GraphQL is not just a query language, it’s a paradigm shift in how we think about APIs and data management
Introduction
So back in 2012, Facebook was having trouble with their mobile app. It was slow and didn’t work well on weak internet connections. They were using a type of technology called REST API, but it wasn’t working well for them.
So they came up with a new idea called GraphQL. It’s a special way of asking for information from a server. Instead of getting a bunch of information all at once, GraphQL lets the app ask for only the specific information it needs at that moment. This makes the app faster and more efficient, especially on weak internet connections.
Think of it like asking a waiter for your order at a restaurant. Instead of getting a whole menu, you can just ask for the specific food you want to eat right now. This way, you don’t waste time looking at things you don’t want, and the waiter can bring you your food faster!

here is another example :
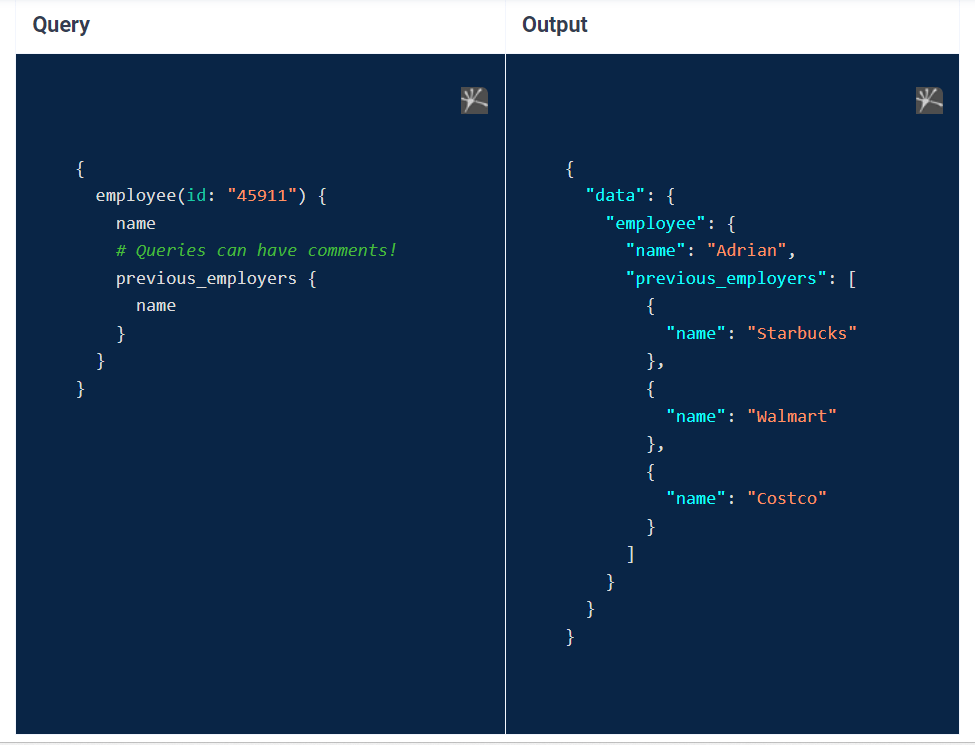
As you can see, the above query and the result have the same form. Using GraphQL queries enables the server to know what the client has asked for. It also returns only the fields specifically requested.
How does GraphQL work?
