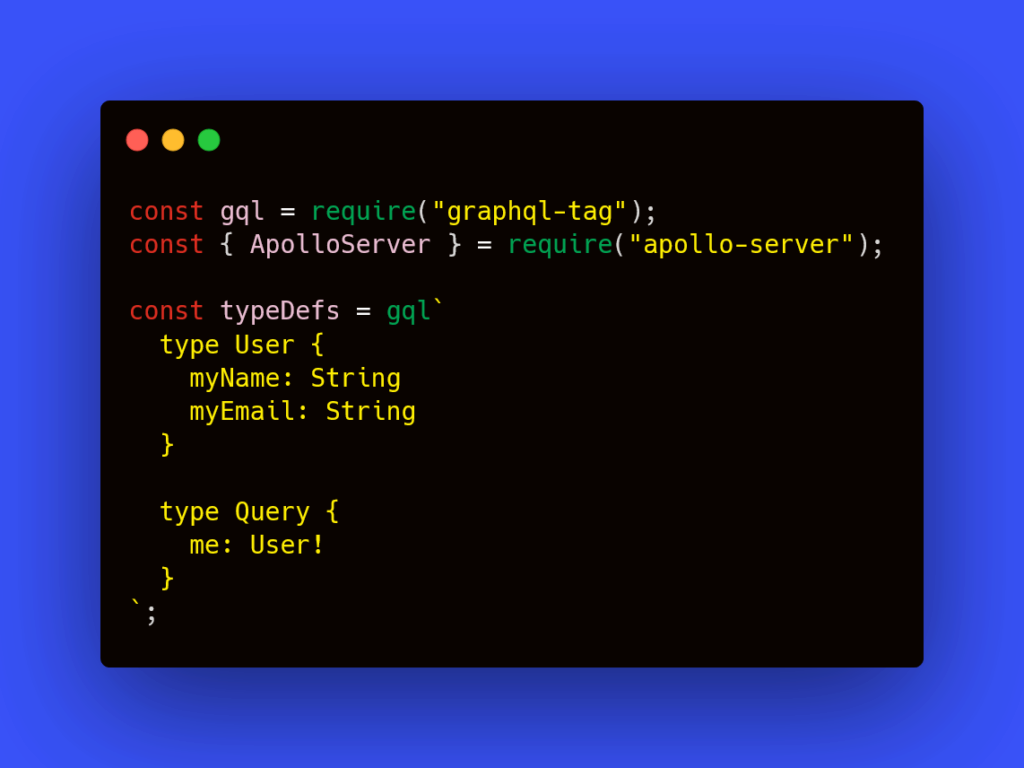
Not that all the types and queries must be enclosed within the template literals followed by the graphql-tag.
The next step is to create resolvers for the query. and the query field name should be the same as the query field name. and it should return the object of data requested from the query.
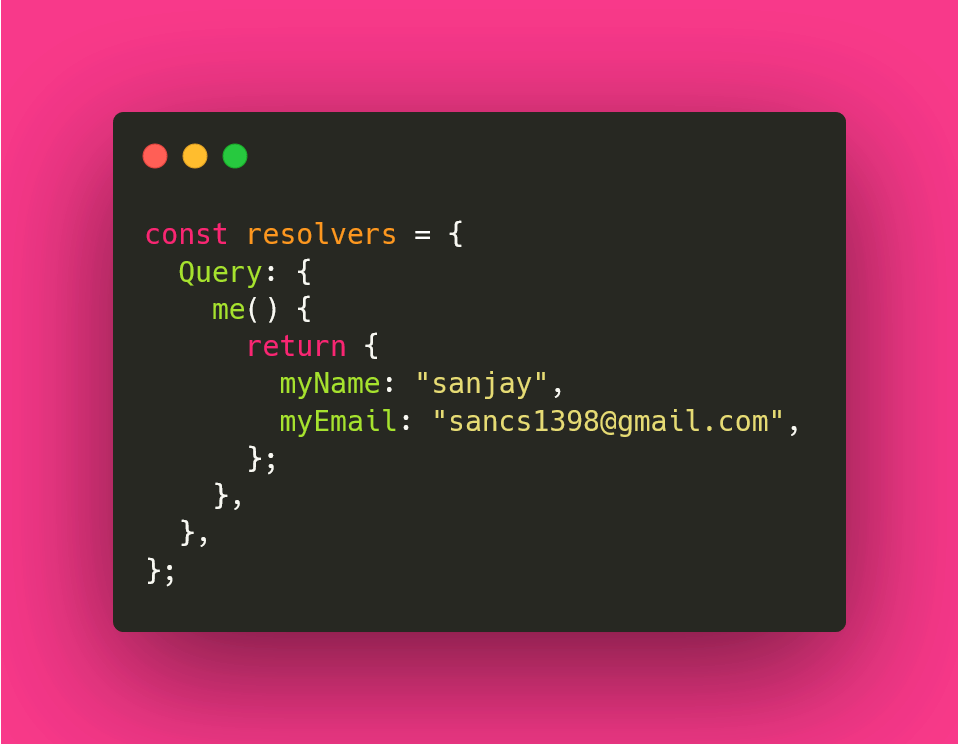
After that, we have to pass the type definition and resolver to the ApolloServer as a parameter and then provide a specific port to listen.