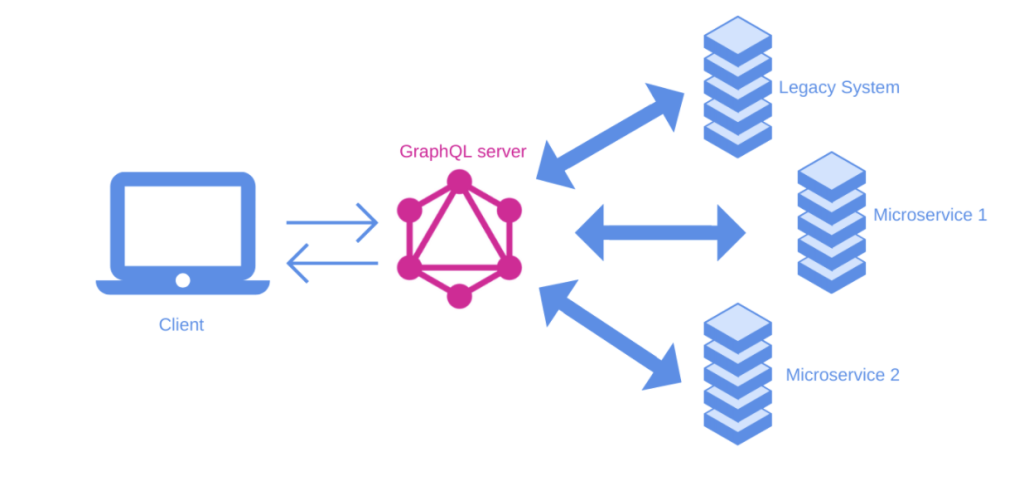
With GraphQL, you don’t need to know all the technical details about how the different sources work or where the data is stored. You just tell GraphQL what you want, and it figures out how to get it for you.
To help make this process easier, GraphQL uses something called Schema Definition Language (SDL). SDL is like a map that tells GraphQL where to find the information you want. By using SDL, GraphQL knows exactly what you’re looking for and can give you just the data you need, making your app faster and more efficient.
Why is GraphQL replacing Rest API ?
Improved efficiency
Increased Efficiency: With REST APIs, clients receive all the data defined by the server, even if they don’t need all of it. In contrast, GraphQL allows clients to request only the data they need, making the application more efficient and reducing the amount of data transferred over the network.
Reduced over-fetching and under-fetching
By specifying exactly what data is needed, GraphQL reduces the problem of over-fetching (receiving more data than necessary) and under-fetching (not receiving enough data to fully populate the client).
Increased flexibility
With GraphQL, clients can request multiple resources in a single request, and the server can respond with the exact data the client needs, regardless of where it is stored.
Better developer experience
The GraphQL API is strongly typed, meaning that developers can easily understand and interact with the API using tools like GraphQL playgrounds and code editors.
Simplified versioning
Because clients can specify the exact data they need, changes to the API schema can be made without breaking existing clients.
A built in playground/UI to explore and invoke the API
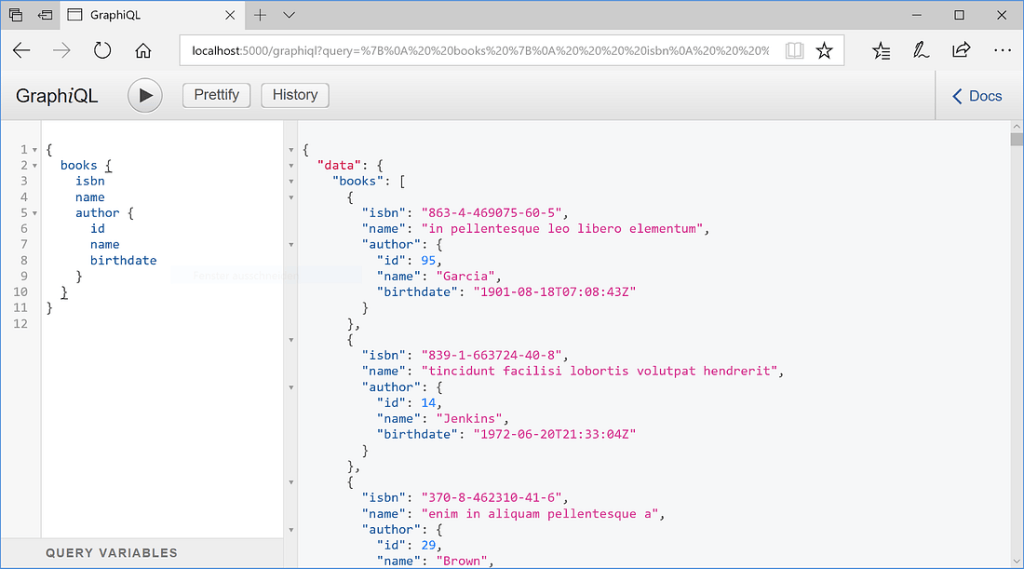
As you can see above even before designing and implementing their user interfaces, front-end engineers can explore and test the backend APIs they need using this interface: A very powerful collaboration mechanism for the team.