Now run the js file and you should see the apollo server on the browser and then we can perform the query request as a client to get a required data

once you execute it successfully you will be seeing the page as shown in the above image You should click Query your server button and then you will be redirected to the apollo server studio where you can play around with your GraphQL API.
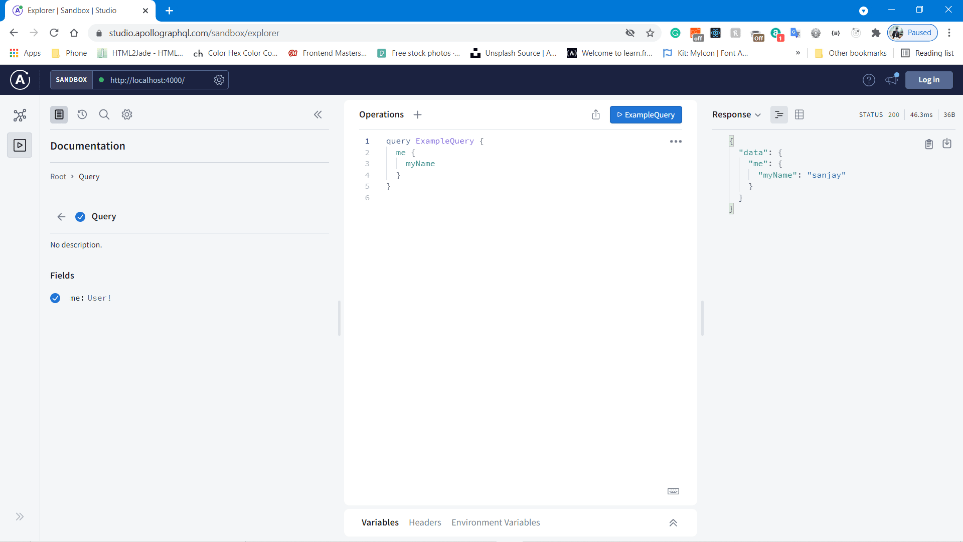
As you can see you can retrieve specific data that we need.
Reference
- Official GraphQL Site – https://graphql.org/
- Official Apollo Server – https://www.apollographql.com/docs/
- Official HowtoGraphql site – https://www.howtographql.com/
- Image source – https://imgur.com/
Introduction-
AppSync is a service provided by AWS(Amazon Web Services) that helps in creating the API using GraphQL. GraphQL is a query language developed by Facebook in 2012 and was made open-source in 2015. AppSync is fully managed by AWS and helps in developing the application at a very fast rate. AppSync helps in creating a single endpoint of GraphQL, and with the help of it, we can query databases like dynamo DB, Ethena, RedShift, RDS, Aurora, and many more. AppSync can also act as a link between the client app and the databases.
Features-
- Simplified process of creating applications using flexible API’s
- Acts as a link between the client app and DB
- Realtime subscription using GraphQL
- Offline support
- Unified secure access
- Manage Caching
- CLoud watch logs
- Lambda resolver
Why Appsync –

Time:
Half of the work regarding the back-end will be handled by AppSync which saves most of your time.
Scalable:
AppSync will scale itself according to the traffic and the number of people using it. No matter if it is a small scale application or a large scale e-commerce website
Real-Time applications:
Any change in the database is reflected across all the clients in real-time. This job can be cumbersome if you plan on coding the project yourself. Your application will inherit this splendid feature without putting extra effort into it.
Offline Access:
It syncs the app data so that all the requests and queries can be performed even when the device isn’t connected to the Internet. The changes will be reflected as soon as the device gets connected. AppSync will take care of the data conflicts.