| Feature | REST | GRAPHQL |
| Querying data | URL-based queries and parameters | Schema-based queries and fields |
| Response format | Pre-defined data structures | Dynamic response based on query |
| Request flexibility | Limited to pre-defined endpoints | Flexible, can request any data |
| Over-fetching | Can return more data than needed | Requests only needed data |
| Under-fetching | May require multiple requests | Can retrieve multiple resources |
| Versioning | May require versioning of endpoints | Can add fields without breaking clients |
| Client-side complexity | May require multiple API calls and data filtering | Can simplify client requests and data retrieval |
| Caching | Can be easily cached using HTTP caching | Requires a custom caching layer |
| Real-time updates | Requires polling or WebSockets | Supports real-time updates via subscriptions |
Overall, GraphQL can help reduce complexity and improve efficiency in building and consuming APIs, making it a powerful tool for modern application development.
Conclusion
In conclusion, GraphQL is a query language and runtime API that has gained popularity in recent years due to its advantages over traditional REST APIs.
As a result, GraphQL has become a preferred method for building APIs, especially for applications with complex data requirements, mobile applications, and microservices architectures. While REST APIs are still widely used, it’s clear that GraphQL offers a more flexible, efficient, and developer-friendly alternative that is quickly gaining traction in the software development community.
Here are some links to help you getting started and get a deeper insight on GraphQl
https://graphql.org/learn/ (Official documentation)
https://www.howtographql.com/basics/1-graphql-is-the-better-rest/ (Deeper dive on tooling, environment, security etc Frontend/backend)
React Query vs SWR: The basics
In the world of front-end development, there are a lot of debates around different technologies and how they should be used. One such debate is around data fetching libraries for React. The two most popular options are React Query and SWR. Both React Query and SWR are libraries that were created to help with data fetching in React applications. React Query is a library for fetching, caching, and managing data in React applications. It includes features like query caching, deduplication, request cancellation, and pagination. React Query is heavily inspired by Relay and Apollo Client. SWR is a library for efficiently fetching data from an API. It includes features like caching, deduplication, and pagination. SWR is heavily inspired by various Reddit clients (like Apollo).
So what’s the difference between these two libraries? Let’s take a closer look…
Caching:
Both React Query and SWR support caching out of the box. However, where they differ is in the granularity of their caching implementations. React Query lets you fine-tune your caching so that you can cache at the component level, whereas with SWR you cache at the route level. This means that if you’re using SWR and you have a page with multiple routes, each route will have its own separate cache. This can lead to duplicated requests if you’re not careful.
Deduplication:
React Query and SWR both support deduplication out of the box. Deduplication ensures that if you make the same request multiple times, only a single network request will be made. This can be useful if you have a component that makes multiple requests on mount (for example, if it fetches data from multiple API endpoints). By default, both libraries will use a short time window (5 seconds for React Query and 1 second for SWR) to deduplicate requests.
Request Cancellation:
React Query supports request cancellation out of the box. This means that if you make a request and then unmount the component before the response comes back, React Query will automatically cancel the request so that you don’t end up with stale data in your UI. With SWR, there is no built-in support for request cancellation—however, there is an open issue for it on GitHub.
Pagination:
Both React Query and SWR support pagination out of the box. They each have their own APIs for pagination which are very similar. The main difference is that with React Query you need to specify which page of results you want when making your initial query (for example, page 1 or page 2), whereas with SWR there is an API for automatically fetching the next page of results when necessary.
React Query vs SWR: Features
One of the biggest differences between React Query and SWR is the features each library offers. React Query provides features like automatic retries, refetch on interval, caching/suspense integration, cancelation tokens, global state management, SSR support, and more. SWR, on the other hand, focuses mainly on providing hooks for remote data fetching. While it does offer some caching features, they are not as robust as those offered by React Query.