Unified Database:
All your datasets will be under the roof of Amazon Web Services. AWS AppSync supports all the services provided by Amazon like DynamoDB, Elasticsearch, Aurora serverless, Amazon Cognito, and any other Amazon Service that you would like to implement in your application.
Security:
AppSync also allows you to define your security system for your data using multiple concurrent authentication modes.
Demo For API Creation-
- Firstly, we will go to the AWS console and then to the app sync console, where we will select create API tab.
- Now we will select build from scratch so that we can start with blank schema.
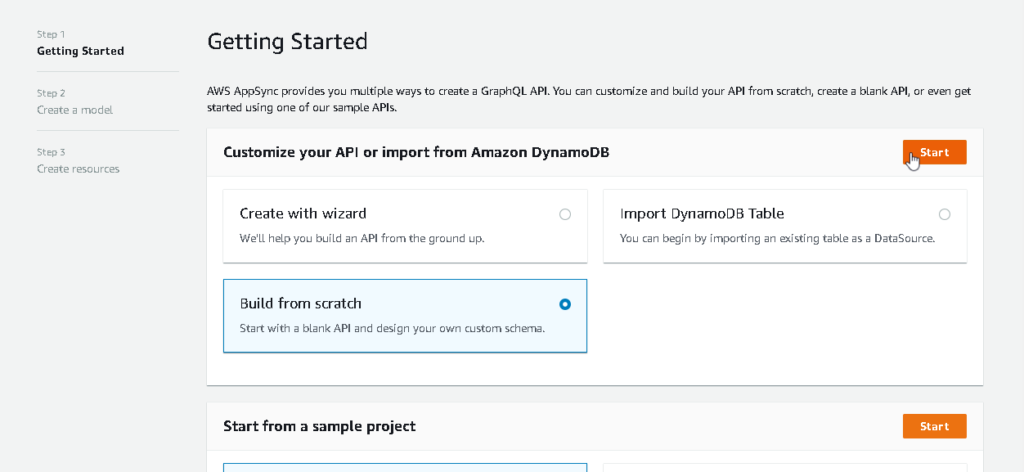
- Now it will ask you for API name, let’s give it Employee.
- After that a new tab will come that will have all the details about your API.
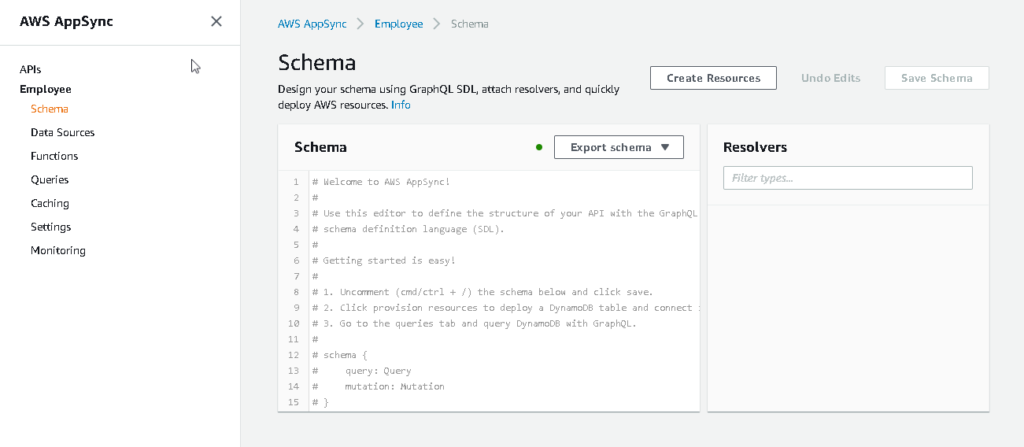
- In the settings, we can find the details like API Key, API URL, and many more.
- We can click on the schema to create our GraphQL schema, we can click on create a resource to automatically create our schema based on our resource type.
- In our example, we have created a resource of Employees and have created some fields.
- When you will do so and scroll down you will find out that 2 queries, 3mutation, and 3 subscriptions are automatically created.
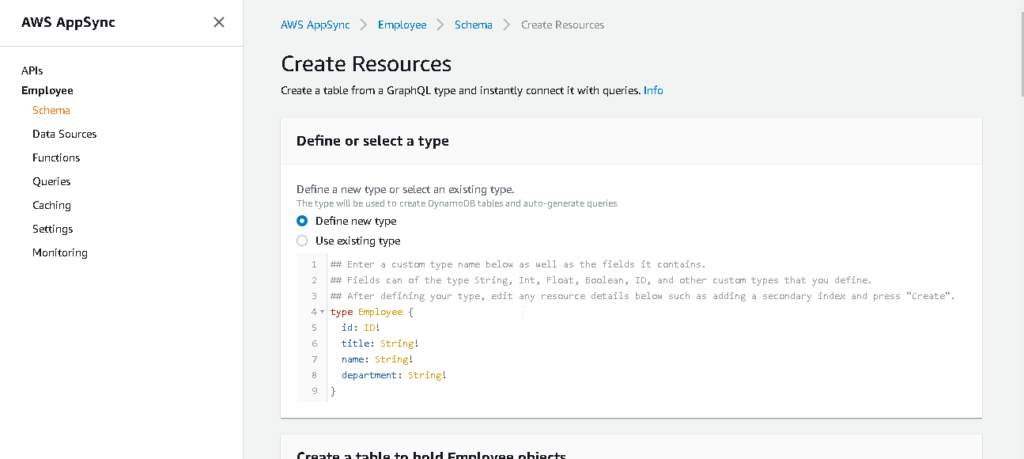
- Click on create and you will find out that a schema has been created and dynamo DB is used as a default database.
- When you will click on the resource on the left menu, you will find out that EmployeeTable has been created.
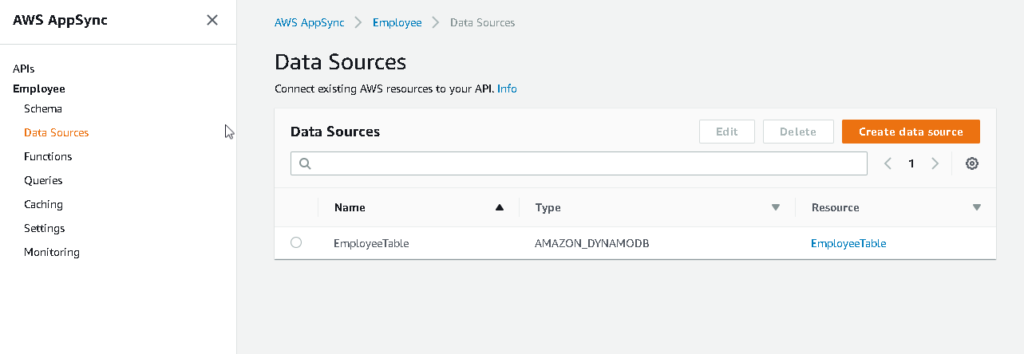
- To view the table you can click on the resource name and will find out all the details related to that resource.
Conclusion-
This is how you create an API on AppSync, You can easily integrate the API in your app using the instructions provided there only.
References-
- https://console.aws.amazon.com/appsync/home?region=us-east-1#/apis
- https://aws.amazon.com/appsync/
Still Curious? Visit my website to know more!
For more interesting Blogs Visit- Utkarsh Shukla Author
Introduction
- GraphQL is a query language developed by Facebook in 2012 and was made open-source in 2015.
- GraphQL is a server-side language for executing the queries.
- GraphQL is considered the biggest competitor for REST API’s as it improves data retrieval and boosts the fetching power.
- GraphQL enables users to get only the required dataset and no other unused data, which makes it much useful and economical compared to REST API.
Graphene
Graphene is a python library for creating GraphQL APIs in python easily and with very little code. In Graphene, we follow the code first approach as compare to the schema first approach in Apollo Server or Ariadne. Graphene can be easily integrated with popular web frames such as Django, Flask and bottle, so it makes it very easy to integrate GraphQL with all these frameworks.
Demo
Requirements-
- Python>=3
- Grapghene>-2.0
Steps
- Install requirements, for graphene =>. pip/pip3 install graphene==2.0
- Create a class Query that will inherit from graphene
- Define two parameters book_name and book_author with both of type string, remember to use grapghene data types only
- Create a resolver for both of them so that they can be fetched while calling the query

- Resolvers are created for every field that can be query, every field has its resolver or we can say that every field lie in a resolver whenever a particular field is passed in a query, the resolver of that particular field is called.
- Create a schema that is by using graphene, we can directly use graphene.Schema and can pass Query inside it.