React Query vs SWR:Performance
When it comes to performance, both React Query and SWR are fast and effective at fetching data from APIs. However, where they differ is in how they handle re-rendering components. With React Query, components will only re-render when the data that they need has been fetched (or if an error has occurred). With SWR, components will always re-render when new data is fetched from the API— even if the component doesn’t need to use that data. This can lead to unnecessary re-renders and lower performance in some cases.
React query vs SWR: Ease of use
When it comes to ease of use, there is a slight learning curve with both libraries. However, once you get familiar with the basics of each library they are both fairly easy to use. In terms of documentation, React query has more comprehensive documentation than does SRW. docsthat walks you through all of the steps necessary to get started with the library. On the other hand, while SRW’s documentation is not as comprehensive as that of React query , it does provide helpful examples that can be used to get started with the library quickly . At the end of the day , both libraries are easy enough to use once you get familiar with them . However , React query’s comprehensive documentation may make it slightly easier for newcomers to get started . Whichever librarie you choose to proceed with, making sure you refer to the official documentation frequently is key so that you don’t run into any issues.
React Query vs SWR: The Pros and Cons
React Query:
-Pros:
- Developed by the same team that created React Apollo (another popular data fetching library), so it has a lot of pedigree behind it.
- integrates really well with React suspense/concurrent mode (new feature in React that allows components to “suspend” rendering until certain conditions are met). This can give your app a major performance boost.
- includes features like caching and error handling out of the box, which means less code for you to have to write yourself.
-Cons:
- doesn’t have as many features as some of the other options out there (like SWR).
- because it’s newer, there isn’t as much documentation available yet.
SWR:
-Pros:
- has more features than React Query (like polling and pagination).
- better documentation thanks to its longer tenure in the open source world.
- integrates well with existing APIs (like REST).
-Cons:
- not as performant as React Query due to its reliance on virtual DOM diffing (a process where the differences between two DOMs are calculated so that only the changed parts need to be re-rendered).
- trying to use suspense/concurrent mode with SWR can lead to unpredictable results (though this may change in future versions as they continue to work on integrating those features).
How to Use React Query?
Installation:
Using React Query is relatively simple. First, you need to install it into your project using either NPM or Yarn. Then, you can create a new instance of ReactQuery in your component:

Requirements:
React Query is optimized for modern browsers. It is compatible with the following browsers config

Code Example:
This code snippet very briefly illustrates the 3 core concepts of React Query:

How to use SWR?
Installation:
Inside your React project directory, run the following:

Code Example:
For normal RESTful APIs with JSON data, first you need to create a fetcher function, which is just a wrapper of the native fetch:

Then you can import useSWR and start using it inside any function components:

Conclusion:
In conclusion, there are two popular libraries for data fetching in React: React Query and SWR. They take different approaches to data fetching, but both libraries include features like caching, deduplication, and pagination out of the box. So which one should you use? It depends on your project requirements. If you need fine-tuned control over your caching implementation or if you need built-in support for request cancellation, then React Query might be a better fit for your project. However, if you’re looking for a simpler API or automatic pagination support, then SWR might be a better choice.
Reference:
- https://swr.vercel.app/
- https://tanstack.com/query/v4/?from=reactQueryV3&original=https://react-query-v3.tanstack.com/
What is GraphQL
A Spec that describes a declarative query language that your client can use to ask an API for the exact data they need. and it’s done by creating a strongly typed schema for your API.
It provides ultimate flexibility in how your API can resolve data and client queries validated against your schema.
The Problems that are solved by GraphQL for An API Developer at the Server Side Are :
The GraphQL Solving the following problems :
- Over-Fetching
- Under-Fetching
What Is Over-Fetching :
In REST API unlike GraphQL We have to pass the GET request to multiple endpoints to get the data that we need. and it’s a fixed data structure that returns more files of data than the data that we exactly need.