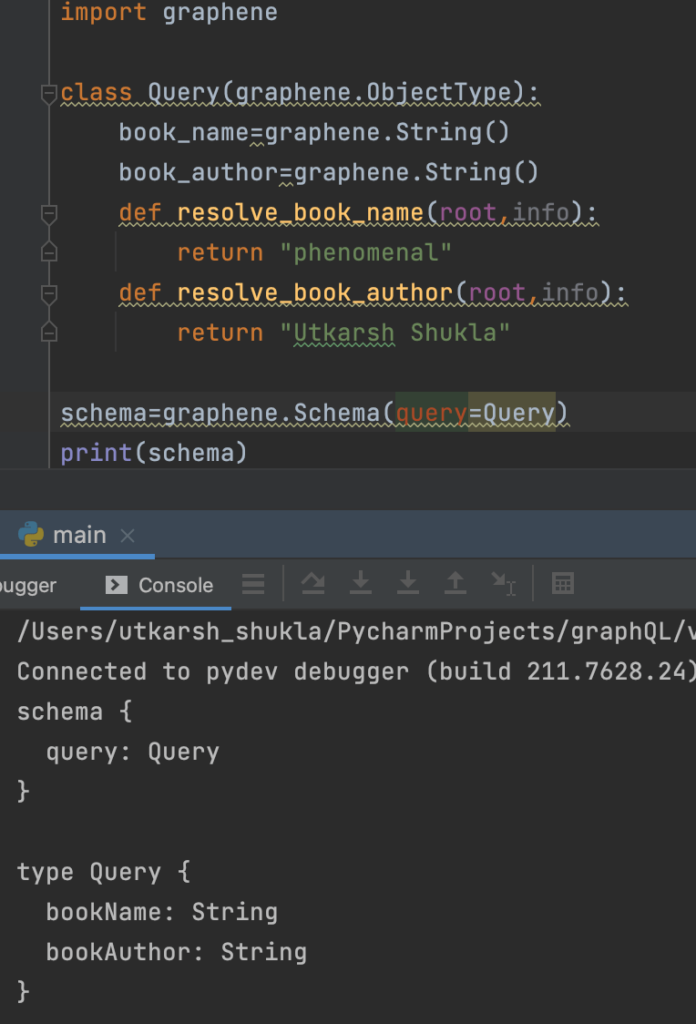
- In case of scehma it will always be camelCasing by default so you need to change it if you want it to be of any other type. auto_camelcase is the keyword to that
- Now we can simply write our query and execute it, to see the result.
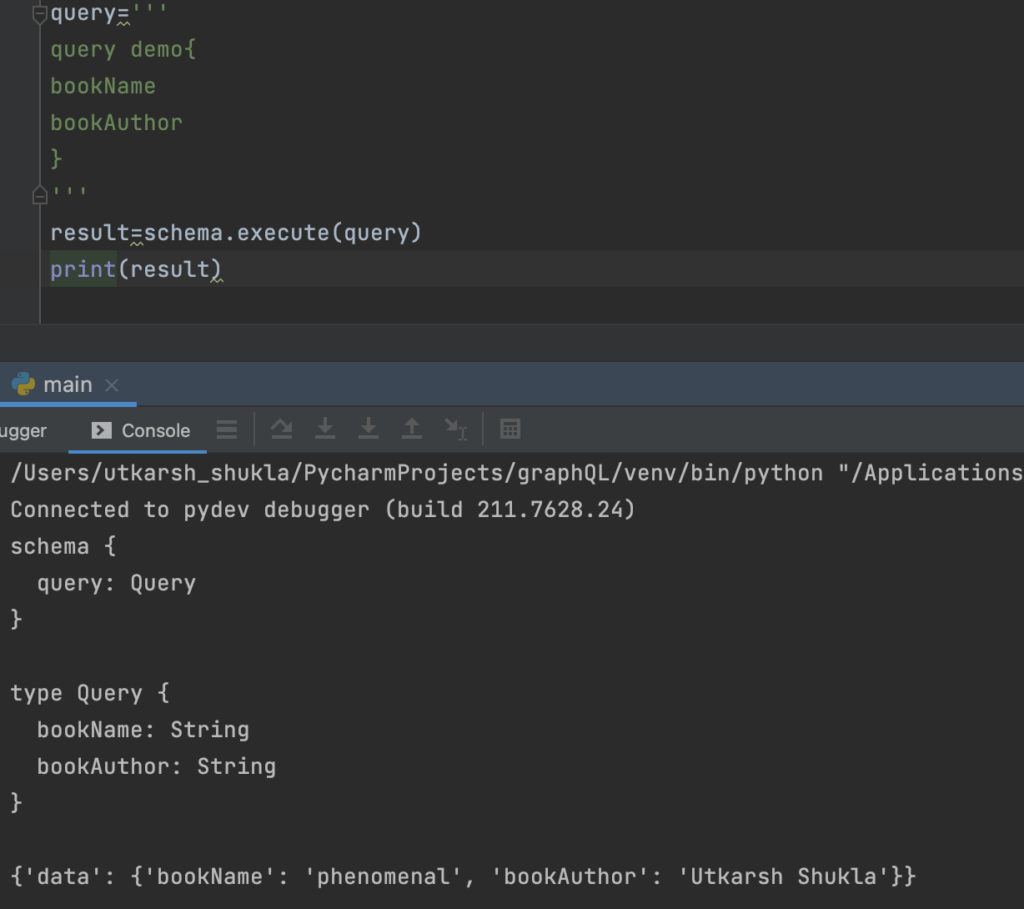
- Here it is our first GraphQL query has been executed.
- To change the name of response or have only specific parameters we need to only change the query nothing else.
- Backend can be maded fix by this and we need to only change the query from the frontend to play with the response.
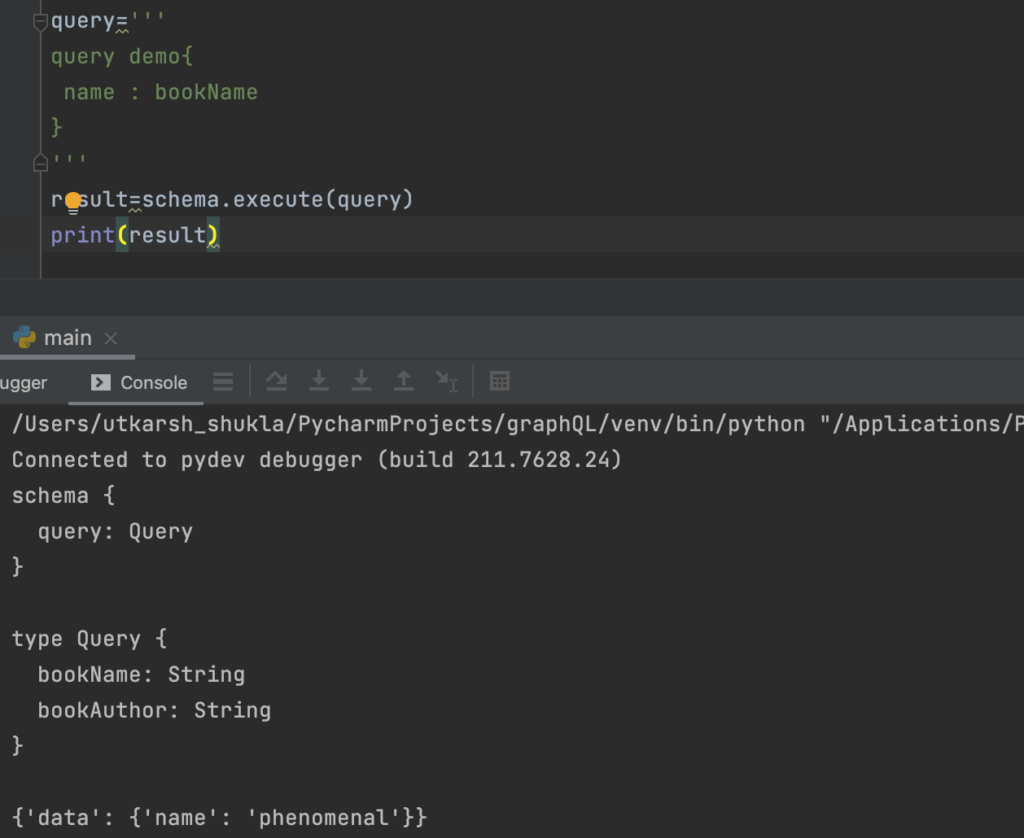
So that’s it from the first part, I will be adding more blogs on this series and in the next part we will talk about mutations that is the CRUD operations in GraphQL.
References-
- https://graphql.org/
- https://docs.graphene-python.org/
Still Curious? Visit my website to know more!
For more interesting Blogs Visit- Utkarsh Shukla Author