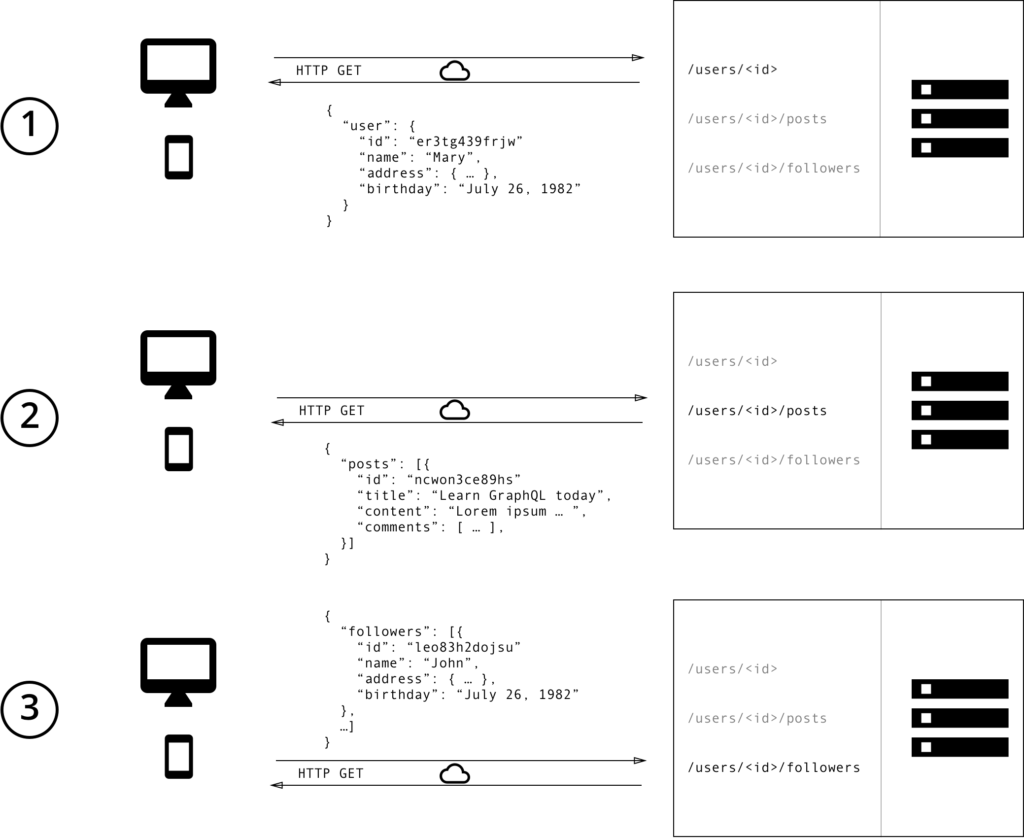
As you can see above to fetch the user’s Id and User post and followers of that particular user we have to reach multiple endpoints to get the required data and we are facing the issue of over-fetching by receiving data that we do not even need.
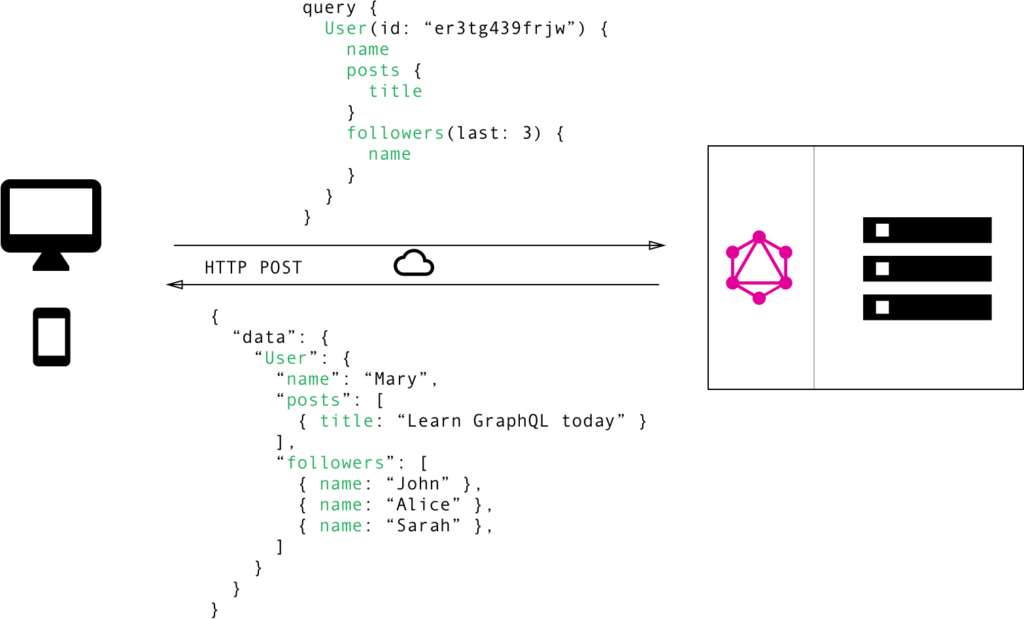
with GraphQL since it’s a single endpoint we can retrieve the exact data that we need. That is why GraphQL is very effective when fetching data. Notice that even though the structure of the data has more fields its will only return according to the query request from a client-side.
Under-Fetching:
Under-Fetching generally means that the specific endpoint didn’t provide the sufficient data that we need and again we have to reach out to more endpoints in order to get the required data.
Various Building Blocks that we should know in order to develop a GraphQL API
- Type Definitions
As I mentioned earlier it’s a strongly typed language and it is important to define the data type for each field.
- Query Types
A Query type on a schema that defines operations where clients can perform to access data that resembles the shape of the other type in schema. and it defines how clients can access data.
- Resolvers
It is a function that is responsible for returning values for fields that exist on types in a scheme. and resolvers execution depends on the incoming client query.
- Mutation Definition
A Mutation is used to Create, Delete, and Modify the data.
- Composition
It combines more than one API to compose it in a single GraphQL Umbrella.
- Schema
A schema that contains a type definition, resolvers, query definition, and mutation definition. A scheme is defined using Schema Definition Language (SDL). And programmatically creating a schema using language construct.
Where does the GraphQL Fit in :
- A GrapgQL Server With a connected DB.
- A GraphQL server as a layer in front of many 3rd party services and connect with all in one GraphQL API
- A Hybrid approach where a GraphQL server has a connected DB and also communicate with 3rd party Services
Introduction to Apollo Server
Apollo Server is an open-source tool that allows connecting with any kind of GraphQL client to develop GraphQL API. and its self-documented which means it provides basic information about schema types and fields suggestions which is very helpful while developing queries for a client including Apollo Client.
We can use Apollo Server as :
- A stand-alone GraphQL server, including in a serverless environment.
- An add-on to your application’s existing Node.js middleware most likely Express.js
- A gateway for a federated graph.
Enough for theory let’s get our hands dirty with implementing it.
Environment Setup
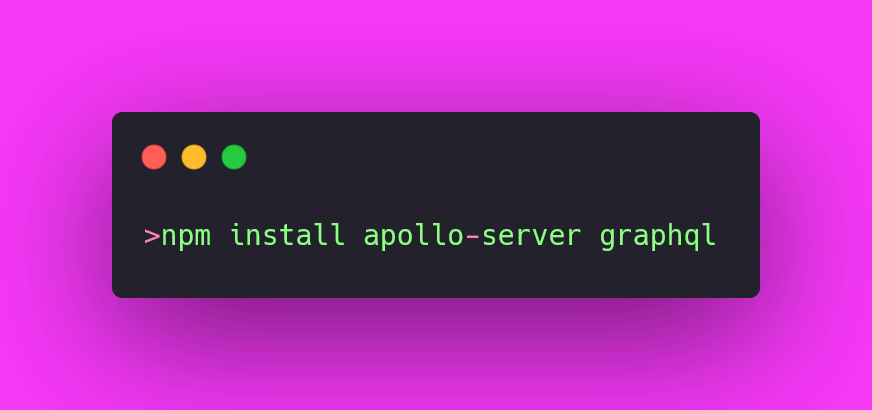
To create a GraphQL API with apollo server we need to install the required packages from npm follow the steps given below
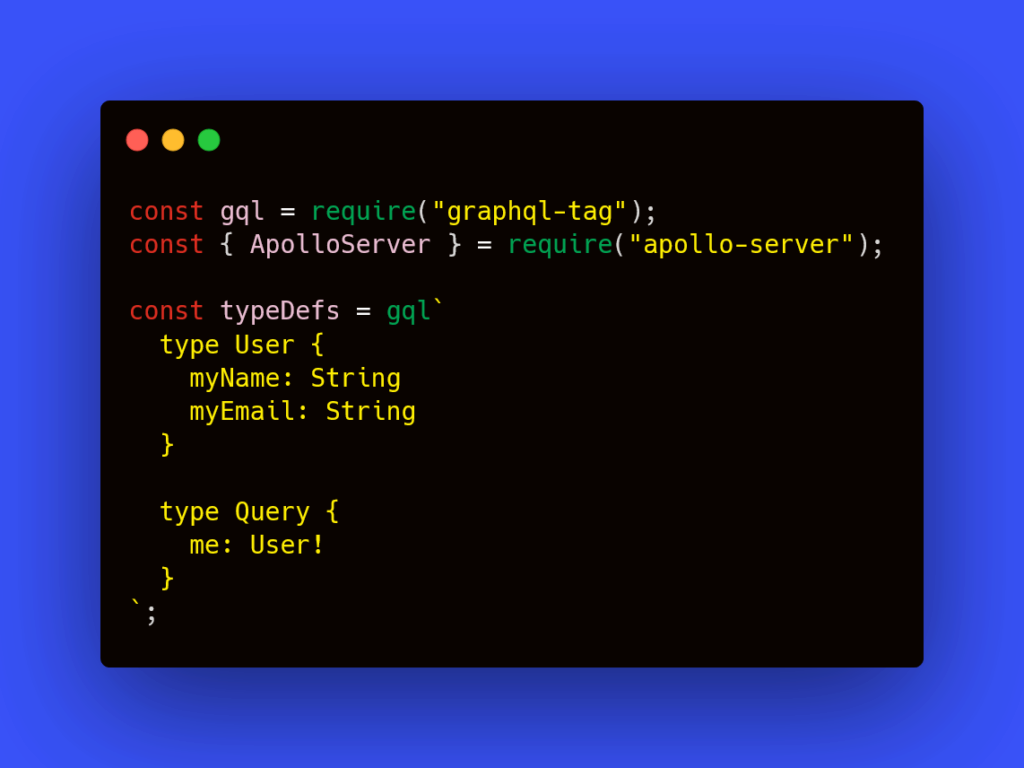
After that create a javascript file and import the GrapgQL package called “graphql-tag” and “ApolloServer” from the apollo-server package. and define a typedef and the query and types. as shown below
Not that all the types and queries must be enclosed within the template literals followed by the graphql-tag.
The next step is to create resolvers for the query. and the query field name should be the same as the query field name. and it should return the object of data requested from the query.
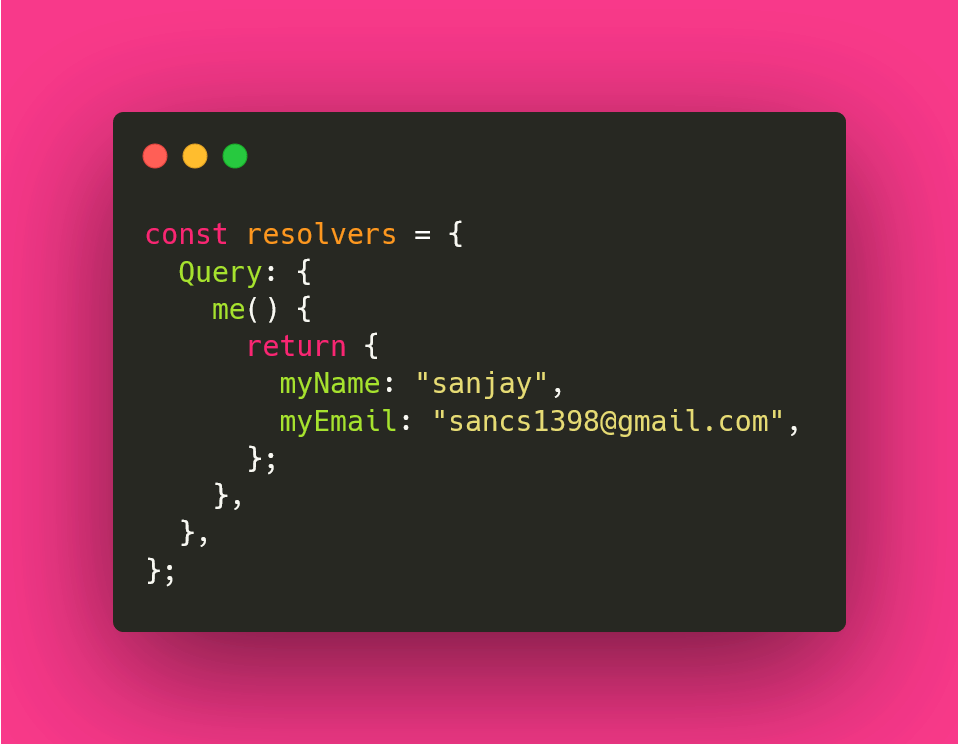
After that, we have to pass the type definition and resolver to the ApolloServer as a parameter and then provide a specific port to listen.

Now run the js file and you should see the apollo server on the browser and then we can perform the query request as a client to get a required data

once you execute it successfully you will be seeing the page as shown in the above image You should click Query your server button and then you will be redirected to the apollo server studio where you can play around with your GraphQL API.
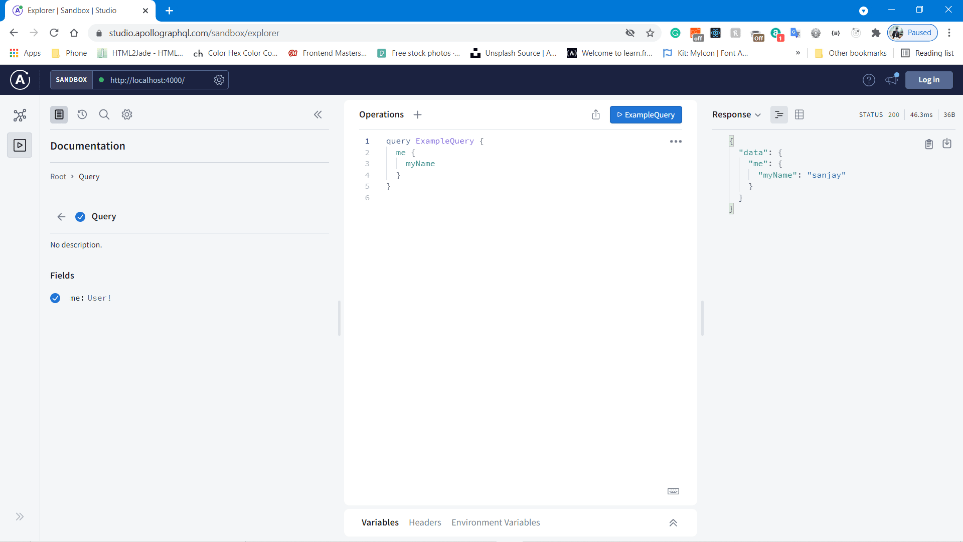
As you can see you can retrieve specific data that we need.
Reference
- Official GraphQL Site – https://graphql.org/
- Official Apollo Server – https://www.apollographql.com/docs/
- Official HowtoGraphql site – https://www.howtographql.com/
- Image source – https://imgur.com/